A visualização de dados é uma parte fundamental do Data Science, e deve estar presente no kit de qualquer cientista de dados que esteja querendo tirar insights valiosos de seus bits.
Um data scientist pode usar gráficos basicamente para duas finalidades distintas:
- Para explorar os dados durante a fase da Análise Exploratória; e
- Para comunicar os resultados aos stakeholders e decisores (decision-makers).
Mais do que saber construir modelos de Machine Learning e extrair previsões a partir de dados passados, você precisa melhorar cada vez mais sua habilidade de produzir visualizações úteis e que melhorem a qualidade do seu projeto.
Saber qual tipo de gráfico usar para cada situação vai fazer muita diferença, tanto para testar as hipóteses levantadas quanto transmitir aos outros aquilo que você descobriu.
Hoje vou trazer um dos principais gráficos usados em todas as fases de uma Análise de Dados, o HISTOGRAMA! Para ver como usar esse tipo de gráfico, vou aplicar o gráfico em cima da pesquisa anual de desenvolvedores do Stack Overflow com os resultados de 2018.

Para ir acompanhar o código deste artigo e conseguir replicar exatamente os resultados, acesse o notebook com todo o código no repositório do Github clicando no botão acima.
Pesquisa de desenvolvedores do Stack Overflow
Todo ano, o site Stack Overflow realiza uma pesquisa com os desenvolvedores do site, capturando aspectos demográficos, linguagens preferidas e características pessoais das pessoas.

O Stack Overflow foi criado por Jeff Atwood e Joel Spolsky em 2008, e é referência absoluta quando se trata de programação, desenvolvimento e tecnologia da informação. Por meios dos seus fóruns, você encontra as melhores respostas para qualquer dúvida sobre seu código.
No ano de 2018, o survey recebeu dezenas de milhares respostas, o que foi considerada como maior pesquisa já feita com desenvolvedores na época. Todos os dados coletados estão disponíveis neste link e podem ser baixados.
Neste artigo, vou mostrar apenas como criar criar um Histograma em Python em cima de um Banco de Dados qualquer. Entretanto, se você se empolgar com esses dados, pode fazer uma análise mais profunda e publicar o resultado (que tal começar um projeto similar à análise do Desafio do Titanic?).
É característica de uma pessoa realmente inteligente ser movida pela estatística.
GEORGE BERNARD SHAW
Visualizando Dados em Data Science
Como é característico da linguagem Python, você sempre vai ter inúmeras opções de ferramentas para qualquer coisa que quiser fazer, algumas mais famosas e outras menos.
Da mesma maneira, para a visualização de dados também existe uma grande variedade de opções. Atualmente, a ferramenta mais usada pelos cientistas de dados é o matplotlib, que é simples e vai direto ao ponto.

