Todos os anos, mais de 12 mil pessoas tiram suas próprias vidas no Brasil. Em um cenário mundial, esse número ultrapassa 1 milhão de pessoas, levando o suicídio a ser considerado um problema de saúde pública.
Para você ter uma noção da dimensão desses números, saiba que o suicídio tem uma taxa maior do que vítimas de AIDS e da maioria dos tipos de câncer. Segundo a Organização Mundial da Saúde (OMS), o Brasil ocupa o oitavo lugar no número de suicídios no mundo: São 32 brasileiros por dia.
Setembro Amarelo é uma iniciativa da Associação Brasileira de Psiquiatria (ABP), em parceria com o Conselho Federal de Medicina (CFM), para divulgar e alertar a população sobre o problema.

Oficialmente, o Dia Mundial de Prevenção ao Suicídio ocorre no dia 10 de setembro, porém durante o mês inteiro são promovidos debates, campanhas e ações para a conscientização sobre o suicídio.

O que trago neste artigo é muito mais que apenas um artigo de Ciência de Dados. É uma pequena contribuição que visa ajudar a entender a extensão desse problema no Brasil, além de incentivar o Setembro Amarelo dentro da comunidade Python e Data Science.
Para você acompanhar o código, disponibilizei o Jupyter notebook completo, com todas as etapas. Clique no botão abaixo para acessar.

Descrição dos dados sobre suicídio
O melhor conjunto de dados – que eu encontrei na internet – está hospedado nesta página e traz informações sobre vários países. O dataset contempla o período entre os anos de 1985 e 2016.

Esse dataset, na verdade, é um compilado de outros 4 datasets. A pessoa que disponibilizou o mesmo fez um grande trabalho de limpeza e padronização. Caso você deseje saber e tenha interesse em conhecer as fontes que deram origem a este único arquivo, são elas:
- United Nations Development Program. (2018). Human development index – HDI.
- World Bank. (2018). World development indicators: GDP (current US$) by country:1985 to 2016.
- Suicide in the Twenty-First Century (Szamil, 2017).
- World Health Organization. (2018). Suicide prevention.
Dicionário de Variáveis
O arquivo csv importado possui 12 colunas, provenientes da compilação dos 4 datasets mencionados acima. As variáveis são:
- country: país onde os dados foram registrados
- 101 países
- year: ano em que os dados foram registrados
- 1987 a 2016
- sex: sexo considerado no registro
- male – masculino
- female – feminino
- age: faixa etária considerada
- 5-14 anos
- 15-24 anos
- 25-34 anos
- 35-54 anos
- 55-74 anos
- 75+ anos
- suicides_no: número de suicídios
- population: população para o grupo
- suicides/100k pop: número de suicídios por 100 mil habitantes
- country_year: identificador contendo
country+year - HDI for year: Índice de Desenvolvimento Humano (IDH) para o ano
- gdp_for_year: Produto Interno Bruto (PIB) para o ano
- gdp_per_capita: Produto Interno Bruto (PIB) per capita
Análise Exploratória dos Dados
Como mencionei acima, este arquivo recebeu um tratamento anterior que facilitará muito a nossa análise.
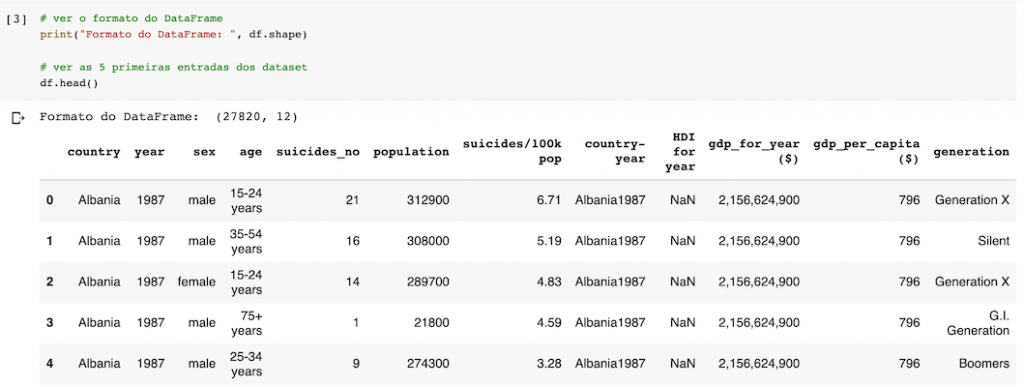
O conjunto de dados contém 27.820 linhas e 12 colunas. Como você pode ver abaixo, os dados podem ser agrupados por vários critérios como país, ano, sexo e idade.
A primeira coisa que eu quero fazer é criar um DataFrame contendo apenas as informações relacionadas ao Brasil. Isso irá facilitar muito nossa manipulação da estrutura, além de ser uma boa prática em projetos de Data Science.

