Se você trabalha com dados tabulares e ainda não conhece o XGBoost, está deixando performance na mesa. Esse é o algoritmo que dominou competições do Kaggle por anos e continua sendo a primeira escolha de cientistas de dados para problemas de classificação e regressão com dados estruturados.
Neste tutorial, vou explicar o que é o XGBoost, como ele funciona por dentro, e como implementar do zero em Python. Vou mostrar também quando ele é a melhor escolha e como se compara com Random Forest e LightGBM.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O Que é o XGBoost?
XGBoost significa _eXtreme Gradient Boosting_. É uma biblioteca de machine learning criada por Tianqi Chen em 2014 que implementa o algoritmo de gradient boosting de forma otimizada para velocidade e performance.
Na prática, o XGBoost constrói centenas de árvores de decisão pequenas em sequência, onde cada árvore nova tenta corrigir os erros das anteriores. O resultado final é a soma das previsões de todas essas árvores.
Pense assim: imagine que você pede para 100 pessoas darem um palpite sobre o preço de uma casa. Cada pessoa, individualmente, vai errar bastante. Mas se cada pessoa puder ver os erros de quem veio antes e tentar corrigi-los, a previsão final do grupo vai ser muito mais precisa do que qualquer palpite individual.
É exatamente isso que o XGBoost faz. E faz de forma extremamente eficiente, usando paralelização, regularização e otimizações que o tornaram o algoritmo mais usado em competições de machine learning por vários anos consecutivos.
Por que o XGBoost é tão popular?
- Performance superior em dados tabulares: consistentemente vence outros algoritmos em benchmarks com dados estruturados
