O desafio de Data Science (Ciência de Dados) do Titanic é uma das competições mais conhecidas dos cientistas de dados, e é promovida pelo site kaggle.com.
Tamanha popularidade desta competição fez com que ela fosse considerada como sendo um Hello, World! para o universo fantástico do Data Science .
Neste tutorial, damos início à análise exploratória de dados que termina com a construção de modelos de Machine Learning (Parte II). Para ver a continuação deste artigo:
[PARTE II – DESAFIO DO TITANIC]
Com certeza, a maioria de vocês conhece a história por trás do naufrágio deste que seria o navio mais moderno do mundo para a época. Apesar da tecnologia disponível, após colidir com um iceberg em 15 de abril de 1912, seu naufrágio matou 1502 pessoas de um total de 2224 passageiros.

Como principal fator contribuinte, logo se descobriu que não havia botes salva-vidas suficientes para toda a tripulação e passageiros, além de diversas atitudes irresponsáveis por parte da tripulação..
Obviamente, aqueles que sobreviveram à tragédia contaram com muita sorte, mas será que alguns grupos de passageiros não tiveram “mais sorte” que outros grupos? Será que crianças e mulheres realmente tiveram mais chances de sobreviver? Será que o Jack teve menos chances de escapar do seu destino trágico que a Rose, só pelo fato de ele ter embarcado na 3ª Classe?
Com os dados reais disponibilizados, agora você pode fazer uma análise exploratória, testar suas hipóteses e até mesmo construir um modelo preditivo (que tal descobrir quais seriam suas chances de sobrevivência na 1ª Classe se você tivesse viajado com sua esposa e filho?!).
Eu acho este um ótimo exemplo para uma introdução ao mundo da Ciência de Dados, e pretendo dividir toda a análise em 3 artigos diferentes, onde vamos entender o problema, explorar os dados e construir dois modelo de Machine Learning (Regressão Logística e Árvore de Decisão) para gerar previsões para nós.

Como estou escrevendo todo o código em um notebook do Jupyter, não faz sentido colocar todo o código aqui no blog. Para você entender o passo a passo, acesse o notebook com todo o código no repositório do Github clicando no botão acima.
Checklist do Cientista de Dados: Como começar?
Todo projeto de Data Science precisa seguir um framework, um fluxograma ou pelo menos um checklist com algumas etapas essenciais para se fazer uma boa análise.
Se a primeira coisa que você faz quando vai iniciar um projeto é criar de cara um notebook, importar os arquivos para um DataFrame e já sair escrevendo código, há grandes chances que você vai ficar perdido no meio da análise.

Existem diversos frameworks que podem ser usados, como o CRISP-DM (Cross Industry Standard Process for Data Mining) e outros. Servindo como um checklist para te balizar, eles dividem o ciclo de vida de um projeto de Data Science em etapas que são comuns a diversos problemas, dando mais agilidade e credibilidade ao seu trabalho.
Especificamente para este Projeto do Titanic, seguiremos as seguintes etapas ao longo dos três de artigos (e notebook):
- Definição do Problema
- Obtenção dos Dados
- Exploração dos Dados
- Preparação dos Dados
- Modelagem
- Avaliação
Você vai ver só como dividir um problema em etapas bem definidas vai te ajudar e tornar as análises mais robustas.
O objetivo deste desafio de Data Science é utilizar os dados disponíveis para medir a probabilidade de sobrevivência dos passageiros do Titanic.
1. Definição do Problema de Data Science
Muita gente prefere ir direto ao código e modelagem de seus problemas de Data Science, o que é um erro grave!
Já escutou aquela frase “para quem não sabe onde quer chegar, qualquer caminho serve”? Então, se você não gastar um tempo logo no começo para entender sobre o que o negócio se trata e qual o problema que se espera resolver, provavelmente você vai se perder em algum momento lá na frente.
No nosso caso, entender o problema (ou negócio) é pesquisar um pouco mais da historia do Titanic 🙂
A construção do Titanic levou cerca de 2 anos e custou 7,5 milhões de dólares (valores da época). Com 269 metros de comprimento, 28 metros de largura e 53 metros de altura, operava com uma tripulação de 892 pessoas e poderia levar até 2435 passageiros (espalhados pelas três classes disponíveis).
