
Já parou para observar a precisão e o controle rítmico no swing do Tiger Woods no golfe? Ou a meticulosa preparação de Roberto Carlos, ajustando a bola antes de mandar um canhão de esquerda no futebol?
Treinar para qualquer esporte requer disciplina, dedicação e muita, muita repetição. Não se trata apenas de aprender as regras ou técnicas, mas de aprimorar as habilidades até executar movimentos perfeitos.
Meu antigo treinador na Academia da Força Aérea costumava dizer que “somente a repetição, até a exaustão, leva à perfeição”.
Só que para corrigir um movimento errado, primeiro eu preciso saber onde estou errando. É aí que entram os treinadores de alto desempenho, usando vídeos para aprimorar ao máximo o desempenho de seus atletas.

Inspirado pelos treinos de judô do Theo, e como Engenheiro de Visão Computacional, pensei: por que não aplicar criar uma aplicação visual para a estimativa de pose de atletas de alto desempenho?
Bem-vindo ao mundo da estimativa de pose humana! Neste tutorial, você vai conhecer a bilbioteca MediaPipe e aprender como detectar as articulações corporais em imagens.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O que é Pose Estimation?
Imagine ensinar um computador a reconhecer (e entender) poses humanas, assim como um humano faria. Com a Estimativa de Pose Humana (Human Pose Estimation – HPE), podemos alcançar exatamente isso.
Aproveitando o poder dos algoritmos de machine learning (ML) e visão computacional, podemos estimar com precisão as posições das articulações do corpo, como ombros, cotovelos, pulsos, quadris, joelhos e tornozelos.

No âmbito dos esportes, essa tecnologia se mostra muito relevante na supervisão e aprimoramento da postura durante atividades físicas, auxiliando na tanto na prevenção de lesões quanto na elevação do rendimento atlético.
Mas essa é apenas uma das possiblidades de aplicação. Veja algumas outras, extraídas diretamente do site de desenvolvedores do Google.
Aplicações da Estimativa de Pose
No que tange à fisioterapia, por exemplo, a identificação precisa de movimentos e posturas desempenha um papel crucial, facilitando o monitoramento do progresso dos pacientes e oferecendo feedback instantâneo durante o processo de reabilitação.
No setor de entretenimento, as aplicações de realidade aumentada e virtual se beneficiam grandemente desta tecnologia, proporcionando uma interação mais natural e intuitiva ao usuário. Basta ver a hype causada pelo jogo Pokemon Go, ou mais recentemente, pelo Apple Vision Pro.

Técnicas de pose estimation ainda têm aplicações promissoras em análise comportamental, sistemas de vigilância, reconhecimento de gestos e na interação humano-computador, criando um campo de possibilidades ainda a ser explorado.
O que é o MediaPipe?
MediaPipe é uma plataforma de código aberto mantida pelo Google, que oferece um conjunto abrangente de ferramentas, APIs e modelos pré-treinados que facilitam como nunca a construção de aplicações para tarefas como estimativa de pose, detecção de objetos, reconhecimento facial, entre outras.
Sendo multiplataforma, você pode criar pipelines em desktops, servidores, iOS, Android, e embarcá-los em dispositivos como Raspberry Pi e Jetson Nano.
MediaPipe Framework
O MediaPipe Framework é um componente de baixo nível utilizado para a construção de pipelines eficientes de Machine Learning (ML) em dispositivos. Possui conceitos fundamentais como pacotes, gráficos e calculadoras que passam, direcionam e processam dados respectivamente. Escrito em C++, Java e Obj-C, o framework consiste nas seguintes APIs:
- Calculator API (C++)
- Graph construction API (Protobuf)
- Graph Execution API (C++, Java, Obj-C)
MediaPipe Solutions
Já o MediaPipe Solutions, por outro lado, é um conjunto de soluções prontas, exemplos construídos de código aberto baseados em um modelo TensorFlow.
Estas soluções são perfeitas para desenvolvedores que querem rapidamente adicionar capacidades de ML aos seus aplicativos, mas sem ter que criar um pipeline do zero. As soluções prontas estão disponíveis em C++, Python, Javascript, Android, iOS e Coral. Veja na galeria abaixo quais são as soluções disponíveis.









Projeto Prático de MediaPipe
Os modelos do MediaPipe Pose podem ser divididos em três categorias principais: baseado em esqueleto, baseado em contorno e baseado em volume.
