O Processamento de Linguagem Natural (Natural Language Processing – NLP) é um campo da Inteligência Artificial desenvolve a capacidade de máquinas entenderem a nossa linguagem. Mais que apenas “entender”, com a NLP é possível interpretar frases, realizar análises semânticas ou analisar sentimentos.

O campo é gigante e promissor. Técnicas de Machine Learning aplicadas à análise de dados permitem coisas como:
- Identificar se uma avaliação feita em um livro na Amazon foi positiva ou negativa;
- Identificar sintomas de depressão em pessoas a partir de suas postagens em redes sociais como Facebook ou Twitter;
- Encontrar potenciais eleitores favoráveis a um determinado candidato; e
- Identificar os relacionamentos entre os personagens da série Game of Thrones com base na transcrição dos diálogos.
Neste artigo, meu objetivo é apresentar a área da NLP e técnicas de Text Mining usando Python para que você conheça as possibilidades e potencialidades de uso.

Como Estudo de Caso, escolhi analisar o empreendedor que mais admiro na atualidade (no Brasil e no mundo): Rony Meisler, fundador e CEO da Reserva.
Rony Meisler e Reserva
Rony Meisler é o nome que está por trás de uma das maiores marcas do segmento da moda: a Reserva. Engenheiro de Produção por formação, abandonou sua carreira bem estabelecida na Accenture para empreender – iniciativa que deu origem à Reserva.
O sucesso é inquestionável: ao longo de 15 anos, a empresa evoluiu de uma venda de bermudas entre amigos, para uma estrutura que fatura mais de R$ 400 milhões ao ano.
Se você já assistiu qualquer entrevista do Rony, já conhece aquele jeito descolado, com um perfil comportamental muito mais balanceado para o lado das emoções.

A magnitude com que consegue transmitir sua liderança, paixão e mindset, gera uma conexão imediata. Seu estilo de gestão baseado no “The Why”, o propósito, tornaram-no referência para toda uma geração – incluindo eu e minha esposa.
Mas não é apenas a empresa Reserva que é inovadora. Na verdade, a Reserva pode ser considerada como uma personificação da própria personalidade do Rony Meisler.
Mais do que “apenas” empresário, ele é um comunicador e influenciador nato. Tanto é que foi eleito como um dos Top 10 Voices do LinkedIn, ao lado de nomes como Luiza Trajano, Mario Cortella e Ricardo Amorim.
Os principais fatores que me levaram a escolher o Rony para o Estudo de Caso é (além do fato de eu ser seu grande fã) a vasta quantidade de material disponível para aplicar NLP e Text Mining. Presença forte em redes sociais, comunicação emocional e intensa e um livro de autoria própria são fatores ideais para o propósito deste projeto.
Rebeldes Têm Asas
Rebeldes Têm Asas foi definitivamente o melhor livro brasileiro sobre empreendedorismo que li na vida, principalmente pelo fato de não ser apenas sobre empreendedorismo.
Na verdade, se trata de uma narrativa pessoal, contanto detalhes de família, carreira e visões do mundo. Por trazer tantas opiniões e pensamentos pessoais, este livro é um ótimo material para se aplicar técnicas de mineração de texto.
Como tenho o livro físico original, extraí o texto contido no livro digital única e exclusivamente para este Estudo de Caso. Por este motivo, não irei compartilhar o código-fonte do projeto, uma vez que isso significaria distribuir conteúdo de terceiros.
Uma vez que extraído o conteúdo do livro, importei o arquivo para uma listra de strings no Python e criei uma pipeline para verificar a frequência de palavras usadas pelo Rony em sua narrativa.
Importante lembrar de remover as stopwords da análise. Stopwords são palavras comuns que não trazem sentido, porém poluem a Nuvem de Palavras (não, para, pra, há, a, entre outras). Para gerar as stopwords usei a biblioteca nltk e fiz o download das base de dados das palavras em português da seguinte maneira:
# importar a biblioteca nltk
import nltk
# baixar a base de stopwords
nltk.download('stopwords')
# atribuir as stopwords (em português) à variável
stopwords = nltk.corpus.stopwords.words('portuguese')
# acrescentar algumas stopwords
stopwords.extend(["pra", "tá", "Assista", "vídeo"])
Após importar as palavras do livro para uma estrutura de lista, removi os espaços e linhas em branco indesejados, e criei uma wordcloud com a biblioteca wordcloud.