- Velocidade: implementação otimizada em C++ com suporte a paralelização
- Regularização embutida: parâmetros L1 e L2 ajudam a evitar overfitting
- Lida bem com dados faltantes: trata valores ausentes nativamente, sem precisar de imputação manual
- Flexibilidade: funciona para regressão, classificação binária, classificação multiclasse e ranking
Como Funciona o Gradient Boosting
Para entender o XGBoost, você precisa entender dois conceitos: árvores de decisão e gradient boosting.
Árvores de Decisão
Árvores de decisão são métodos onde uma função recebe um vetor de valores (atributos) como entrada e retorna uma decisão de saída.
Para chegar no valor de saída, a árvore executa uma série de testes, criando ramificações ao longo do processo. Cada nó representa uma decisão. Quanto mais vezes um atributo é usado nas tomadas de decisão, maior será sua importância relativa no modelo.
Gradient Boosting
_Gradient Boosting_ combina resultados de muitos classificadores “fracos” (tipicamente árvores de decisão pequenas) que, juntos, formam um modelo forte.
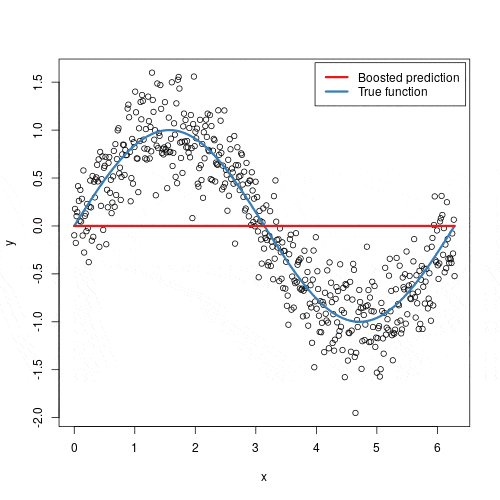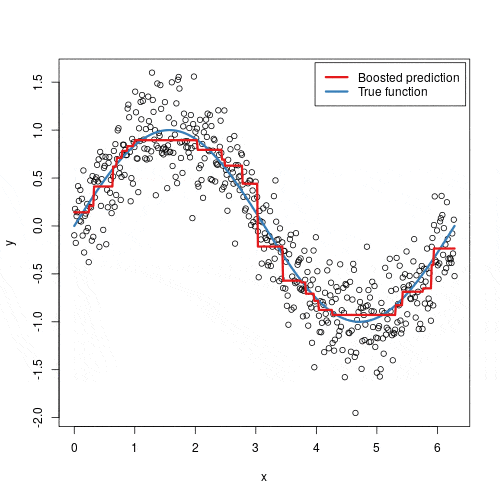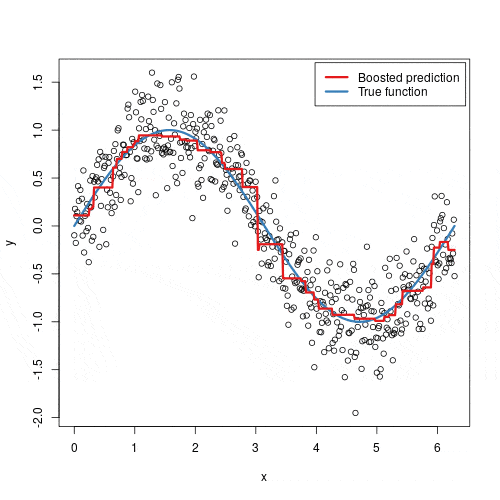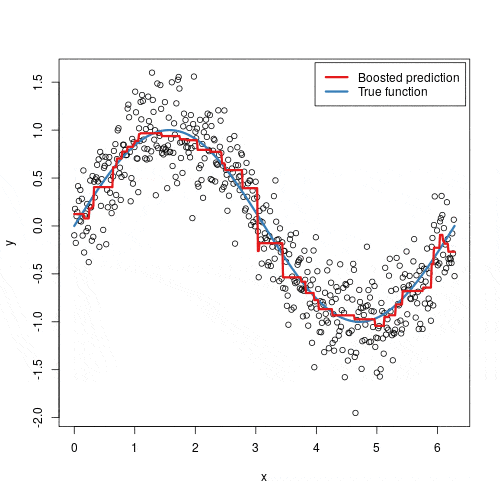
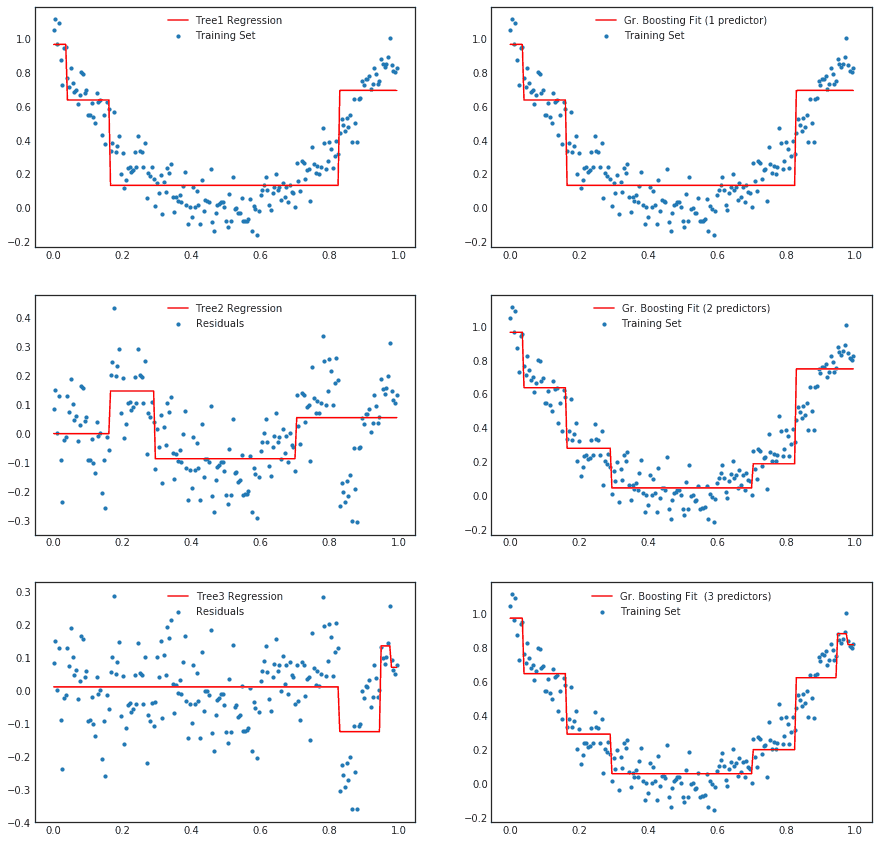
O processo funciona assim:
- Treina a primeira árvore nos dados originais
- Calcula os resíduos (erros) da primeira árvore
- Treina a segunda árvore para prever esses resíduos
- Repete o processo, sempre treinando a próxima árvore nos erros das anteriores
- A previsão final é a soma de todas as árvores
O algoritmo usa _Gradient Descent_ para minimizar a função de perda (_loss_) a cada nova árvore adicionada. Daí o nome “gradient” boosting.
