Como unir Machine Learning com Recursos Humanos para reduzir o Turnover?
Com o imenso volume de dados sendo criado atualmente, é vital que as empresas saibam coletar e utilizar dados que possam dar a elas vantagens competitivas no mercado.

Além de casos mais comuns como Sistemas de Recomendação, outras áreas e outros tipos de empresas também podem se beneficiar da Ciência de Dados.
O objetivo deste projeto é analisar os dados disponíveis e buscar soluções para diminuir o Turnover, e aumentar a retenção de bons profissionais nas empresas.
Utilizando dados disponibilizados no Kaggle, construiremos um modelo de Machine Learning capaz de nos ajudar a prever possíveis atritos, que podem ajudar empresas a tomarem decisões afim de minimizar esses efeitos, aumentar a qualidade de vida no ambiente de trabalho, e reter os bons profissionais da empresa.
Você pode encontrar o projeto completo com todas as análises neste link.
Análise De Dados sobre Turnover
O primeiro passo, é entendermos nossos dados. Utilizando Python, e a biblioteca Pandas, conseguimos tirar insights interessantes.
A variável Attrition (“Atrito”), indica se o funcionário possui atrito, problema, no ambiente de trabalho. Usaremos ela como variável alvo do nosso modelo de Machine Learning.
No nosso dataset, ela seria a categoria mais marcante de motivo para que o profissional saia da empresa e aumente o Turnover. Por isso focamos nela.
Com acesso a mais dados, poderíamos usar outros indicadores, ou criar novas features que representem melhor a chance de um funcionário deixar a empresa.
Variáveis Numéricas
Primeiro, vamos analisar a distribuição estatística das variáveis numéricas:
- A média de idade na empresa é de quase 37 anos de idade.
- A maioria dos funcionários possui Ensino Superior.
- Como se trata de um conjunto de dados oriundo dos Estados Unidos, consideramos os valores monetários como Dólar. Neste caso, o salário médio mensal da empresa é de US$6502.93.
Variáveis Categóricas
Quanto às variáveis categóricas, conseguimos as seguintes informações:
- A maior parte dos funcionários nâo apresenta atritos.
- O departamento com mais funcionários na empresa é Pesquisa e Desenvolvimento.
- Homens são maioria na empresa.
- O emprego mais comum na empresa é de Executivo de Vendas.
- A maioria dos funcionários é casado.
- A grande maioria dos funcionários não faz hora extra.
Igualdade de Gênero
É muito importante estar atento a um tema como Igualdade de Gênero.
Tendo acesso aos dados de salário e educação dos funcionários, é possível ver como se comparam os salários entre homens e mulheres.
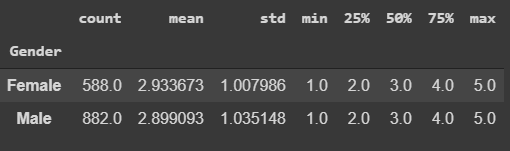
Comparando funcionários dos dois gêneros, percebemos que as mulheres tem educação marginalmente melhor, estatísticamente falando. Para essa variável, quando maior o número, maior o nível de educação.
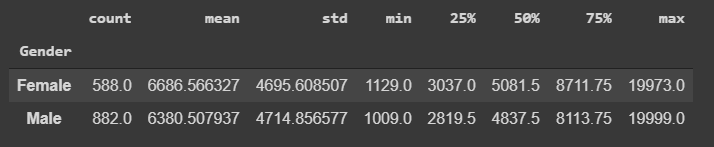
Na empresa em questão, igualdade de gênero é uma realidade, com as mulheres, que estão em um nível educacional marginalmente acima, com média de salário mensal superior à média dos homens.
Não só isso, mas em todos os percentis, temos que os salários das mulheres são mais altos, com excessão apenas para Max, que mostra que o funcionário mais bem pago da empresa é um homem.
Gráfico de Densidade
Gráficos de Densidade são ferramentas visuais poderosas, que podem nos ajudar a ter insights valiosos.