Pensado para ser o mais seguro e luxuoso navio da época, foi lançado ao mar em 1911, ganhando fama de ser “inafundável”.
O naufrágio do Titanic teve como fatores contribuintes causas naturais (como o clima) e causas humanas (negligência e excesso de confiança). Independente das causas, o fato é que seu naufrágio matou 1502 pessoas de um total de 2224 passageiros.
Embora aqueles que escaparam com vida tiveram sua boa dose de sorte, alguns grupos de pessoas eram mais propensos a escaparem da morte do que outros. Por exemplo, mulheres, crianças e passageiros da 1ª Classe. Assim, nota-se que existe algum padrão que pode ser extraído dos dados brutos.
A descrição completa da competição, assim como o conjunto de dados, está disponível na página do Kaggle Titanic: Machine Learning from Disaster.
Objetivo
Espera-se que você consiga fazer uma análise sobre quais variáveis tiveram maior influência na probabilidade de sobrevivência (ou seja, que tipo de pessoa teve mais chance de escapar com vida).
Após analisar os dados, espera-se também que você seja capaz de construir um modelo que dê a previsão de sobrevivência para um passageiro qualquer que seja fornecido como input.
Métrica de Desempenho
O score é calculado em relação ao número de previsões corretas que seu modelo fez. Ou seja, é considerada apenas a acurácia do modelo.
2. Obtenção dos Dados
Todo o material necessário está disponível no site da competição, com maiores detalhes e explicações. Os dados disponibilizados pelo Kaggle foram divididos em dois grupos:
- Dataset de treino (
train.csv)- Deve ser usado para construir o modelo de Machine Learning. Neste conjunto de dados, é informado se o passageiro sobreviveu ou não.
- Composto por diversas features como gênero do passageiro e classe do embarque.
- Dataset de Teste (
test.csv)- Deve ser usado como dados que nunca forma vistos pelo modelo. Neste conjunto de dados, não é informado se o passageiro sobreviveu ou não.
Para conseguir baixar os dados, é obrigatório fazer o cadastro no Kaggle antes.
Também é disponibilizado um modelo (gabarito) de como as previsões devem ser enviadas para a plataforma do Kaggle (gender_submission).
Como esta é uma competição introdutória, há poucas variáveis e entradas, além das inforções estarem bem pré-processadas. Para conseguir baixar os arquivos, é precisar criar um login no Kaggle antes.
3. Exploração dos Dados
Definitivamente, a etapa mais importante do projeto. É aqui que você vai gastar entre 70-80% do tempo total. Muitas vezes, as perguntas e hipóteses iniciais conseguem ser respondidas apenas com uma Análise Exploratória bem feita. Caso seja necessário construir um modelo, o desempenho do mesmo estará diretamente ligado à qualidade dessa análise. Nesta etapa você irá:
- Estudar cada atributo e suas características, tais como:
- Nome
- Tipo (numérica, categórica, float, int, etc)
- % de valores faltantes para cada coluna
- Presença de ruído ou outliers
- Tipo de distribuição (Gaussiana, uniforme, logarítmica,)
- Identificar a variável alvo
- Identificar correlações
- Visualizar os dados graficamente
Como se trata de um Aprendizado Supervisionado (Supervised Learning), a variável Survived é facilmente identificada como sendo a nossa variável alvo (target). De grande importância, vamos construir agora um dicionário de dados, para saber exatamente qual o significado de cada coluna.
Dicionário de Dados
- PassengerId: Número de identificação do passageiro
- Survived: Informa se o passageiro sobreviveu ao desastre
- 0 = Não
- 1 = Sim
- Pclass: Classe do bilhete
- 1 = 1ª Classe
- 2 = 2ª Classe
- 3 = 3ª Classe
- Name: Nome do passageiro
- Sex: Sexo do passageiro
- Age: Idade do passageiro
- SibSp: Quantidade de cônjuges e irmãos a bordo
- Parch: Quantidade de pais e filhos a bordo
- Ticket: Número da passagem
- Fare: Preço da Passagem
- Cabin: Número da cabine do passageiro
- Embarked: Porto no qual o passageiro embarcou
- C = Cherbourg
- Q = Queenstown
- S = Southampton
Pronto! Feito isso, vamos começar a fazer alguns questionamento e formular hipóteses.
