O desafio de Data Science (Ciência de Dados) do Titanic é uma das competições mais conhecidas dos cientistas de dados e é promovida pelo site kaggle.com.
Neste tutorial, daremos continuidade à análise exploratória de dados que começamos na Parte I desta série. Se você ainda não viu o primeiro post, dê uma olhada, pois eles são sequenciais:
[PARTE I – DESAFIO DO TITANIC]
Já entendemos o problema, olhamos os dados e visualizamos gráficos. Agora vamos tratar os dados para deixá-los prontos para os nossos dois modelos de Machine Learning: Regressão Logística e Árvore de Decisão.
Para facilitar o seu aprendizado, disponibilizei todo o código no meu Github, onde você pode copiar a vontade. Recomendo ir lendo este post com o Jupyter notebook do lado. É só clicar no botão abaixo:

4. Preparação dos Dados
Até o presente momento, tudo o que fizemos foi importar os dados para estruturas DataFrame, formular hipóteses, iniciar uma análise exploratória dos dados e visualizar graficos e correlações entre aquelas variáveis que julgamos pertinente.
Um projeto de data science não é amarrado e rigoroso, onde a gente segue um passo-a-passo linear, mas sim um processo interativo, onde a gente vai e volta sempre que for necessário.
Quando a gente pega o notebook de alguém, fica sempre a impressão que está bem estruturado e que foi “direto ao ponto”. No entanto, antes de trazer uma versão bonitinha, eu vou e volto ao começo inúmeras vezes!
Lembre-se disso: uma versão final é uma versão que foi reescrita várias vezes. Vá e volte ao começo sempre que precisar para adicionar informações novas que fizeram sentido 🙂
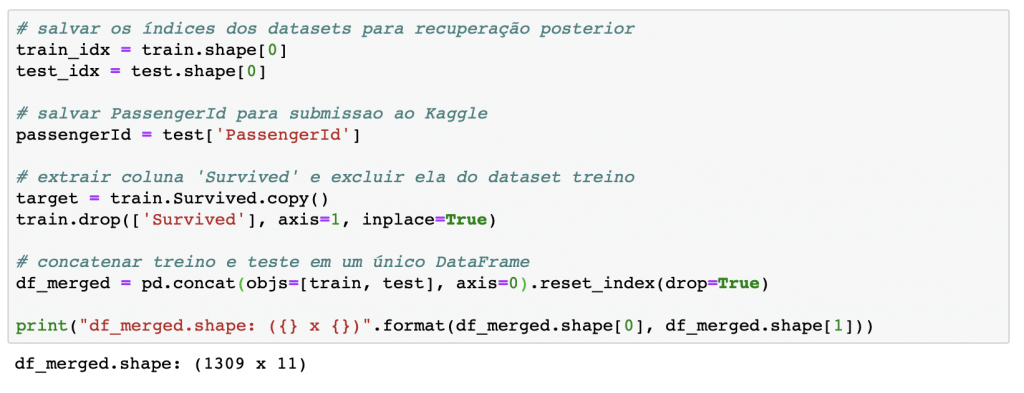
Juntando os datasets de treino e teste
Uma dica para quando você vai preparar os dados para um modelo de Machine Learning é juntar os datasets de treino e teste em um único, e separar novamente no final.
Muitas vezes a gente vai fazer um feature engineering, criar variáveis dummy ou codificar as variáveis. Daí, nosso modelo vai ser treinado em cima dessa arquitetura, e os dados de teste vão ter que seguir essa mesma estrutura.
Por isso, é muito mais fácil fazer todas as etapas para um único DataFrame e dividir novamente entre treino e teste.
Selecionar as features
Como qualquer conjunto de dados do mundo real, você vai se deparar sempre com dados que não servem para nada e outros que não tem peso ou significância nenhuma no seu modelo. Muitas vezes nosso julgamento pode ser equivocado, mas, infelizmente, é papel seu, como cientista de dados, escolher quais features serão usadas para o modelo de Machine Learning. No nosso caso, vamos desconsiderar as variáveis ['PassengerId', 'Name', 'Ticket', 'Cabin'], pois aparentemente não parecem relevantes.

