Séries temporais representam uma fatia importante do campo do Data Science, e envolvem problemas como previsão de demanda, vendas e até mesmo o mercado financeiro.
Já parou para pensar na dificuldade de interpretar gráficos ou números que têm sazonalidade, ou seja, que não seguem o mesmo padrão ao longo do ano?
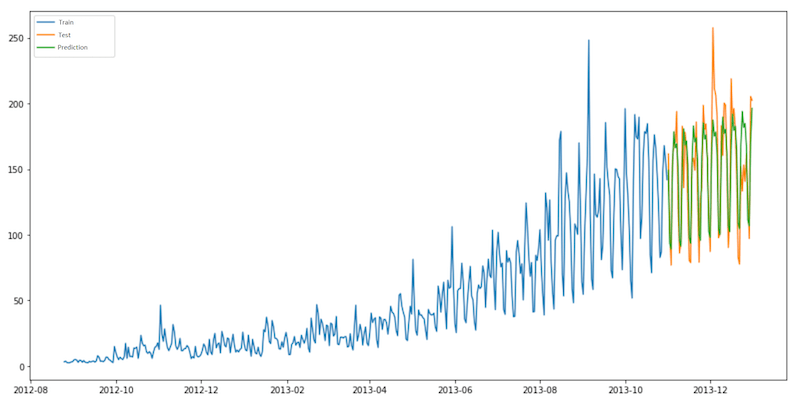
Uma loja de varejo vai vender muito mais no natal do que no carnaval, isso é intuitivo para nós. Mas como identificar esse comportamento em gráficos? Como fazer uma previsão com isso?
Se você nunca escutou falar no termo séries temporais (ou time series, do inglês), hoje farei uma breve introdução sobre o tema usando Python.
O que são Séries Temporais?
Séries temporais são uma séries de observações registradas em intervalos de tempo regulares.

Registrar o tempo faz parte da atividade humana há milênios. Seja para planejar, criar cronogramas ou organizar eventos, estamos muito acostumados a trabalhar no presente, considerando o passado, para “prever” o futuro.
Normalmente, se usa o conceito de séries temporais para:
- Identificar a natureza do fenômeno representado pela sequência de observações para encontrar padrões de comportamentos; e
- Usar modelos estatísticos para prever valores futuros, baseando-se em resultados do passado.
Como exemplos de fenômenos que podem ser acompanhados e registrados ao longo do tempo estão:
- Movimentação do preço de ações na Bolsa de Valores.
- Tamanho da população de uma cidade, estado ou país.
- Vendas trimestrais de uma loja de varejo no segmento da moda.
- Consumo de energia elétrica de um condomínio de casas.
- Demanda de passageiros de uma companhia aérea ao longo do ano.
Componentes de uma Série Temporal
Uma série temporal não pode utilizar técnicas tradicionais diretamente. Imagine que ao aplicar diretamente um modelo de regressão a uma séries, você ignora completamente a dimensão tempo.
Por isso, antes mesmo de explorar um gráfico temporal, é necessário conhecer 2 componentes básicos das time series.
Tendência
Tendência é a direção geral de alguma coisa que está se desenvolvendo ou evoluindo no eixo do tempo.
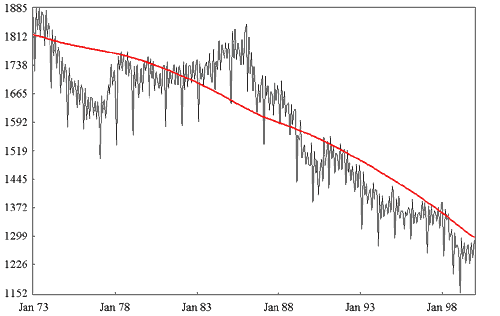
No gráfico acima, você pode ver que existe uma tendência de queda nas vendas do uma empresa, mesmo com oscilações ao longo dos anos.
Plotar uma reta sobre esse gráfico ajuda a identificar rapidamente essa tendência.
Sazonalidade
Sazonalidade é qualquer mudança ou padrão previsível em uma série temporal.
Essa oscilação pode ser recorrente ou se repetir ao longo de um determinado período de tempo. Dependendo o ruído nos dados obtidos, também é facilmente detectada em gráficos como esse abaixo.
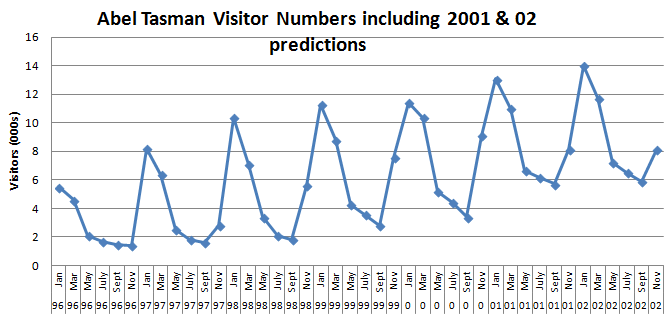
O gráfico do número de visitantes do Parque Nacional Abel Tasman (Nova Zelândia) permite identificar que há um pico entre os meses de dezembro e janeiro.
Também conseguimos identificar que setembro é o mês mais tranquilo, com menor número de visitantes.
Como separar os componentes?
Até agora, identificamos os dois componentes no olho. Porém, isso não me parece muito científico.
Existem métodos matemáticos para fazer essa separação, considerando a natureza aditiva ou multiplicativa de um gráfico. Vou te mostrar como separar a tendência e sazonalidade usando o Python.