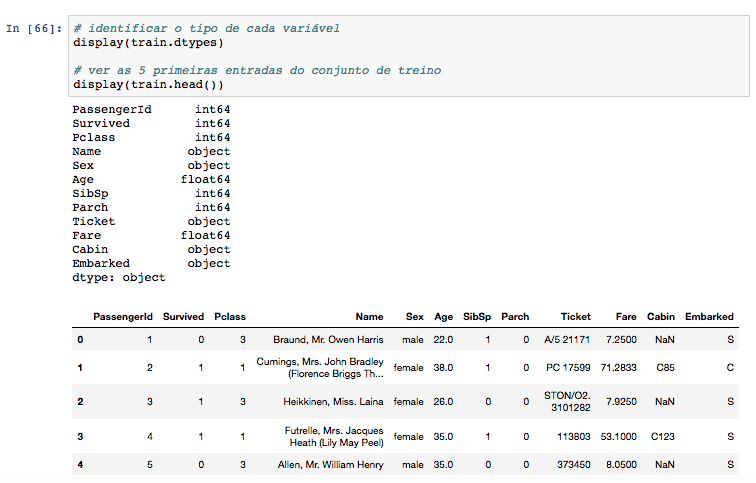
Quais os tipos de cada variável?
Já sabemos o que cada coluna representa, então vamos dar uma olhada nas primeiras entradas e ver quais variáveis são numéricas e quais são categóricas.
Qual a porcentagem de valores faltantes?
A informação sobre a Cabin é a que possui o maior número de informações faltantes, com mais de 77%. Após, a coluna Age não possui valor em quase 20% dos passageiros. Por fim, a coluna informando o Porto de embarque (Embarked) possui apenas 2% de informações faltantes.
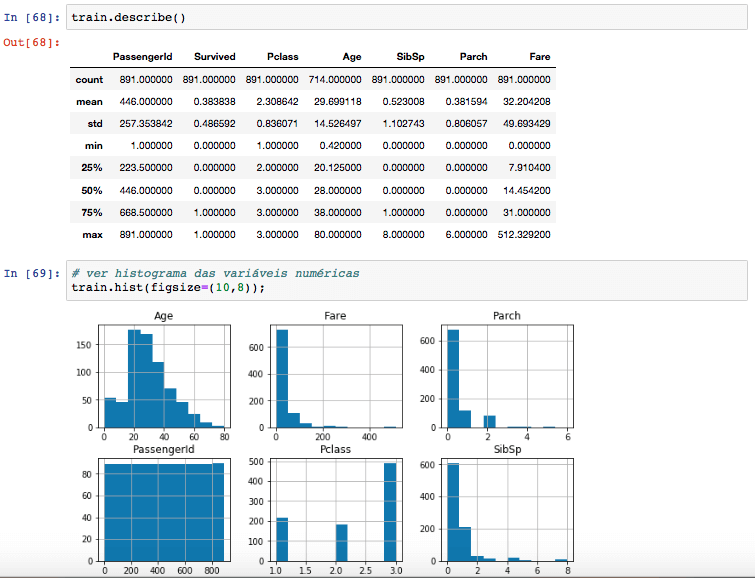
Como é a distribuição estatística dos dados?
Usar o método describe()do Pandas e plotar um histograma vai dar uma visão geral a respeito da distribuição de cada variável e sobre posisveis outliers e valores faltantes. Isso vai ser muito útil na próxima etapa, quando iremos trabalhar a limpeza dos dados e decidir se vamos excluir uma entrada que tenha um valor faltante ou preencheremos com a média/mediana, por exemplo.
Quais grupos de pessoas tinham mais chances de sobrevivência?
Aqui já podemos testar uma hipótese lá do começo do artigo: Será que as mulheres de fato tem mais chance de sobreviverem ao naufrágio do Titanic? Vale a pena olhar as correlações e relacionamentos entre as variáveis, seja para decidir quais entrarão em um modelo futuro ou para formular novas hipóteses.