- Modelo baseado em esqueleto
- Modelo baseado em contorno
- Modelo baseado em volume
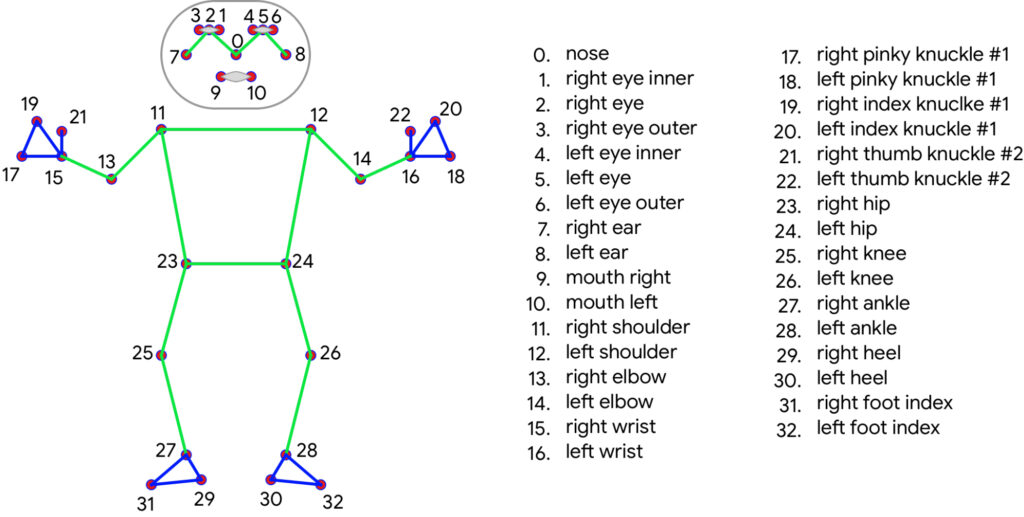
Em nosso contexto, MediaPipe Pose adota a abordagem baseada em esqueleto, utilizando a topologia de 33 marcos, conhecidos como landmarks, e derivados do BlazePose.
Vale ainda ressaltar que, diferente de modelos como YOLOv8 ou YOLO-NAS que foram estruturados para a detecção de múltiplas pessoas, MediaPipe Pose é uma estrutura voltada para pose estimation de uma única pessoa.
Pré-requisitos
Agora vamos aprender na prática como estimar poses em imagens usando um modelo pronto do MediaPipe. Todo o material e código utilizados neste tutorial podem ser baixados gratuitamente.
As bibliotecas que serão usadas são OpenCV e MediaPipe. Use o arquivo requirements.txt (fornecido na pasta do código) para prosseguirmos.
pip install -r requirements.txt
Ao executar o bloco de código acima, todas as as dependências necessárias para o projeto serão instaladas de uma maneira conveniente.
# bibliotecas necessárias import cv2 import mediapipe as mp import matplotlib.pyplot as plt
Primeiro, importamos as bibliotecas necessárias. A biblioteca cv2 é usada para processamento e manipulação de imagens, enquanto mediapipe é o pacote Python que fornece o framework MediaPipe para a estimativa de pose. Adicionalmente, importamos matplotlib.pyplot para visualizar os resultados posteriormente.
Agora que importamos as bibliotecas necessárias, podemos prosseguir com as próximas etapas em nosso pipeline de estimativa de pose. As soluções em Python são muito fáceis e diretas. Para a tarefa de Pose Estimation, nós iremos seguir essas etapas:
- Detectar e desenhar pose landmarks
- Desenhar landmark connections
- Obter o pixel de coordenada da landmark
Etapa 1: Detectar e desenhar pose landmarks
Nesta etapa,. nós vamos identificar os principais pontos do corpo, ou landmarks, e desenhá-los em nossas imagens e vídeos para uma visualização mais intuitiva.
# Carregando a imagem usando OpenCV.
img = cv2.imread("roberto-carlos-o-melhor-do-mundo.jpg")
# Obtendo a largura e a altura da imagem.
img_width = img.shape[1]
img_height = img.shape[0]
# Criando uma figura e um conjunto de eixos.
fig, ax = plt.subplots(figsize=(10, 10))
ax.axis('off')
ax.imshow(img[...,::-1])
plt.show()
Primeiramente, o código carrega uma imagem usando a função imread do OpenCV. O arquivo de imagem, nomeado “roberto-carlos-o-melhor-do-mundo.jpg”, que se encontra na pasta de arquivos, é lido e armazenado na variável img.