O XGBoost adiciona otimizações importantes sobre o gradient boosting tradicional: regularização para evitar overfitting, poda inteligente de árvores, e paralelização que o torna muito mais rápido.
Implementando XGBoost com Python
Para mostrar na prática como implementar o XGBoost, vou usar a API do Kaggle para baixar o _dataset_ House Prices: Advanced Regression Techniques.

Se você não conhece a API Kaggle ou não quer usar ela, não tem problema! É só baixar o arquivo _zip_ diretamente do link acima.
Diferentemente do que fizemos no Projeto do Titanic, onde a análise foi completa, aqui o objetivo é mostrar a implementação do XGBoost apenas.
Não irei nem baixar todo o conjunto de dados, apenas um único arquivo: train.csv.
!mkdir -p data !kaggle competitions download -c house-prices-advanced-regression-techniques -f train.csv -p data
Importando e preparando os dados
Após importar o pacote Pandas, vou importar o arquivo _csv_ para dentro de um DataFrame.
Para você entender o _dataset_, vou listar as 5 primeiras linhas de entrada do modelo. Recomendo que você baixe o _notebook_ na tua máquina e faça o mesmo.
Se você estiver executando diretamente na sua máquina, pode ser que não tenha o pacote xgboost instalado. Nesse caso, instale pela linha de comando: pip install xgboost
# importar bibliotecas necessárias
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.impute import SimpleImputer
from xgboost import XGBRegressor
from sklearn.metrics import mean_absolute_error
# importar train.csv em DataFrame
df = pd.read_csv('data/train.csv')
# visualizar as 5 primeiras entradas
df.head()
A variável alvo é a coluna _SalePrice_. Para não termos que trabalhar as variáveis categóricas aqui, vou eliminar todas as colunas do tipo _object_ e ficar apenas com as numéricas.
Na sequência, vou separar o _DataFrame_ entre variáveis X e y, dividir entre conjuntos de treino e teste, e usar SimpleImputer() para lidar com os valores ausentes.
Se você tem dúvida sobre como lidar com valores faltantes, escrevi um artigo falando exatamente sobre isso.
# separar entre as variáveis X e y y = df['SalePrice'] X = df.drop(['SalePrice'], axis=1).select_dtypes(exclude=['object']) # dividir entre conjuntos de treino e teste train_X, test_X, train_y, test_y = train_test_split(X.values, y.values, test_size=0.2) # lidar com os valores ausentes df_imputer = SimpleImputer() train_X = df_imputer.fit_transform(train_X) test_X = df_imputer.transform(test_X)
Treinando o modelo XGBoost
Com os dados preparados, agora é a hora de construir o modelo. Seguindo o mesmo padrão do sklearn, depois de instanciar XGBRegressor() basta executar o método fit(), passando o _dataset_ de treino como argumento.
Na sequência, vamos realizar as previsões e calcular o erro médio absoluto para ver o desempenho.