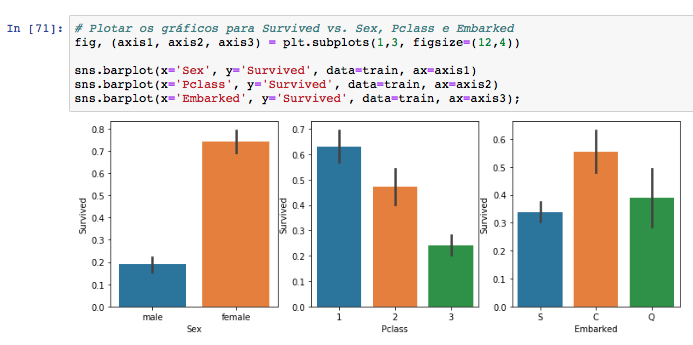
Pelo gráfico acima já conseguimos confirmar duas suposições iniciais:
- Mulheres tem muito mais chance de sobreviverem que os homens (75% vs. 18%)
- Passageiros da 3ª Classe tem menos da metade de chance de escaparem do desastre que aqueles passageiros que estão na 1ª Classe.
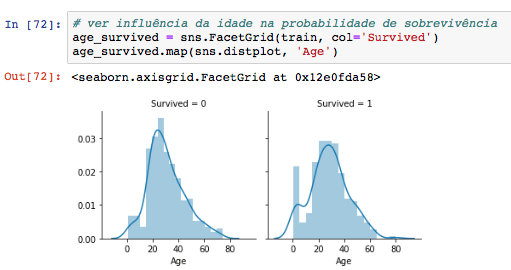
Ao analisar também a distribuição das idades dos sobreviventes e mortos, dá para ver um pico no lado dos sobreviventes para crianças pequenas. O comportamento dos dois gráficos é bem parecido, mas esse detalhe é bem importante pois confirma a hipótese que crianças também tem maior chance de sobreviverem: “Crianças e mulheres primeiro”. Trago também um tipo de gráfico bem interessante do Pandas: scatter_matrix. Sabe o que é bacana nesse tipo de visualização abaixo?
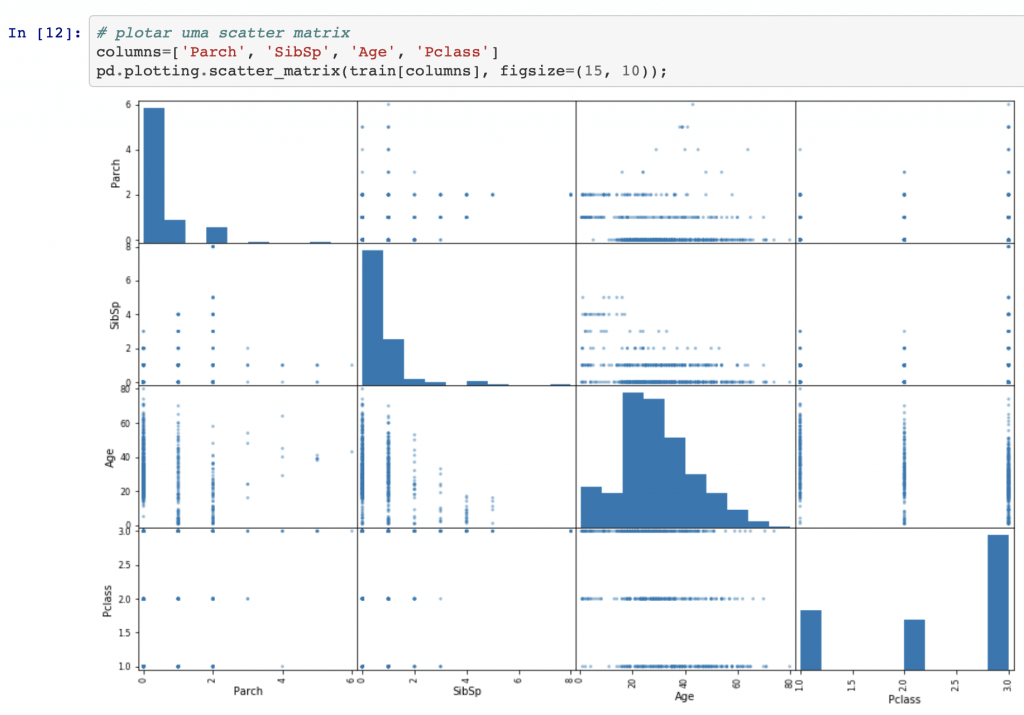
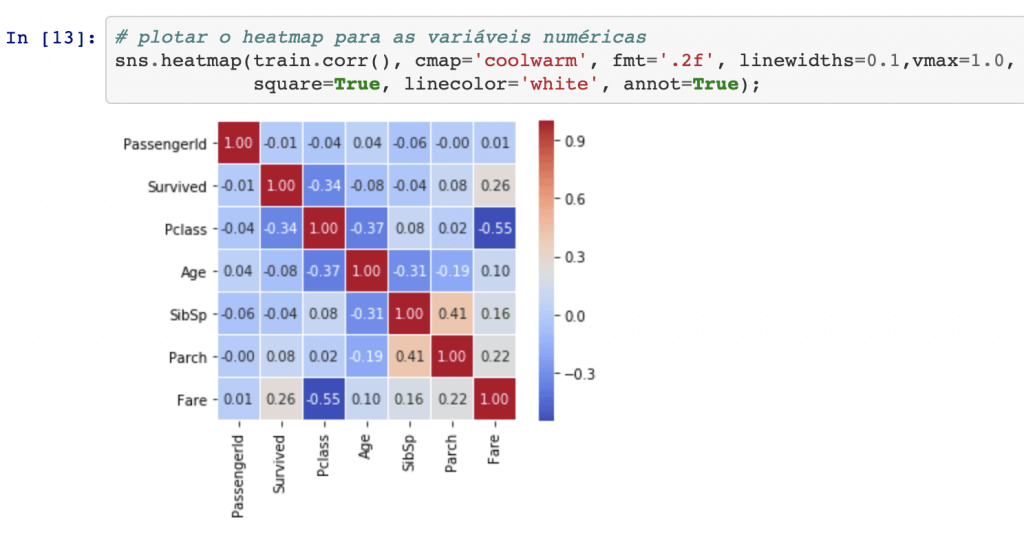
A vantagem desse tipo de gráfico é que a diagonal dele traz informação útil, exibindo um histograma de cada atributo (outras opções estão disponíveis). Rapidamente a gente consegue ver coisas como – por exemplo – o fato de que pessoas mais velhas estão mais concentradas na 1ª Classe e pessoas mais jovens na 3ª classe. Por fim, terminando esta primeira etapa de análise exploratória, vamos dar uma olhada no heatmap para entender como as variáveis estão correlacionadas, positiva ou negativamente.
Por enquanto é só isso na Parte I. No próximo artigo, vamos evoluir nossa análise e dar uma olhada mais detalhada nas variáveis categóricas. Também vamos falar sobre como lidar com valores faltantes (NaN) e preparar os dados para alimentar o nosso modelo.
Resumo