Assim, ficamos com as seguintes variáveis a serem tratadas e preparadas: ['Pclass', 'Sex', 'Age', 'SibSp', 'Parch', 'Fare', 'Embarked'].
Valores faltantes
Vamos dar uma olhada nos valores que faltam em cada coluna e tratar esses campos vazios. Normalmente, há duas abordagens mais utilizadas quando a gente encontra missing values:
- Preencher esses valores arbitrariamente (média, mediana, valor mais frequente);
- Excluir a linha inteira.
Cada caso é um caso e novamente você, cientista de dados, é quem vai tomar a decisão sobre qual passo seguir. Na maioria das vezes, não é desejável jogar informação de uma linha inteira só por causa de um campo faltando. Sempre que possível é melhor você preencher o campo, e é isso que vamos fazer.
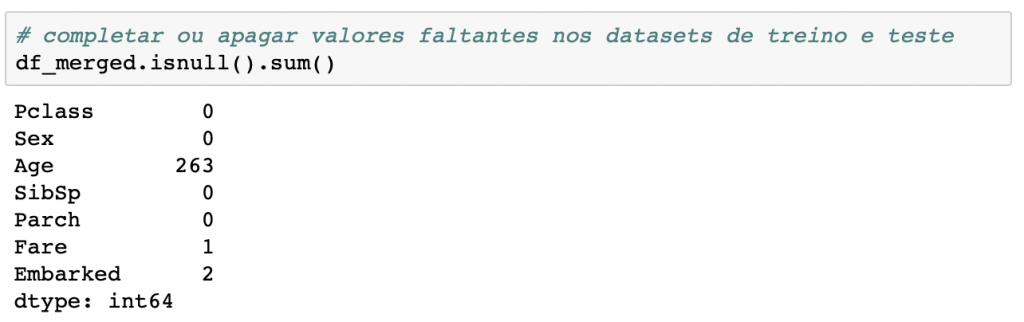
Para as variáveis idade e tarifa, vou colocar o valor da mediana; e para a variável do porto de embarque, vou colocar o valor com maior frequência.

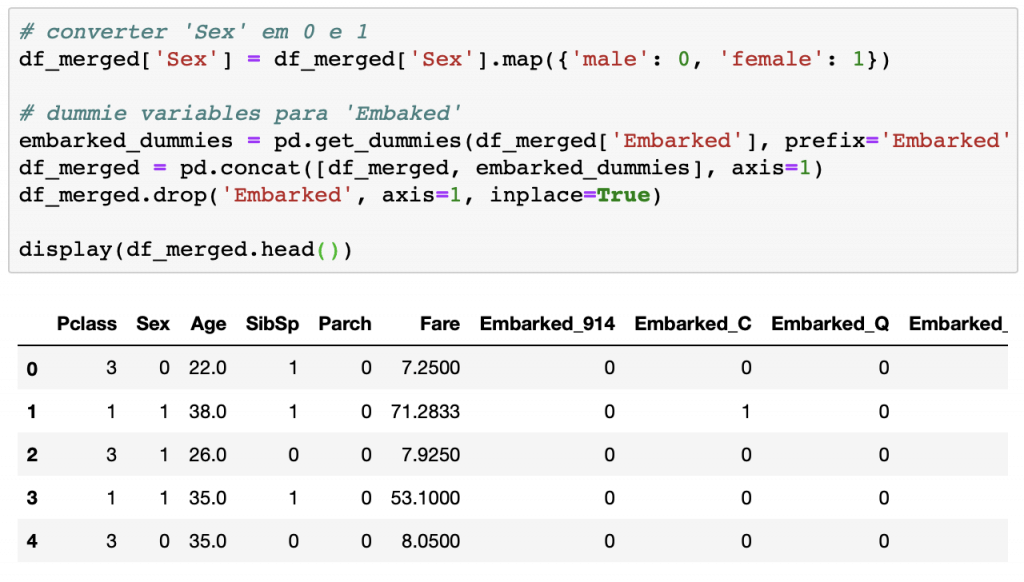
Preparar as variáveis pro modelo
O modelo matemático exige que trabalhemos com variáveis numéricas, ou seja, temos transformar os dados de entrada que estão em formato categoria para números. Como você vê abaixo, eu convertir os valores possíveis de Sexpara {'male': 0, 'female': 1}. Já em relação à variável Embarked, apliquei o conceito de variáveis dummies. As variáveis dummies (dummy variables) assumem aqui apenas valores 0 e 1, criando uma nova coluna para cada valor possível da variável categórica. Para ficar mais fácil entender, veja como fica o DataFrame após todos esses tratamentos:
Recuperando os datasets de treino e teste
Aqui a gente acabou de preparar o dataset para o modelo e vou dividir df_merged em traine test, exatamente como era no começo. Agora você consegue entender a razão da concatenação lá em cima. Teríamos trabalho dobrado e ainda teria o risco de errarmos em alguma etapa.