Nosso principal objetivo aqui é analisar a distribuição das variáveis para as duas possibilidades do nosso problema de classificação.
Ao analisarmos as diferenças de distribuição das variáveis para cada classe, podemos identificar variáveis mais relevantes para o nosso problema.
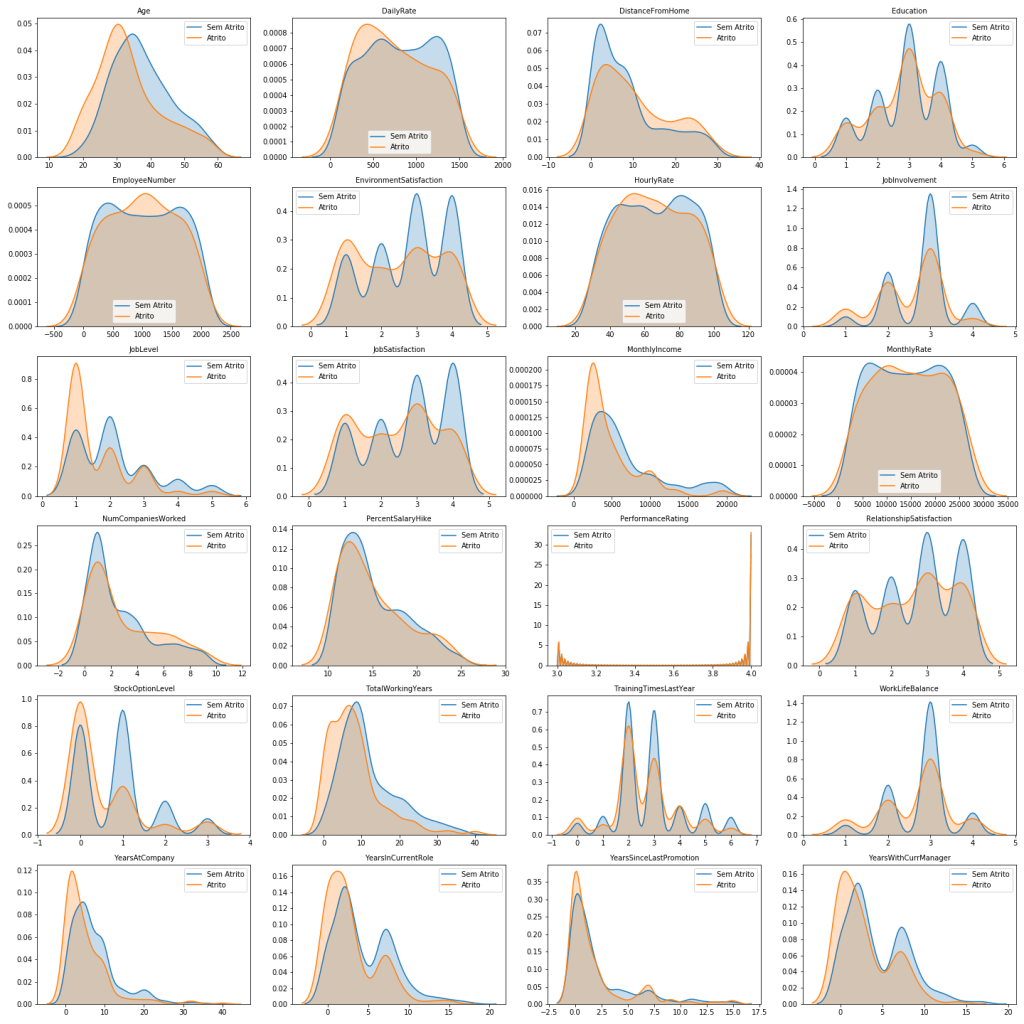
A representação amarela é para funcionários que apresentam atritos e a representação azul para funcionários que não apresentam atrito.
O que buscamos aqui são diferenças nas distribuições para podermos encontrar pontos chave para previsão de atrito entre os funcionários.
