A startup chinesa DeepSeek acaba de lançar um novo modelo de raciocínio que iguala o desempenho do ChatGPT o1 em diversos benchmarks, mas operando a um custo significativamente menor.
Testes iniciais independentes indicam que o modelo DeepSeek R1 não apenas compete, mas, em alguns cenários, supera o ChatGPT em áreas como resolução de problemas matemáticos e análise lógica.
De acordo com Hancheng Cao, professor assistente de sistemas de informação na Universidade de Emory, este avanço possui um caráter igualitário, permitindo que pesquisadores e desenvolvedores com recursos limitados implementem suas próprias versões do modelo.
Impacto das sanções americanas nas empresas de IA chinesas
Em 2022, o governo Biden implementou restrições que impediram a NVIDIA de vender GPUs mais avançadas do que os modelos A100 mais antigos para a China. Como resposta, a NVIDIA desenvolveu versões alternativas, conhecidas como H800 e A800, que também acabaram sendo proibidas em outubro de 2023.

Mesmo em meio a esse contexto sanções dos EUA restrições às empresas chinesas de inteligência artificial, a DeepSeek se viu motivada a inovar, priorizando eficiência, colaboração e o uso de recursos compartilhados.
Essa estratégia não só permitiu à DeepSeek desenvolver o R1, mas também lançar versões menores que podem ser executadas localmente em laptops. Isso demonstra como a empresa transformou desafios em oportunidades.
DeepSeek R1: Eficiência e Inovação em IA
Desenvolvido com um orçamento de apenas US$ 6 milhões, o modelo foi treinado utilizando 2,78 milhões de horas de GPU – muito menos que os 30,8 milhões de horas necessárias para modelos de escala similar da Meta, por exemplo.
Com 671 bilhões de parâmetros, o R1 foi treinado no modelo-base DeepSeek V3, utilizando uma arquitetura que prioriza o raciocínio em cadeia de pensamento (Chain of Thought).

Apesar de seu tamanho, apenas 37 bilhões de parâmetros são ativados em operações regulares, reduzindo drasticamente os custos de computação sem sacrificar a precisão.
Lançado como código aberto sob a licença MIT, o modelo oferece flexibilidade para desenvolvedores e empresas criarem soluções personalizadas sem custos de licenciamento. Além disso, a DeepSeek oferece versões menores, conhecidas como “distilled models”, que são otimizadas para aplicações específicas.
Desempenho Comparativo: DeepSeek R1 vs. OpenAI o1
O DeepSeek R1 e o OpenAI o1 demonstram desempenhos bastante competitivos em benchmarks-chave, cada um com pontos fortes específicos.
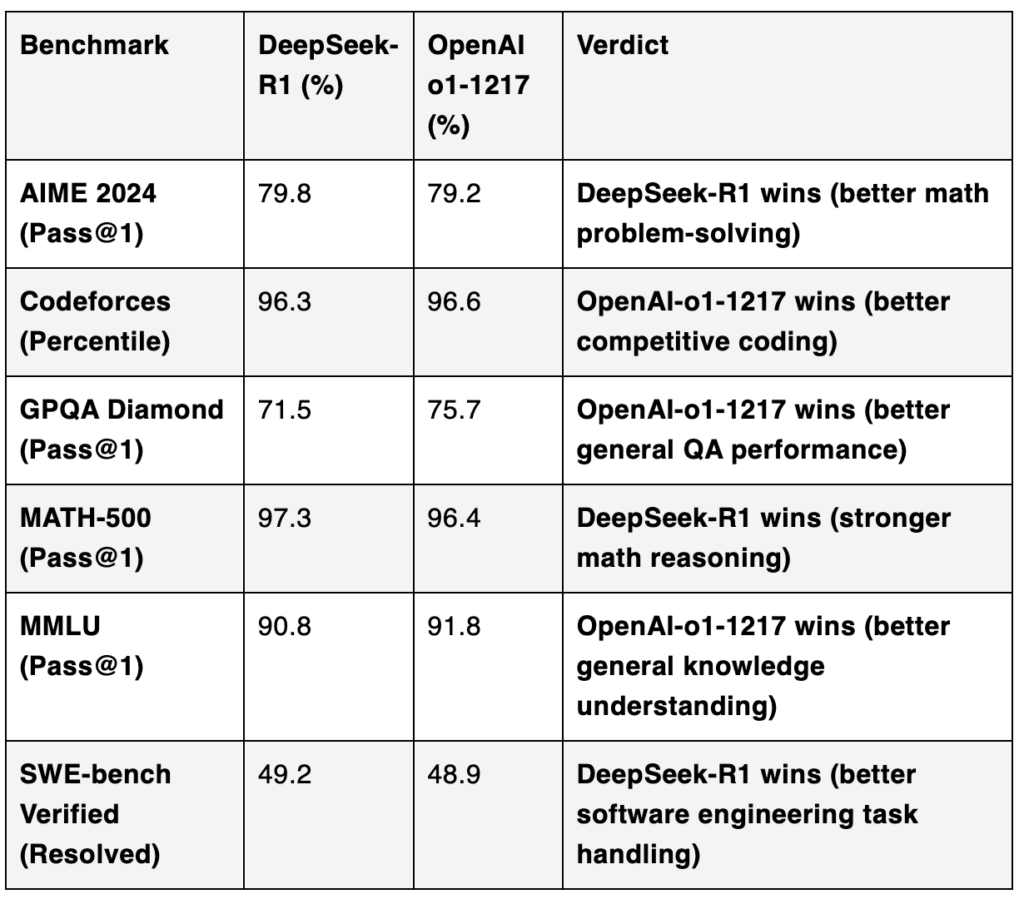
Raciocínio Matemático: O DeepSeek R1 supera o OpenAI o1 em benchmarks como AIME 2024 (79.8% vs. 79.2%) e MATH-500 (97.3% vs. 96.4%). Esses resultados destacam a superioridade do R1 em tarefas de alto rigor matemático, com maior precisão e capacidade de resolver problemas complexos.
Conhecimento Geral e Programação Competitiva: O OpenAI o1 leva vantagem em benchmarks como GPQA Diamond (75.7% vs. 71.5%) e MMLU (91.8% vs. 90.8%), que testam a compreensão geral e multitarefa. Ele também supera o DeepSeek R1 no Codeforces (96.6% vs. 96.3%), evidenciando um leve domínio em desafios de programação competitiva e algoritmos.
Tarefas de Engenharia de Software: No benchmark SWE-bench Verified, o DeepSeek R1 registra uma ligeira vantagem (49.2% vs. 48.9%), demonstrando competência em resolver problemas relacionados a engenharia de software, com desempenho similar ao OpenAI o1.
Resumidamente, o DeepSeek R1 é particularmente forte em tarefas matemáticas e de software, enquanto o OpenAI o1 se destaca em áreas de conhecimento geral e programação competitiva.
A escolha entre os modelos dependerá das necessidades específicas de aplicação: raciocínio especializado ou tarefas mais amplas e generalistas.
Fontes:
https://www.technologyreview.com/2025/01/24/1110526/china-deepseek-top-ai-despite-sanctions/
https://www.analyticsvidhya.com/blog/2025/01/deepseek-r1-vs-openai-o1/



