O objetivo deste desafio de Data Science é utilizar os dados disponíveis para medir a probabilidade de sobrevivência dos passageiros do Titanic.
5. Construção do Modelo e Avaliação
Eu vivo falando no meu Instagram que a etapa mais demorada de qualquer projeto de Data Science é a Análise Exploratória de Dados e a preparação/tratamento deles.
Todo cuidado que tivemos serviu para entender o problema, testar hipóteses e descartar dados desnecessários/redundantes. Graças a todo esse esforço, com poucas linhas de código a gente consegue criar e otimizar modelos de Machine Learning básicos. Aqui, vamos construir dois:
Modelo de Regressão Logística
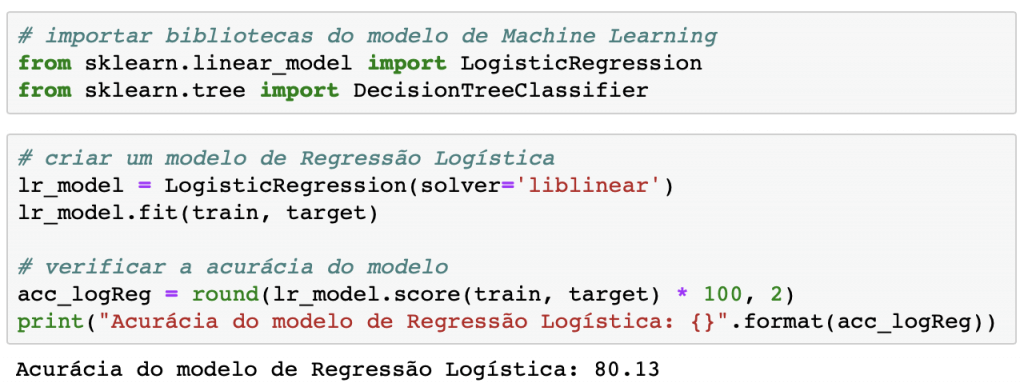
Com praticamente duas linhas, construímos um modelo de Regressão Logística com acurácia de 80% em cima do conjunto de dados de treino.
Importante você saber que após chamar o método .fit(), o algoritmo vai otimizar a função-objetivo do problema e armazenar os pesos “ideais” dentro da própria variável, virando um atributo dela.
A própria previsão é feita na sequência, chamando o método predict() do objeto criado.
Modelo de Árvore de Decisão (Decision Tree)

Da mesma maneira, facilmente criamos um modelo, achamos a curva (fit) em cima dos dados de treino e verificamos a acurácia dele. Um pequeno ganho na acurácia, chegando agora a quase 83%, sem muito esforço e apenas escolhendo outro modelo.
Chega de brincadeira. Temos os pesos que os algoritmos de Machine Learning encontraram e vamos fazer a primeira participação “oficialmente” no desafio.
Submetendo os resultados ao Kaggle
Jogo é jogo e treino é treino.
Não teria como acabarmos por aqui sem validar os resultados, o que significa realizar as previsões para o dataset de teste, exportar as previsões para um arquivo csv e enviar pro Kaggle.
Não fique chateado se o resultado do jogo for inferior ao do seu treino. Não é incomum termos desempenho inferior quando submetemos as previsões, pois nosso modelo foi treinado 100% em cima do conjunto de treino (aqui isso significa que ele tem um fit bem melhor ao dataset train).