No geral, as distribuições são bastante parecidas, não havendo grande discrepância. Por isso, destacarei aqui somente as discrepâncias entre as categorias.
Entre os principais insights obtidos, podemos destacar:
- Na variável Age (Idade), percebemos que quanto mais jovem, mais propensão a atrito há.
- Em relação à distância de casa (DistanceFromHome), percebemos que quanto maior a distância, mais propenso o funcionário está a atrito.
- Na variável JobInvolvement (Envolvimento no Trabalho), podemos perceber que indivíduos menos envolvidos tendem a ter mais atrito.
- JobLevel (Nível no Emprego) mostra que funcionários em níveis mais baixos tendem a ter mais atrito. O mesmo acontece para as variáveis JobSatisfaction e MonthlyIncome, (Satisfação no Trabalho e Renda Mensal, respectivamente).
- StockOptionLevel (ESOs) e TotalWorkingYears (Total de Anos Trabalhando), também demonstram diminuição nos atritos conforme os números aumentam.
- YearsAtCompany (Anos na Empresa), YearsInCurrentRole (Anos na Posição Atual), YearsSinceLastPromotion (Anos Desde a Última Promoção), YearsWithCurrManager (Anos Com o Mesmo Gerente) apresentam maior atrito nos menores períodos de tempo, e evolução ao longo do tempo. Isso pode sugerir dificuldades de adaptação, pois quanto menor o tempo, maior o atrito.
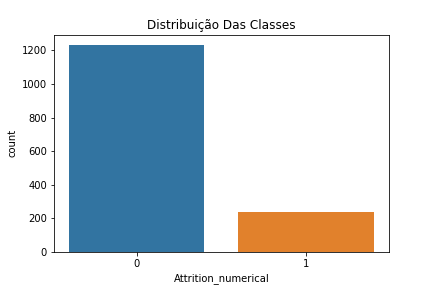
Balanceamento de Dados
Felizmente, funcionários que apresentam atritos ou problemas são minoria. Para a empresa, isso é bom, mas para nosso modelo preditivo este não é o cenário ideal.
Para melhorar a performance, e obtermos melhores resultados, se faz necessário o Balanceamento dos Dados.
De forma simples e resumida, isso basicamente significa que vamos transformar noso conjunto de dados, para que as duas classes (Com e Sem Atrito) estejam balanceadas, proporcionalmente distribuídas.
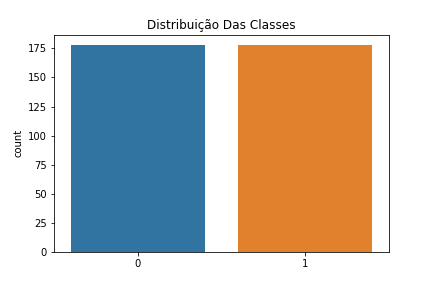
Para isso, utilizaremos o Random Under Sampler, pois desejamos preservar a classe minoritária (Com Atrito). Após balancearmos os dados, temos o seguinte resultado:
Pré-Processamento De Dados
Para inserir nossos dados em um modelo de Machine Learning precisamos trabalhá-los. Ao fazer o pré-processamento dos dados, vamos passar por duas etapas:
- Transformação de variáveis categóricas: Utilizaremos o Label Encoder, que transforma Strings em números representando categorias.
- Transformação de variáveis numéricas: Uitlizaremos MinMaxScaler. De forma simples, ele coloca os números das entradas em uma escala de 0 a 1. Esse processo também nos ajuda com Outliers, por isso não havíamos tratado eles anteriormente.

Modelo de Machine Learning para Turnover
Prevendo atrito e prevenindo Turnover. Após entendermos melhor nossos dados, e a realidade da empresa, e prepararmos nossos dados, é hora de utilizarmos Machine Learning para fazer previsões.