Quando você precisar de uma biblioteca mais nova, com mais estilos de visualização e gráficos mais bonitos (para apresentar resultados em um paper ou relatório para os Diretores da empresa, por exemplo, vale a pena conhecer também o seaborn.
Seaborn é construído em cima do próprio matplotlib, e te dá a possibilidade de produzir visualizações mais completas e agradáveis aos olhos. No nosso caso, vamos importar as duas bibliotecas 🙂
Analisando os dados do Stack Overflow
Na primeira etapa, vamos baixar os dados da survey realizada pelo Stack Overflow em csv, importar o arquivo em um DataFrame e visualizar as primeiras entradas.
# importar pacotes
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import urllib.request
import os
# URL com os dados da survey do Stack Overflow
DATA_URL = "https://s3.amazonaws.com/video.udacity-data.com/topher/2018/February/5a8cb654_survey-results-public/survey-results-public.csv"
def get_survey_data(data_url=DATA_URL):
"""
Baixa os dados da survey do Stack Overflow.
Parâmetros:
data_url <string>: Endereço do arquivo csv com a survey do Stack Overflow
Retorna:
None
"""
csv_file = data_url.split(os.sep)[-1]
if not os.path.isfile(csv_file):
urllib.request.urlretrieve(DATA_URL, 'survey-results-public.csv')
print("[+] Arquivo baixado...")
else:
print("[+] O arquivo '{}' já existe na pasta...".format(csv_file))
# baixar os dados do Stack Overflow
get_survey_data()
# importar os dados do arquivo csv para um DataFrame no Pandas
df = pd.read_csv('survey-results-public.csv')
# verificar as primeiras entradas do DataFrame
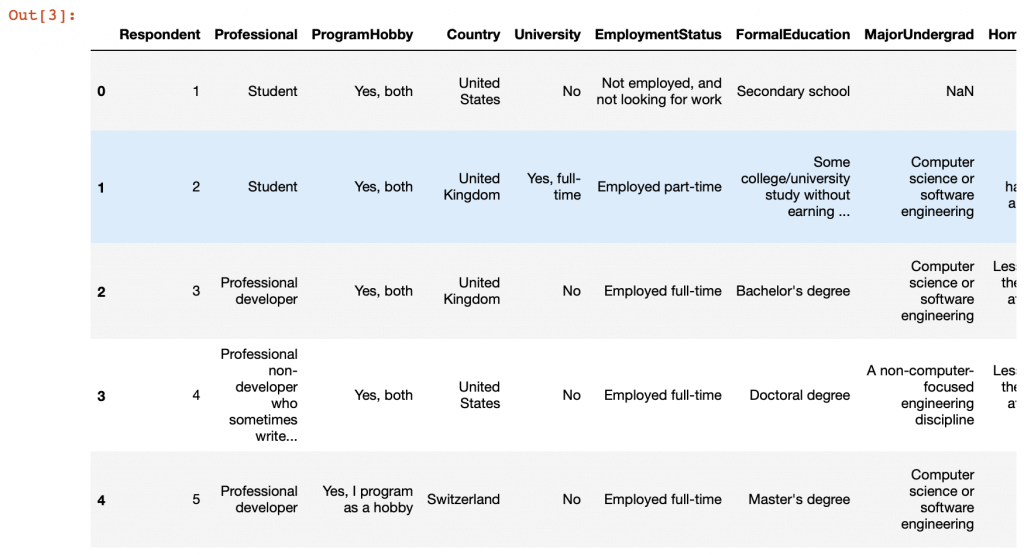
df.head()
Como o arquivo tem 154 colunas e 51392 linhas de entrada, não é possível ver todas as informações na imagem abaixo, por isso recomendo (de novo) você clonar o notebook e rodar na sua própria máquina!
Agora que temos um DataFrame com todas as informações, vamos escolher uma coluna ideal para ser plotada em formato de histograma e uma para usarmos o boxplot.
Como usar um Histograma?
Resumidamente, um histograma é um gráfico de distribuição de frequência, e que permite analisar visualmente como uma amostra/população está distribuída.
Como nosso cérebro humano tem dificuldade de processar grandes volumes de dadoss, uma das melhores abordagens quando você pega um dataset qualquer é plotar a distribuição das variáveis numéricas a fim de criar um conhecimento inicial.
Sem saber nada sobre a variável ‘Salary’, veja como só olhar o histograma facilita o trabalho.
# plotar o histograma do Salário dos desenvolvedores df['Salary'].hist();
Como você viu aí em cima, para plotar o histograma de qualquer variável basta selecionar ela dentro do DataFrame e chamar o método hist() e ver seu gráfico aparecer na tela.
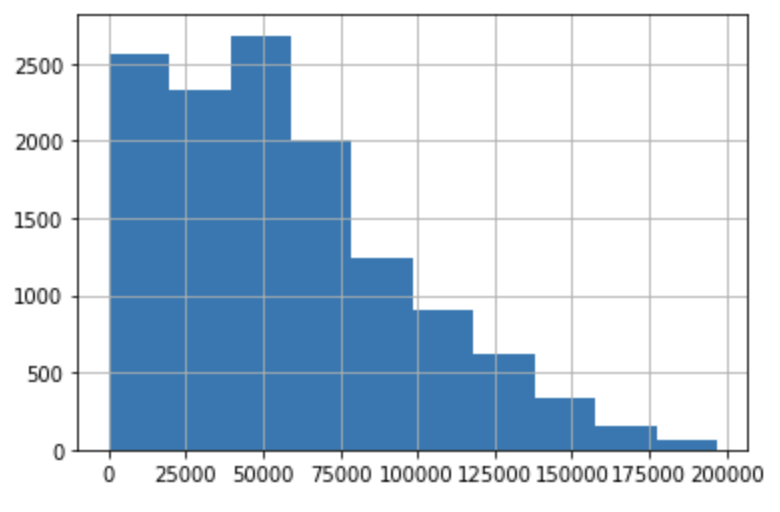
Só olhando o gráfico acima ja podemos inferir que há uma maior frequência de salário na faixa dos $50 mil dólares entre todos os desenvolvedores que responderam ao questionário.
Também vemos que o gráfico não é simétrico, pois a maior parte dos desenvolvedores tem seus salários concentrados na esquerda do gráfico. Isso significa que um desenvolvedor médio pode esperar seu salário entre 25 mil e 60 mil dólares aproximadamente.
Também é fácil ver que muitos poucos desenvolvedores tem salários acima de 100 mil Trumps.
Resumo
Quando estamos fazendo uma análise de dados, provavelmente vamos nos deparar com milhares de linhas e centenas de colunas. Infelizmente nosso cérebro não consegue entender aquelas letras e números.
Nós, seres humanos, conseguimos entender as coisas bem mais facilmente quando vemos uma imagem ou figura.
Quando você for começar a trabalhar no seu projeto de Data Science durante a etapa de análise de dados, recomendo você plotar o histograma das variáveis e analisar sua distribuição. Essa etapa simples vai criar uma consciência situacional que vai te ajudar muito.
Obviamente, apenas o histograma não basta, mas serve como um excelente começo para formular aquelas hipóteses iniciais 🙂
E se você está começando na área, parabéns! Você está no caminho certo da profissão do futuro. Conheça mais sobre a carreira de Cientista de Dados, uma das que tem mais demanda nesta década.
Ah, e para estar sempre por dentro e sabendo tudo do universo de Data Science, inscreva-se abaixo com seu email, e receba todo o material de altíssima qualidade no conforto da sua inbox!
















Achei esse conteúdo excelente. Foi muito útil pra mim!
ótimo conteudo! como todos da sigmodal. Tenho aprendido muito aqui. Obrigado, mestre!
Muito obrigado pelo comentário!