Para ter uma noção da integridade dos dados, vou verificar isoladamente os DataFrames do Brasil e o Mundial. Principalmente quando se quer comparar duas coisas, é importante que elas sejam similares e estatisticamente representativas.
Como você poder ver abaixo, a porcentagem de valores ausentes referentes ao IDH torna inviável o uso dessa variável. Caso se desejasse realmente usar, seria necessária uma etapa de coleta de dados a partir de outras fontes.
Tendência da taxa de suicídio no Brasil
Uma primeira comparação que farei diz respeito ao número de suicídios cometidos no Brasil por 100 mil habitantes, e a tendência do gráfico em relação à taxa mundial.
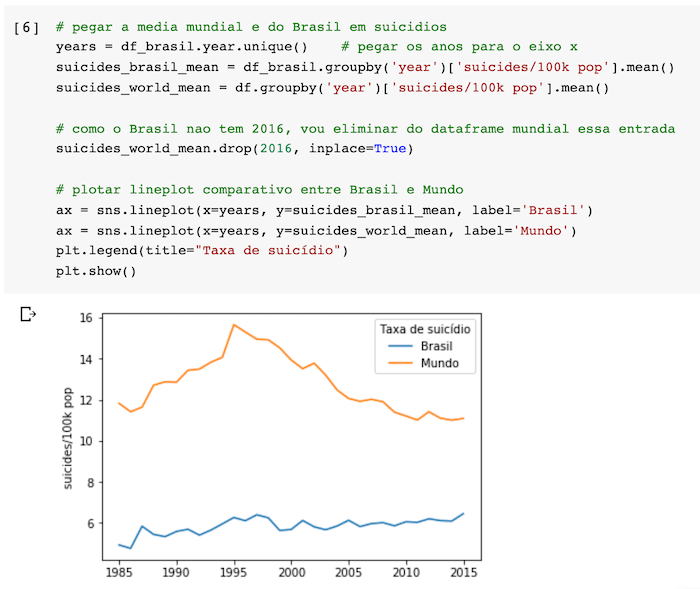
Para ver a tendência, é melhor sempre usar essa relação por 100 mil, pois a população do país cresceu muito de 1985 a 2015. Se formos comparar em termos absolutos, poderemos tirar conclusões erradas ou distorcidas.
Uma coisa que é facilmente percebida no gráfico acima é que, apesar da taxa de suicídios no Brasil ser menor que a média mundial, ela vem crescendo constantemente ao longo de 30 anos.
A linha laranja teve um pico por volta de 1995, porém reverteu o slope e vem caindo ano após ano. Já a linha azul (Brasil) tem um slope positivo praticamente ao longo de todo o período analisado.
Faixa etária com maior índice de suícidio
Abaixo, eu criei uma tabela dinâmica (pivot table) para analisar as 6 faixas etárias em função do ano e do número de suicídios por 100 mil habitantes.
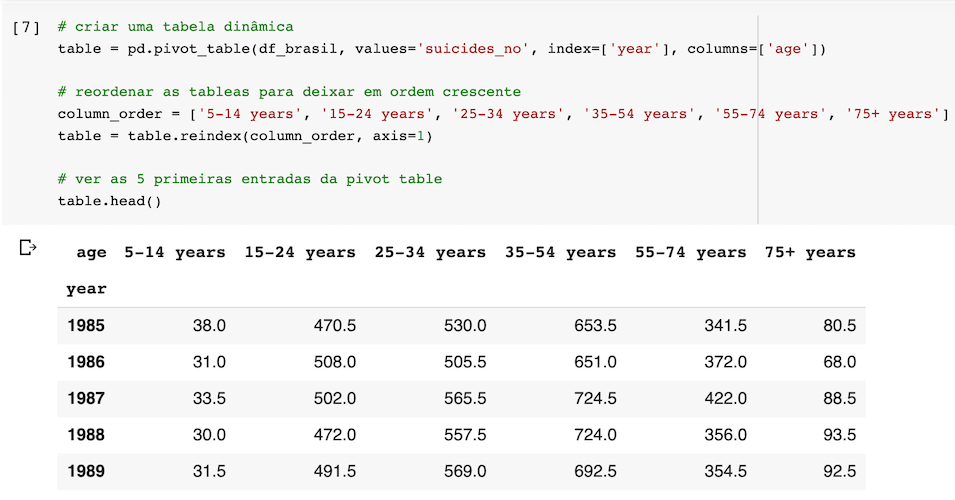
Meu principal objetivo aqui é identificar qual a faixa etária que tem a maior representatividade entre aqueles que tiram a própria vida, e identificar se houve alguma mudança no perfil ao longo de 30 anos.
Mesmo visualmente é fácil identificar que o grupo de pessoas que mais cometem suicídio está entre 35-54 anos. Em segundo lugar, estão pessoas entre 25-34 anos de idade.