Na figura acima, extraí a frequência das palavras. Sem surpresa, ‘Reserva’ foi a palavra mais frequente do livro. No entanto, palavras como “pessoa”, “vida”, “cliente” e “amigo” também estão entre as mais relevantes da obra.
Para facilitar o entendimento e gerar insights, criei uma wordcloud em cima do logo da marca Reserva, um Pica-Pau. A visualização facilita o entendimento, e isso pode ser comprovado ao olhar o resultado dessa nuvem relativa ao livro “Rebeldes Têm Asas”:
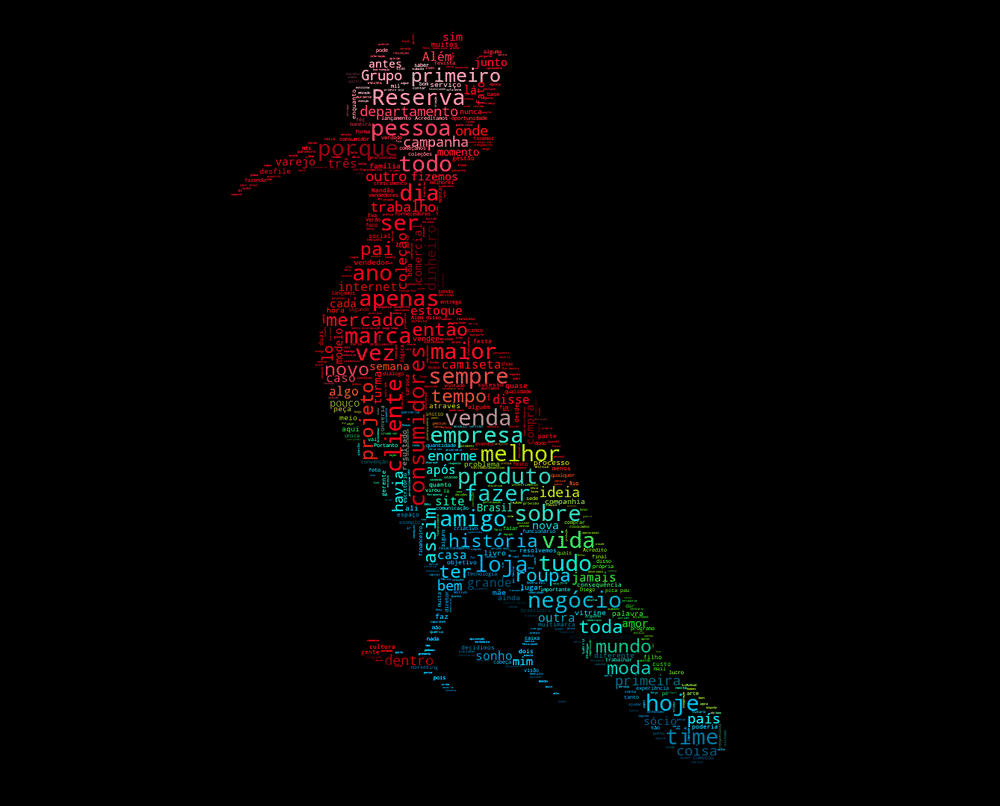
Se você tem curiosidade a respeito desse tipo de visualização, recomendo que leia este artigo meu explicando o passo-a-passo sobre como criar wordclouds.
NPL para análise do perfil no Instagram
Existem diversas ferramentas disponíveis para Python classificação de sentimentos. Para este projeto, usei tanto a nltk quanto a API Natural Language do Google.
Essa API usa Machine Learning para extrair informações sobre lugares, pessoas, entender conversas e identificar o sentimento do conteúdo, e foi uma das melhores ferramentas que conheci nos últimos tempos.