Nesta Parte I do nosso projeto de Data Science, conseguimos tomar consciência da situação, entender o problema, entender as principais variáveis e começar a visualização das variáveis numéricas.
Muitos acabam negligenciando esta etapa inicial, preferindo partir logo para a etapa de feature engineering ou modelagem em si, escolhendo atributos sem critério algum – e tendo desempenhos ruins, enviesados ou com overfitting.
Se você quer ter sucesso nas análises, aprenda a documentar bem seus projetos, detalhando o máximo possível cada etapa em um notebook – lembre-se que tudo tem que ser replicável por qualquer pessoa – e seguindo uma metodologia, um framework!
Na Parte II do artigo, vamos trabalhar as variáveis categóricas, limpar dados e tratar informações faltantes, e começar a preparar nosso modelo preditivo, onde testaremos técnicas de Regressão Logística.
Se você ficou com alguma dúvida, clique no link abaixo para acessar o notebook completo (com todo o código), baixe ele e comece a rodar na sua própria máquina, faça testes e teste suas próprias hipóteses 🙂

E se você está começando na área, parabéns! Você está no caminho certo da profissão do futuro, aprendendo como se tornar um Cientista de Dados. Para não perder a continuação deste artigo, inscreva-ser com seu email abaixo, e receba a notificação antes dos outros!




















Muito boa sua explicação. Estou com problemas na linha 71 para gerar os gráficos do seaborn, esta dando erro, já atualizei o pacote, reiniciei o Kernel do jupyter notebook e nada. O que pode ser este problema? Obrigado!
Excelente artigo!
foi um viagem sensacional de analise de dados.
Muito bom o artigo, parabéns