Em seguida, o código recupera a largura e a altura da imagem usando o atributo shape do array img. A largura é atribuída à variável img_width e a altura à variável img_height.
Depois disso, uma figura e um conjunto de eixos são criados usando plt.subplots. O parâmetro figsize define o tamanho da figura para 10×10 polegadas. A linha ax.axis('off') remove os rótulos e marcas do eixo do gráfico. Finalmente, a imagem é exibida nos eixos usando ax.imshow, e plt.show() é chamado para renderizar o gráfico.
# Inicializando os módulos Pose e Drawing do MediaPipe. mp_pose = mp.solutions.pose mp_drawing = mp.solutions.drawing_utils
O código inicializa dois módulos do framework MediaPipe: mp_pose e mp_drawing.
O módulo mp_pose fornece a funcionalidade para a estimativa de pose. Ele contém modelos pré-treinados e algoritmos que podem detectar e rastrear poses do corpo humano em imagens ou vídeos. Este módulo é crucial para a realização de tarefas de estimativa de pose usando o MediaPipe.
O módulo mp_drawing, por outro lado, fornece utilitários para desenhar as poses detectadas em imagens ou vídeos. Ele oferece funções para sobrepor os marcos de pose e as conexões na mídia visual, facilitando a visualização e interpretação dos resultados da estimativa de pose.
with mp_pose.Pose(static_image_mode=True) as pose:
"""
Esta função utiliza a biblioteca MediaPipe para detectar e desenhar 'landmarks'
(pontos de referência) em uma imagem. Os 'landmarks' são pontos de interesse
que representam diferentes partes do corpo detectadas na imagem.
Args:
static_image_mode: um booleano para informar se a imagem é estática (True) ou sequencial (False).
"""
# Faz uma cópia da imagem original.
annotated_img = img.copy()
# Processa a imagem.
results = pose.process(img)
# Define o raio do círculo para desenho dos 'landmarks'.
# O raio é escalado como uma porcentagem da altura da imagem.
circle_radius = int(.007 * img_height)
# Especifica o estilo de desenho dos 'landmarks'.
point_spec = mp_drawing.DrawingSpec(color=(220, 100, 0), thickness=-1, circle_radius=circle_radius)
# Desenha os 'landmarks' na imagem.
mp_drawing.draw_landmarks(annotated_img,
landmark_list=results.pose_landmarks,
landmark_drawing_spec=point_spec)
Vamos quebrar este bloco de código e entender como ele funciona.
O bloco de código começa com uma instrução with que inicializa a classe mp_pose.Pose do MediaPipe. Esta classe é responsável por detectar e desenhar marcos (pontos-chave) em uma imagem. O argumento static_image_mode é configurado como True para indicar que a imagem sendo processada é estática.
Em seguida, uma cópia da imagem original é criada usando img.copy(). Isso garante que a imagem original não seja modificada durante o processo de anotação.
A função pose.process() é então chamada para processar a imagem e obter os resultados da estimativa de pose. Os resultados contêm os marcos de pose detectados.
O código define o raio do círculo usado para desenhar os marcos com base em uma porcentagem da altura da imagem. Isso permite que o tamanho do círculo seja proporcional ao tamanho da imagem.
Um objeto point_spec é criado usando mp_drawing.DrawingSpec para especificar o estilo de desenho dos marcos. Ele define a cor, a espessura e o raio do círculo dos marcos desenhados.
Finalmente, mp_drawing.draw_landmarks() é chamado para desenhar os marcos na annotated_img usando o estilo especificado e os landmarks obtidos a partir dos resultados.
Este bloco de código demonstra como usar o MediaPipe para detectar e desenhar landmarks em uma imagem. Ele fornece uma representação visual da pose detectada, permitindo-nos analisar e interpretar os resultados da estimativa de pose.
Etapa 2: Desenhar landmarks connection
Além de detectar landmarks individuais, o MediaPipe também permite desenhar conexões entre estes, facilitando a compreensão da postura geral.
# Faz uma cópia da imagem original.
annotated_img = img.copy()
# Especifica o estilo de desenho das conexões dos marcos.
line_spec = mp_drawing.DrawingSpec(color=(0, 255, 0), thickness=2)
# Desenha tanto os pontos dos marcos quanto as conexões.
mp_drawing.draw_landmarks(
annotated_img,
landmark_list=results.pose_landmarks,
connections=mp_pose.POSE_CONNECTIONS,
landmark_drawing_spec=point_spec,
connection_drawing_spec=line_spec
)
Primeiro, é criada uma cópia da imagem original. Em seguida, o estilo para desenhar as conexões entre os marcos é especificado usando a classe mp_drawing.DrawingSpec, com a cor verde e espessura de 2.