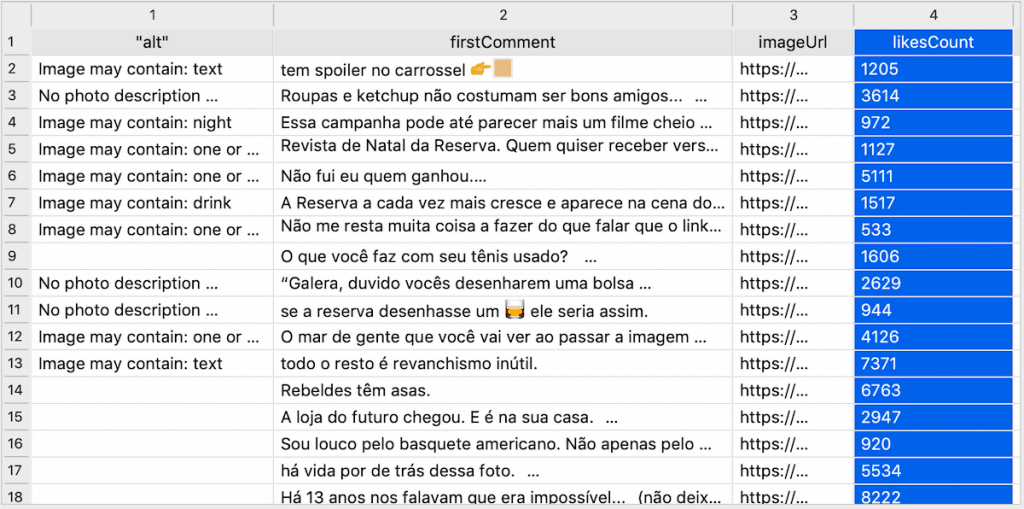
Para poder usar a API, antes fiz um scraping das postagens do perfil @rony no Instagram. Na imagem abaixo você pode ver os dados raw, sem nenhum tipo de tratamento.
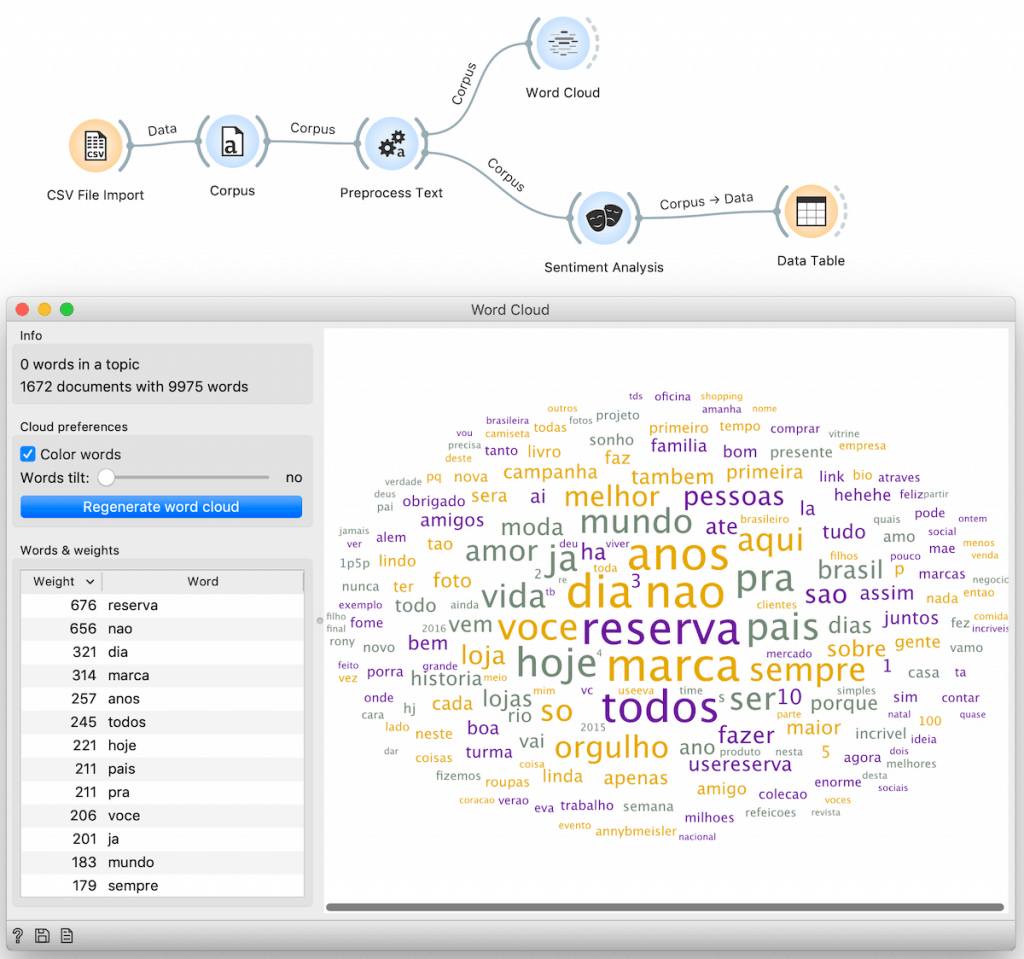
Assim, segui com a limpeza das strings, removi caracteres inúteis e normalizei o texto. Tudo isso foi possível graças a uma uma pipeline feita com o auxílio do Orange Framework.
O próximo passo foi analisar o sentimento geral das postagens do Rony e confirmar a hipótese que o mesmo tem um estilo de liderança mais emocional – e que provavelmente deve refletir nos comentários e postagens de redes sociais.
Veja na imagem abaixo como a API Google Natural Language classificaria a frase “Eu estou muito feliz hoje! Estou amando ainda mais minha esposa!”. Repare os dois valores que retornam da função: 0.699 (score) e 1.5 (magnitude).