Essa etapa irá contribuir para nos ajudar na prevenção de atritos/conflitos na empresa, e, consequentemente, diminuirmos o Turnover. Para isso, utilizaremos dois modelos diferentes de algoritmos:
Regressão Logística
- Random Forest
- Regressão Logística
Regressão Logística
De acordo com o Portal Action, “o modelo de regressão logística é semelhante ao modelo de regressão linear. No entanto, no modelo logístico a variável resposta $ Y_i $ é binária. Uma variável binária assume dois valores, como por exemplo, $ Y_i=0 $ e $ Y_i=1, $ denominados “fracasso” e “sucesso”, respectivamente. Neste caso, “sucesso” é o evento de interesse.”
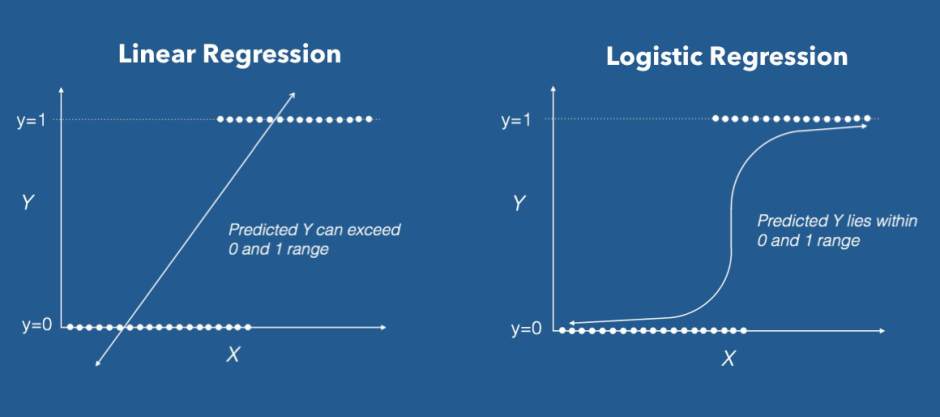
Para nós, “Sucesso” (1), significa atrito, que é o que queremos descobrir.
Baseline Com Dados Não Balanceados
Como estamos trabalhando em um projeto que existe no vácuo, isto é, sem contexto prévio de métricas já utilizadas pela empresa, precisamos criar uma baseline, um resultado mínimo aceitável, que sirva de referência para nosso aprimoramento.
Neste caso, utilizarei o modelo de Regressão Logística, com nossos dados desbalanceados. Isso é importante para que possamos aferir se há mesmo a necessidade de balancear nossos dados.
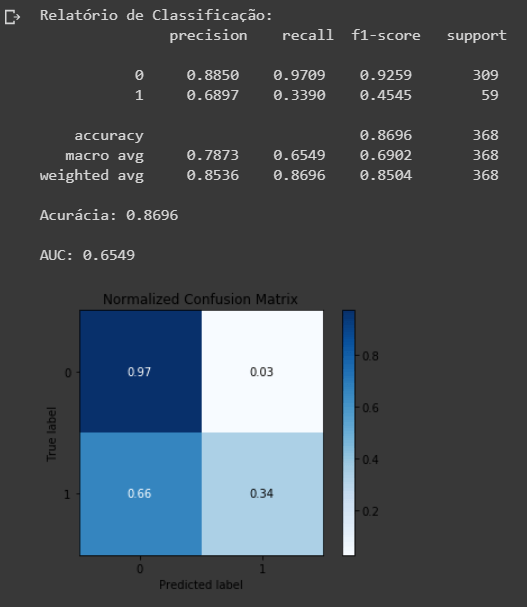
Ao analisarmos a Matriz de Confusão, conseguimos ver que tivemos muitos Falsos Negativos, o que é um problema.
- Apesar do modelo apresentar uma Acurácia de cerca de 87% não podemos levar apenas essa métrica em consideração.
- Nosso AUC foi de 0.6291, o que significa que precisamos melhorar bastante. Para entender melhor sobre ROC_AUC, veja este artigo. Para simplificar, apenas entendamos que quanto maior esse valor, melhor.
Regressão Logística com Dados Balanceados
Agora que temos nossa baseline, e um objetivo a bater, é hora de trabalharmos com nossos dados cuidadosamente trabalhados e buscarmos o nosso melhor.