Depois, a função mp_drawing.draw_landmarks é chamada para desenhar tanto os pontos dos marcos quanto as conexões na imagem anotada. Ela recebe a imagem anotada, a lista de marcos de pose do objeto de resultados, as conexões predefinidas de mp_pose.POSE_CONNECTIONS, e as especificações de desenho para os marcos e conexões.
Etapa 3: Obter o pixel de coordenada da landmark
Agora nós podemos extrair as coordenadas de pixel correspondentes a cada landmark, permitindo análises mais detalhadas. Estas coordenadas de pixels, quando usadas em conjunto com as conexões entre os marcos, podem ser extremamente úteis para entender a posição e orientação de várias partes do corpo em uma imagem.
Além disso, essas coordenadas podem ser usadas para calcular métricas mais complexas, como a proporção entre diferentes partes do corpo, que pode ser útil em muitas aplicações, como análise biomecânica, criação de avatares virtuais, animação e muito mais.
# Seleciona as coordenadas dos pontos de interesse.
l_knee_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_KNEE].x * img_width)
l_knee_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_KNEE].y * img_height)
l_ankle_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_ANKLE].x * img_width)
l_ankle_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_ANKLE].y * img_height)
l_heel_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_HEEL].x * img_width)
l_heel_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_HEEL].y * img_height)
l_foot_index_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_FOOT_INDEX].x * img_width)
l_foot_index_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_FOOT_INDEX].y * img_height)
# Imprime as coordenadas na tela.
print('Coordenadas do joelho esquerdo: (', l_knee_x,',',l_knee_y,')' )
print('Coordenadas do tornozelo esquerdo: (', l_ankle_x,',',l_ankle_y,')' )
print('Coordenadas do calcanhar esquerdo: (', l_heel_x,',',l_heel_y,')' )
print('Coordenadas do índice de pé esquerdo: (', l_foot_index_x,',',l_foot_index_y,')' )
O bloco de código acima destaca a extração e impressão de coordenadas específicas dos marcos (landmarks) a partir dos resultados de estimativa de pose.
Primeiramente, o código calcula as coordenadas x e y de quatro pontos de interesse (joelho esquerdo, tornozelo esquerdo, calcanhar esquerdo e índice do pé esquerdo). Vale ressaltar que cada marco (landmark) possui um número específico de acordo com o modelo BlazePose.
Coordenadas do joelho esquerdo: ( 554 , 747 ) Coordenadas do tornozelo esquerdo: ( 661 , 980 ) Coordenadas do calcanhar esquerdo: ( 671 , 1011 ) Coordenadas do índice de pé esquerdo: ( 657 , 1054 )
Depois, multiplicamos as posições normalizadas dos marcos pela largura e altura da imagem. Essas coordenadas são então impressas na tela usando instruções print.
# Exibindo um gráfico com os pontos selecionados. fig, ax = plt.subplots() ax.imshow(img[:, :, ::-1]) ax.plot([l_knee_x, l_ankle_x, l_heel_x, l_foot_index_x], [l_knee_y, l_ankle_y, l_heel_y, l_foot_index_y], 'ro') plt.show()
Por fim, os quatro pontos de interesse são plotados no gráfico como pontos vermelhos usando ax.plot e o gráfico é exibido usando plt.show().
Takeaways
Neste tutorial, exploramos o conceito de estimativa de pose com o MediaPipe. Aprendemos sobre o MediaPipe, um poderoso framework para construir pipelines perceptuais multimodais, e como ele pode ser usado para estimativa de pose humana.
Cobrimos os conceitos básicos de estimativa de pose em imagens e discutimos como interpretar a saída. Especificamente, nós vimos que:
- MediaPipe é um framework versátil para construir pipelines perceptuais.
- A estimativa de pose nos permite rastrear e analisar a pose de uma pessoa em uma imagem ou vídeo.
- Os modelos de estimativa de pose do MediaPipe fornecem coordenadas para várias partes do corpo, possibilitando aplicações em campos como rastreamento de condicionamento físico, realidade aumentada e mais.
Em um próximo tutorial, eu vou te ensinar a aplicar esses conceitos em vídeos para calcular trajetórias e ângulos dentre determinadas partes do corpo.



