# instanciar o modelo XGBoost
model = XGBRegressor()
# chamar o fit para o modelo
model.fit(train_X, train_y, verbose=False)
# fazer previsões em cima do dataset de teste
predictions = model.predict(test_X)
print("Erro Médio Absoluto: {:.2f}".format(mean_absolute_error(predictions, test_y)))
Construir um modelo é relativamente rápido comparado às outras etapas de um projeto. Mas tem um passo a mais que faz muita diferença nos resultados.
Ajustando hiperparâmetros do XGBoost
Você viu que implementar o XGBoost é simples. Mas será que é tão fácil conseguir aqueles resultados incríveis nas competições do Kaggle?
Com certeza, não. Se fosse assim, qualquer pessoa estaria no topo do _ranking_.

O XGBoost é extremamente robusto e poderoso, mas tem um grande número de parâmetros para serem ajustados. Os mais importantes são:
- n_estimators: número de árvores (mais árvores = mais capacidade, mas mais lento e risco de overfitting)
- max_depth: profundidade máxima de cada árvore (valores menores regularizam o modelo)
- learning_rate: taxa de aprendizado (valores menores = aprendizado mais gradual, geralmente melhores resultados com mais árvores)
- subsample: fração dos dados usada para treinar cada árvore (ajuda a evitar overfitting)
- colsample_bytree: fração das features usadas por árvore (similar ao Random Forest)
Para ajustar esses parâmetros, não tem escapatória. Você precisa entender a teoria por trás do XGBoost e experimentar diferentes combinações. Ferramentas como GridSearchCV e Optuna ajudam nesse processo.
XGBoost vs Random Forest vs LightGBM
Se você trabalha com dados tabulares, provavelmente já se perguntou: quando usar XGBoost, Random Forest ou LightGBM? Cada um tem suas forças.
| Aspecto | XGBoost | Random Forest | LightGBM |
|---|---|---|---|
| Tipo | Gradient boosting | Bagging (ensemble) | Gradient boosting |
| Velocidade | Rápido | Moderado | Muito rápido |
| Dados grandes (>100K linhas) | Bom | Bom | Excelente |
| Risco de overfitting | Médio (tem regularização) | Baixo | Médio-alto |
| Features categóricas | Precisa encodar | Precisa encodar | Suporte nativo |
| Facilidade de tuning | Muitos parâmetros | Poucos parâmetros | Muitos parâmetros |
| Interpretabilidade | Feature importance | Feature importance | Feature importance |
Quando usar cada um:
- XGBoost: sua escolha padrão para dados tabulares. Melhor equilíbrio entre performance e robustez. Funciona bem em datasets de qualquer tamanho.
- Random Forest: quando você quer um modelo rápido, estável e que não precisa de muito tuning. Bom como baseline.
- LightGBM: quando o dataset é grande (milhões de linhas) e velocidade importa. Comum em produção por ser mais rápido que o XGBoost.
Na prática, a diferença de performance entre os três é pequena na maioria dos problemas. O XGBoost continua sendo a escolha mais segura e a mais usada em competições e projetos de Data Science.
Takeaways
- XGBoost é o algoritmo padrão para dados tabulares. Combina árvores de decisão com gradient boosting para alcançar performance superior em problemas de classificação e regressão.
- O segredo está no boosting sequencial. Cada árvore nova corrige os erros das anteriores, e a regularização embutida evita overfitting.
- Implementação é simples. Com poucas linhas de código usando a API do sklearn, você treina e faz previsões. O desafio real está no ajuste de hiperparâmetros.
- XGBoost vs Random Forest vs LightGBM: XGBoost é o mais equilibrado, Random Forest é o mais estável, LightGBM é o mais rápido. Para a maioria dos problemas, qualquer um dos três funciona bem.
- Pratique com projetos reais. Competições do Kaggle são o melhor campo de treino. Comece replicando notebooks de outras pessoas e evolua a teoria conforme a necessidade.




















Que didática mais legal !!!!!