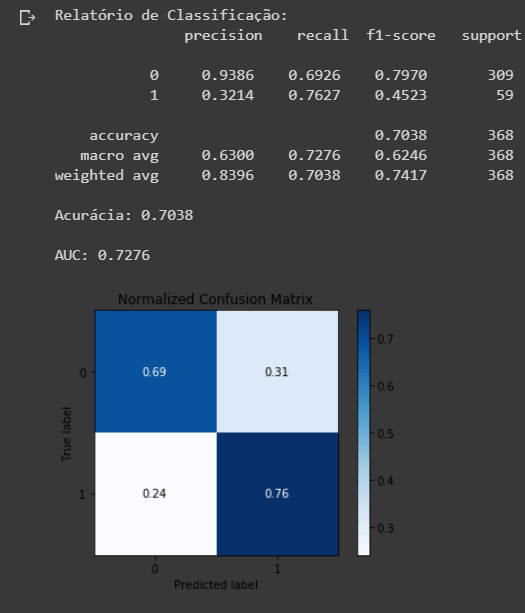
Aqui podemos ver que com dados balanceados, nossos resultados foram melhores.
- Apesar da nossa acurácia ter caído, nosso AUC melhorou, o que é bom.
- Entretanto, apesar de termos diminuído a quantidade de Falsos Negativos, aumentamos a de Falsos Positivos.
De qualquer forma, obtivemos um resultado melhor que nossa baseline, o que já é um passo na direção correta.
Random Forest
Vamos testar se conseguiríamos um resultado superior utilizando outro algoritmo de Machine Learning. Neste caso, utilizaremos o Random Forest, que em tradução livre, significa “Floresta Aleatória”.
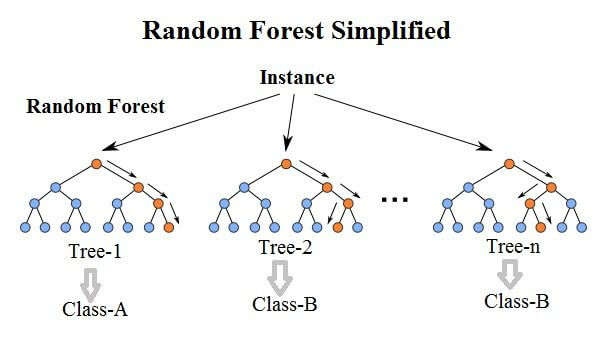
Como o nome sugere, ele é baseado em modelos de árvore de decisão. A diferença é que ele cria muitas árvores de decisão de maneira aleatória.
Vamos ver como ele se sai.
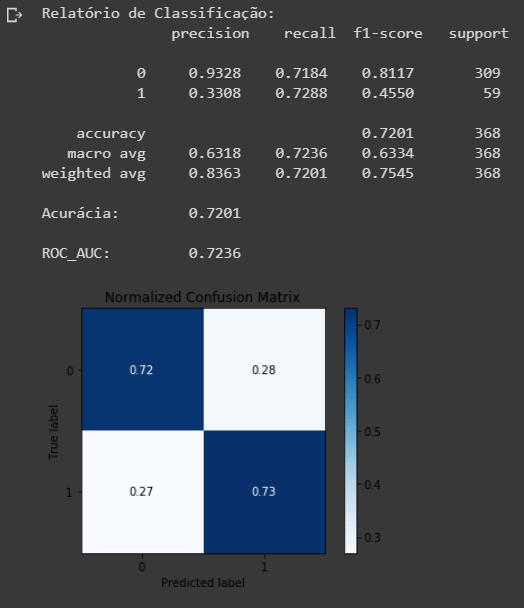
O modelo Random Forest se saiu marginalmente melhor que a Regressão Logística.
Apesar de não representar melhora significativa, com melhor parametrização, ambos modelos podem ter sua performance aumentada.
Variáveis Mais Importantes (Feature Importances)
Através da função feature_importances_ , podemos verificar quais variáveis foram mais importantes para as decisões do nosso modelo.