Para classificar corretamente o sentimento de textos, é necessário interpretar esses dois valores. Enquanto o score representa o sentimento geral do conteúdo (positivo ou negativo), a magnitude indica com quanta emoção ele foi escrito. Resumidamente:
- Score: indica o range do sentimento, onde
-1.0representa o limite de um sentimento negativo e1.0o limite de um sentimento positivo. - Magnitude: Indica a força geral da emoção classificada no score. Diferente do score, a magnitude não é normalizada e varia entre os intervalos de
0.0e+inf.
O que eu fiz no Estudo de Caso foi aplicar a função acima para cada postagem do Rony Meisler e salvar os resultados individuais em um DataFrame do Pandas. Configurar a API não é trivial e foge do escopo deste artigo. Para aprender a usá-la recomendo seguir este tutorial.

Das 1.670 postagens do Instagram que foram analisadas, a média de 0.37 no score e 1.05 na magnitude confirmam a visão que temos do empreendedor e influenciador Rony. Ou seja, que suas publicações são de sentimento positivo e com uma carga emocional identificada pelo algoritmo de NLP.
Para dar mais um exemplo de como NLP pode ajudar a extrair informações de textos, vamos olhar as 5 postagens mais positivas do Rony. Como mostra a figura abaixo, filtrei valores acima de 0.8 para o score e 1.0 para a magnitude.
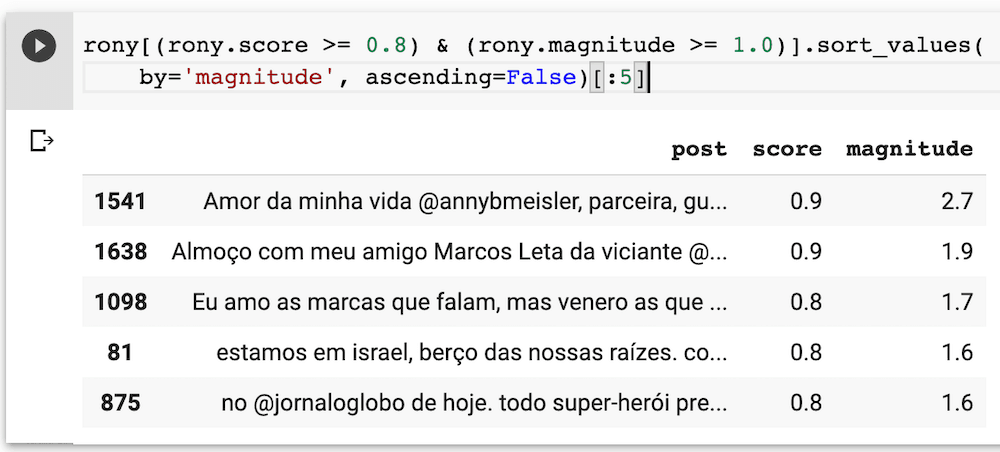
Quem acompanha o CEO da Reserva sabe do seu amor declarado constantemente pela sua esposa, família e por Israel (sim, a Reserva é judaica). Confirmando essa visão, o algoritmo de Inteligência Artificial classificou essas postagens como sendo aquelas que têm o sentimento mais positivo entre todas.
“Amor da minha vida @annybmeisler, parceira, guerreira, delicia. Amo eternamente. Happy Valentine!”
“estamos em israel, berço das nossas raízes. com nossos filhos, nossas asas para a eternidade. lugar perfeito para celebrar o nosso amor!! a @annybmeisler é muito mais do que a minha namorada. é a minha vida. te amo, princesa. “
@rony
Conclusão
Trouxe aqui algumas abordagens de text mining e NLP usando puramente Python. Para exemplificar e mostrar na prática, trouxe um Estudo de Caso envolvendo o empreendedor e CEO da Reserva, Rony Meisler.
Uma vez que usei conteúdo com direitos autorais que não me pertencem, obviamente não irei publicar o projeto completo. Entretanto, saiba que mais importante que o próprio código (ou fontes usadas) é você identificar e conhecer as potencialidades de Data Science na área da Linguagem Natural (NLP).
Rony é o empreendedor no qual eu e minha esposa nos inspiramos atualmente – ela com sua marca de sapatos femininos e eu com o Sigmoidal. Acompanhar o trabalho desse cara fantástico e criativo tem sido um fator de motivação para mim.
Eu amo a Reserva, e admiro demais seu trabalho – por isso que resolvi colocá-lo como tema central do artigo. Um dia ainda espero poder ter sua mentoria ou pelo menos alguns minutos de conselhos.
Ou aliás, quem sabe um dia o próprio Rony não resolve contar pra gente como é usada Data Science dentro da Reserva!


















Ótimo trabalho, Carlos!
Obrigado, Jonathan! Valeu mesmo pelo feedback.
Excelente artigo! abriu um leque de possibilidades na minha mente. Obrigado!
Excelente texto explicação clara e objetiva.