# importar pacotes e setar configurações de plots
import pandas as pd
from statsmodels.tsa.seasonal import seasonal_decompose
import matplotlib.pyplot as plt
import seaborn as sns
# url do dataset
dataset_path = "https://raw.githubusercontent.com/carlosfab/escola-data-science/master/datasets/electricity_consumption/Electric_Production.csv"
# importar o csv para um dataframe
df = pd.read_csv(dataset_path)
# ver as 5 primeiras entradas
df.head()Acima, importei algumas bibliotecas, incluindo o pacote estatístico statsmodels.
Também importei um conjunto de dados que mostra a produção de energia elétrica ao longo de alguns anos. Vamos plotar os dados e ver o seu comportamento.
# plotar gráfico de consumo de eletricidade
plt.plot(df.index, df.Value);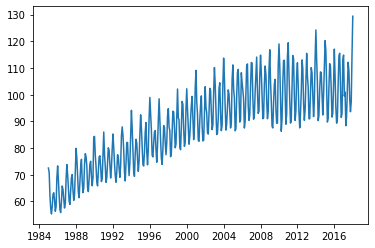
Podemos identificar uma tendência de crescimento na produção de energia elétrica, assim como ver um padrão de topos e fundos (oscilações).
Usando seasonal_decompose é possível gerar gráficos individuais, que servirão de insumo para uma fase de análise exploratória.
# salvar a decomposicao em result result = seasonal_decompose(df) # plotar os 4 gráficos fig, (ax1,ax2,ax3, ax4) = plt.subplots(4,1, figsize=(12,8)) result.observed.plot(ax=ax1) result.trend.plot(ax=ax2) result.seasonal.plot(ax=ax3) result.resid.plot(ax=ax4) plt.tight_layout()
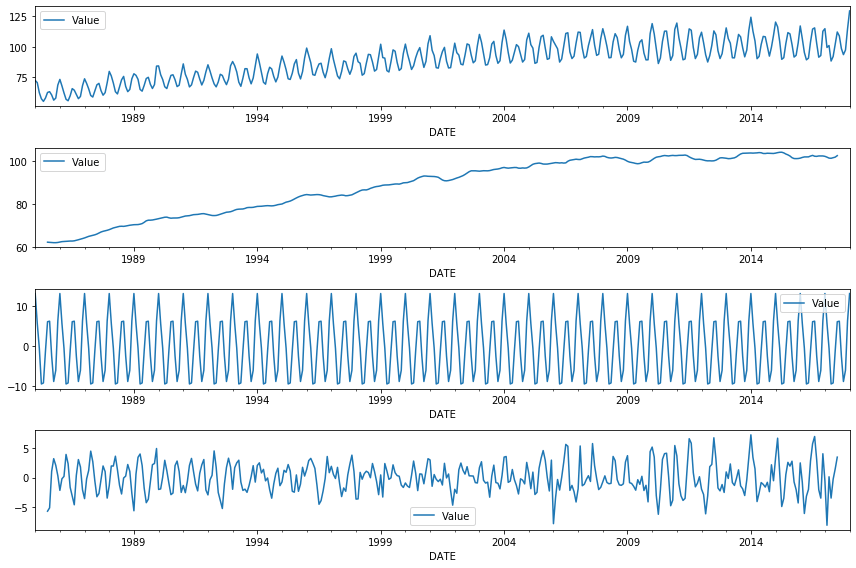
A função que usamos conseguiu decompor o gráfico em 4. Veja como ficou muito mais fácil ver cada um desses componentes separadamente.
Os plots gerados pela biblioteca statsmodels foram:
- Observação original
- Tendência
- Sazonalidade
- Residual
A oscilação (colocada horizontalmente) foi separada da tendência. Aquilo que não pôde ser identificado ou separado da observação original é o ruído, chamado aqui de residual.
Técnicas tradicionais e Séries Temporais
Agora que você aprendeu o que são elas, tenho certeza que vai passar a olhar de outra maneira para os seus dados.
Sempre raciocine se o tempo interfere de alguma maneira nas suas variáveis. Caso a resposta seja sim, não adianta tentar aplicar técnicas tradicionais para fazer previsões.
Aprenda a fazer esse tipo de exploração e conhecer modelos e frameworks específicos para as séries.
No meu próximo artigo, irei te mostrar como fazer previsões em cima de time series 🙂




















Olá Carlos, primeiramente sou um grande apreciador do seu conteúdo, parabéns! Segundo, quando executamos seasonal_decompose() pode gerar um erro segundo as normativas de numpy/pandas.
Uma forma de corrigir é:
my_pandas_series = pd.Series(df.Value)
result = seasonal_decompose(my_pandas_series.values, freq=3)
Abraço!
Estou recebendo este erro: ValueError: could not convert string to float: ’01-01-2018′
Muito bom seu artigo, estou estudando e ele me foi bem útil.
Quero apenas contribuir com uma correção:
Quando fui testar sua solução, importei o dataset para um dataframe mas seu índice não ficou como datetime.
Foi então necessário converter a coluna DATE para o index:
df[‘DATE’] = pd.to_datetime(df[‘DATE’])#, dayfirst=True)
df.set_index(‘DATE’, inplace=True)
Apenas isso.
Abraços
Excelente conteúdo!
Não é fácil achar um conteúdo didático sobre statcmodels.tsa por aí e você fez com maestria!
Consegui explorar bem melhor meus dados com este conteúdo, muito obrigado.
Muito obrigado pelo comentário!