Juntos, esses dois grupos correspondem a quase 60% dos registros do banco de dados.
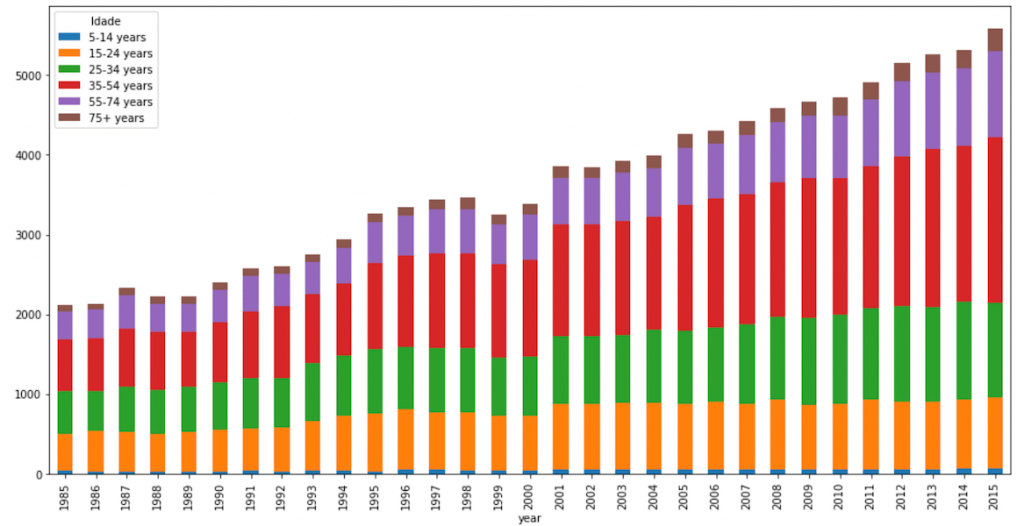
Um outro ponto que vale a pena ressaltar é o aumento de casos entre pessoas acima de 55 anos. Em 1985, as pessoas com mais idade representavam uma pequena fatia do número total.
Entretanto, em 2015 é nítido que mesmo para pessoas acima de 75 anos houve um incremento significativo no número de suicídios.
Para se inferir a causa dessa mudança de padrão, é necessário se avaliar mais profundamente questões que vão além dos números (como exemplo, fatores qualitativos, momento econômico do país e a cultura dominante de cada época).
Taxa de suicídio entre homens e mulheres
Uma outra análise de grande importância é ver a porcentagem dos suicídios entre homens e mulheres.
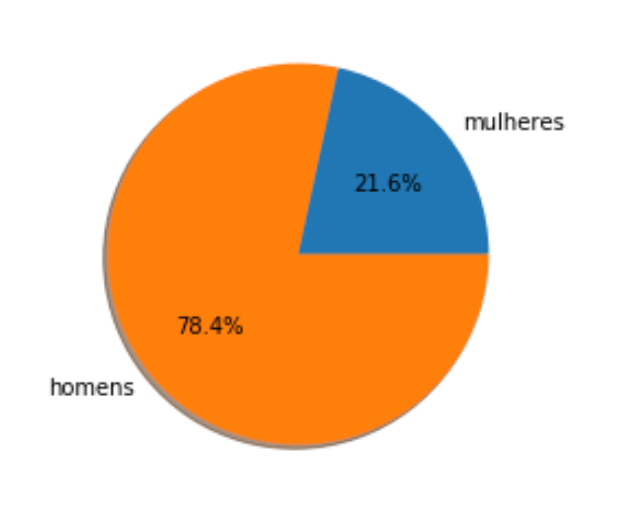
Analisando-se todo o período, o dataset utilizado mostrou que aproximadamente 78% dos casos foram cometidos por homens e 22% deles por mulheres. Optou-se por pegar a média dos 30 anos, pois não houve mudança significativa desse comportamento durante o período.
Correlações entre o PIB, IDH e número de suicídios
Criando uma matriz de correlação e plotando um heatmap, infere-se que o aumento no PIB per capita não diminuiu o número de suicídios por 100 mil habitantes. Na verdade, ele se manteve estável, contrariando o senso comum da maioria das pessoas.
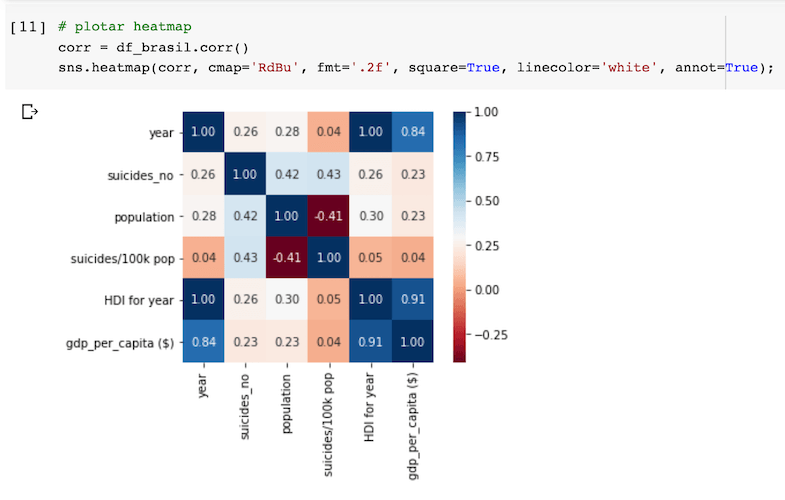
Em relação ao IDH, como foi mencionado anteriormente, há muitos valores ausentes nas células, o que pode dar uma interpretação incorreta ou com viés.
Data Science na prevenção do suicídio
O que eu quis trazer neste artigo foi um projeto de análise de dados , visando conscientizar a comunidade Python e Data Science sobre a real importância de um problema tão latente nos dias atuais; porém, negligenciado ou ignorado por boa parte das pessoas.
O conjunto de dados usado aqui é simplificado, porém ideal para uma abordagem inicial.