Como eu disse, o nosso resultado foi levemente abaixo quando submetido ao Kaggle.
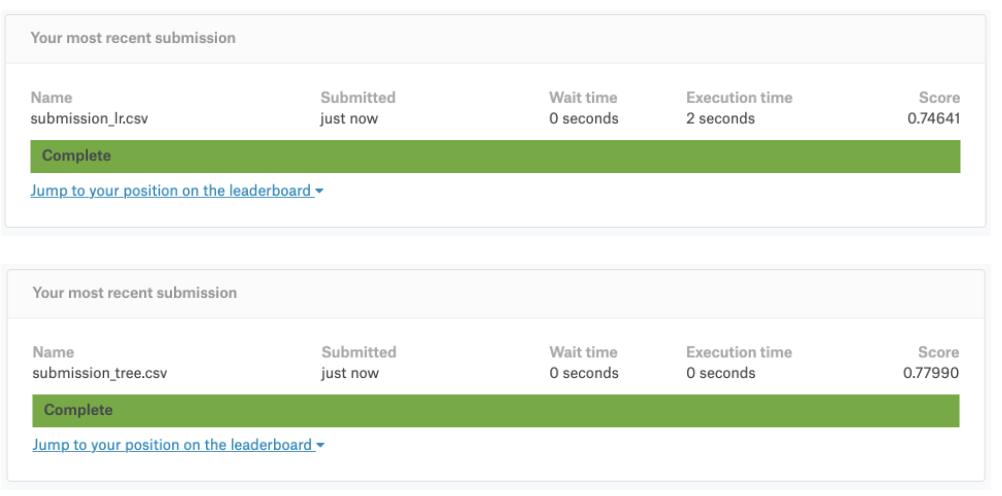
Conforme você evolui como cientista de dados, você começa a aplicar métodos e ferramentas para minimizar esse tipo de diferença. Entretanto, esse resultado está ótimo para um modelo inicial. Atingir quase 80% de acurácia no seu primeiro desafio é louvável e motivador!
Mais importante de tudo é sempre você aproveitar o processo, cada etapa do projeto. Estar empolgado e motivado é a chave do sucesso nesta carreira 🙂
Você sobreviveria ao Titanic?
Se você já se questionou alguma vez se teria sobrevivido ao desastre do Titanic, finalmente você pode obter uma resposta!
No meu caso, uma vez que o modelo está treinado e com boa acurácia, resolvi checar se eu e minha esposa sobreviveríamos ao naufrágio do Titanic, colocando-nos como passageiros viajando na 2ª Classe, eu com 35 anos e ela com 30, acompanhados do nosso bebê Theo, tendo pago o preço médio do Ticket e embarcados no porto de Southampton (Reino Unido).
Vamos criar dois vetores contendo os valores de cada variável e passar estes como argumento do método predict().

Infelizmente, de acordo com meu próprio modelo, eu não teria sobrevivido ao desastre do Titanic. Já minha esposa foi classificada como sobrevivente. Parece que a realidade retratada no filme de James Cameron traz algumas verdades 🙁
Espero que tenha aproveitado este artigo e consiga replicar no seu computador. O desafio do Titanic é a melhor escolha para quem está começando no Data Science, e já abre sua mente para outros tipos de problemas 🙂
Que tal agora checar se você teria sobrevivido e compartilhar o resultado no Instagram, marcando meu perfil?
Ah, se você está começando na área, não se esqueça de se inscrever na lista de e-mail para receber conteúdo exclusivo sobre Data Science e sobre a carreira de cientista de dados 🙂


















Olá Carlos, gostaria de tirar uma dúvida contigo no índice Valores Faltantes, você comenta que
para as variáveis idade e tarifa, você utiliza o valor da mediana para atribuir o valor obtido nos valores faltantes.
# age
age_median = df_merged[‘Age’].median()
df_merged[‘Age’].fillna(age_median, inplace=True)
# fare
fare_median = df_merged[‘Fare’].median()
df_merged[‘Fare’].fillna(fare_median, inplace=True)
Porém não seria válido, por exemplo, para a idade utilizar a média para ter tal informação, visto que a partir do dado Name eu consigo o título atribuído à aquele passageiro? Assim consigo tirar a média das idades sobre aquele Título e atribuir assim ao passageiro?
Para a tarifa, também questiono devido a já termos a Pclass do passageiro com a informação ausente e assim também realizar a média do mesmo, atribuindo assim o valor correspondente.
Com as informações que você atribuiu a acurácia fica em torno de 80%, porém fazendo essa substituição utilizando a média (mean) a acurácia fica em torno de 60% para os modelos
Poderia me esclarecer sua linha de análise para estes dados?