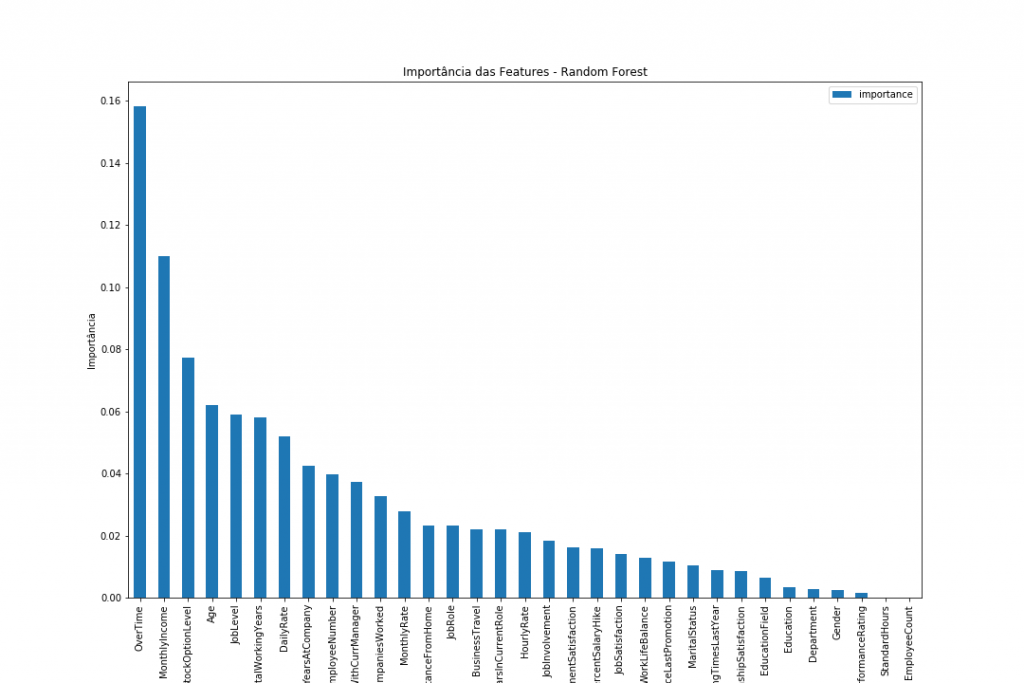
As variáveis mais importantes são muito valiosas, pois podem nos dar insights dos pontos mais críticos para geração de atritos, e com essa informação, podemos agir preventivamente.
Entre as principais variáveis, podemos destacar:
- Horas Extras (OverTime) — Definitivamente a mais importante das variáveis,estando bastante acima das outras.
- Salário Mensal (MonthlyIncome)
- ESOs (StockOptionLevel)
- Idade (Age)
- Nível do Cargo (JobLevel)
- Anos Trabalhando (TotalWorkingYears)
Podemos identificar variáveis bastante relacionadas com a carreira, benefícios e carga horária. Altos níveis de stress? Sentimento de desvalorização? São hipóteses. Somente uma análise mais detalhada pode nos dizer.
Ciência de Dados, Machine Learning e Turnover
Ciência de Dados é um campo em expansão, com muita coisa a ser explorada e melhorada. Neste projeto, o intuito foi apresentar uma espécie de MVP para o departamento de RH.

Sem sombra de dúvidas, com acesso a mais dados, colaboração com outros times da empresa, maior entendimento do contexto em que a empresa se encontra e otimização dos modelos apresentados e/ou inclusão de outros, os resultados podem ser muito melhores.
De qualquer forma, espero ter fornecido insights interessantes, e um projeto pertinente.
Caso tenha algum comentário, dúvida ou sugestão, não hesite em me contactar no meu LinkedIn, e conferira o código deste projeto na íntegra, bem como meus outros projetos, acesse meu portfólio no GitHub.



