Há diversas iniciativas dentro do campo da Inteligência Artificial visando não apenas a conscientização, mas também prevenção de suicídios. Uma das mais populares diz respeito à análise de postagens em redes sociais, onde algoritmos de Machine Learning são capazes de identificar potenciais suicidas e alertar outras pessoas.
A campanha é em setembro, mas falar sobre prevenção do suicídio em todos os meses do ano é fundamental
Setembro Amarelo
Ainda são iniciativas muito incipientes, que esbarram em muitas questões de privacidade. Porém, empresas como o Facebook já tem apostado nesse caminho.
Espero que este artigo tenha trazido um pouco de conhecimento e alertado você sobre um problema tão sério. Sinta-se à vontade para expandir meu notebook e compartilhar o resultado com mais pessoas.
Lembre-se de que não é frescura e que ninguém está querendo aparecer.
Na verdade, a gente nunca tem a mínima ideia do que a outra pessoa está passando. Qualquer atitude que você tenha, que possa contribuir para a prevenção do suicídio, pode significar uma vida que você salvou 😉




















Parabéns pelo estudo e por trazer esse assunto tão pouco comentado 🙂
Muito obrigado pelo seu comentário, Camila. Fico feliz de ter dado algum tipo de contribuição para esse problema tão sério e ignorado por muitos aind 🙂
Parabéns pela iniciativa @Carlos Melo! Pena que os dados só vão até 2016. Seria interessante se tivesse uma variável de “Motivação” (depressão, doença, perda de familiar, drogas…), para uma análise de causa raiz, que ajudaria numa identificação prévia comportamental.
Infelizmente sim. Porém, os quatro links que eu coloquei permitem adicionar novas colunas ao dataset já existente. Um trabalho muito bacana seria concatenar com bases de dados do Brasil. Acredito que graças à Lei de Acesso à Informação, esse tipo de informação deva estar disponibilizada publicamente. Muito obrigado =)
Cara, gostei muito! Parabéns pela iniciativa! Vou estudar com cuidado seus dados. Você deveria publica-los em revista, estão muito bons.
Muito obrigado pelo comentário!
Carlos, excelente post sobre um tema realmente muito crítico e de utilidade pública. Todos precisamos discutir o tema e buscar uma maneira de ajudar a quem mais precisa quanto a esta situação. Você publicou o seu notebook em algum local? Gostaria sim de analisar e, de repente, incrimentá-lo. Parabéns! Obrigado por compartilhar com todos os seus estudos.
Obrigado, Fabiano. Com certeza, um projeto desse serve para ajudar a conscientizar e mostrar como Data Science pode ser aliada 🙂
Carlos Melo, parabéns por seu trabalho em um assunto tão importante à sociedade! Você realizou uma análise excelente com esses dados.
Muito obrigado, Leo! Data Science pode ajudar muito a conscientizar e validar (ou não) algumas hipóteses 🙂
Oi, como voce inseriu esta caixa de comentarios no wordpress? tambem comecei um site em wordpress sobre data science
O WordPress tem essa funcionalidade nativa, mas você consegue usar plugins específicos para isso também 🙂
excelente artigo, Carlos!
obrigado por compartilhar, tanto pela data science quanto pela questão sensível referente ao assunto.