Dados ausentes são uma das maiores dificuldades da etapa exploratória dos dados em um projeto de Data Science.
Durante a fase em que estamos aprendendo, lendo livros e seguindo tutoriais, não temos tanto esse tipo de trabalho, pois os dados já vêm mais “redondinhos”.

Entretanto, essa não é a realidade do mundo real, em que a gente vai se deparar com uma infinidade de problemas e missing data.
Excluir, completar ou ignorar?! Qual a melhor abordagem? Hoje nós vamos falar sobre as principais técnicas para lidar com dados ausentes e entender o trade-off entre elas.
Para ver o código completo, acompanhar este artigo ou testar no seu computador, acesse meu Github no botão abaixo.

Ah, seguindo uma promessa antiga que eu vivia fazendo no Instagram, resolvi começar um canal no YouTube!
Agora você pode acompanhar este artigo em formato de vídeo também. Aproveite e já se inscreva por lá 🙂
Identificando dados ausentes
Algoritmos de Machine Learning não são capazes de lidar com valores ausentes (missing data). Se você já tentou rodar, viu que a mensagem de erro é bem clara em relação a isso.

Um valor ausente é facilmente identificado nos campos da sua estrutura de dados como NaN. Para seu modelo rodar sem problemas, você tem que limpar, em uma etapa anterior, os dados (data cleaning). É aí que surge a dúvida: o que eu faço com eles?
Não existe uma resposta 100% correta, pois cada abordagem tem suas vantagens e desvantagens, mas vamos dar uma olhada naquelas que são mais usadas.
Para isso, vamos importar um conjunto de dados do Kaggle para usar como exemplo.
Importando os dados
Vou usar o conjunto de dados House Prices: Advanced Regression Techniques neste exemplo, pois ele apresenta várias colunas com valores inexistentes.
Nesse dataset, temos 80 variáveis (colunas) e 1.460 entradas (linhas) no arquivo train.csv. Eu vou baixar apenas esse arquivo e vou usar a (Kaggle API)(https://www.kaggle.com/docs/api), uma vez que ela me permite baixar o arquivo diretamente do Terminal.
Se você não conhece a API, olhe a documentação no Github [https://github.com/Kaggle/kaggle-api]. Aprender a usar essa API vai ajudá-lo muito, não apenas pela facilidade, mas porque deixa seu notebook replicável para quem o clonar.
!mkdir -p data
!kaggle competitions download -c house-prices-advanced-regression-techniques -f train.csv -p data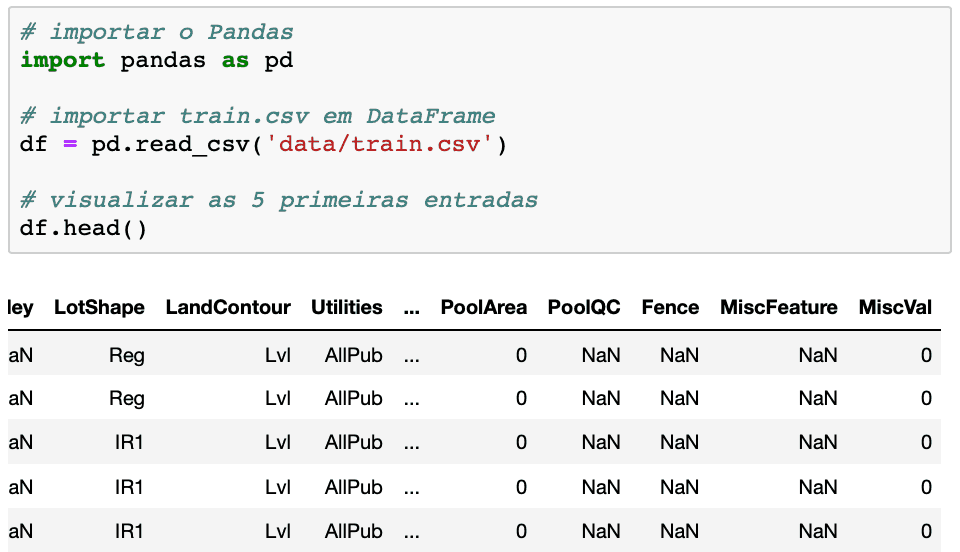
Identificando dados ausentes
A primeira coisa que você tem que saber quando lida com um conjunto de dados novos é a quantidade e proporção dos missing values.

Para identificar valores ausentes, por colunas, você pode usar:
df.describe()para retornar um resumo estatístico das variáveis numéricasdf.info()para dar um resumo de valores não nulos encontradosdf.isnull().sum()para retornar a soma dos valores nulos encontrados
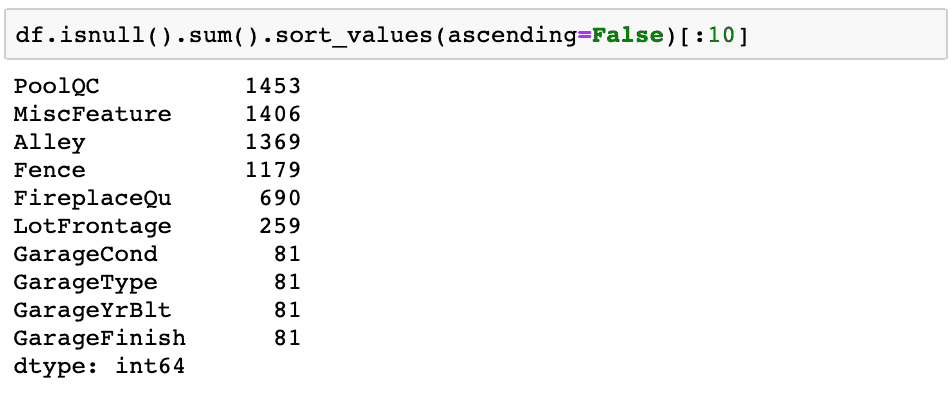
Usando essa última opção, vamos ver as 10 colunas com mais valores ausentes para esse dataset.
Lidando com dados ausentes
Como eu falei lá em cima, não existe uma resposta 100% correta ou 100% errada sobre como você deve tratar os valores ausentes do seu conjunto de dados.
Toda escolha gera uma renúncia. Você tem que estar ciente disso e testar o que vai se adequar melhor àquela situação.
Vou passar aqui alguns dos métodos mais frequentementes usados por cientistas de dados, e como você poderia aplicar esses métodos nos dados que acabamos de importar.
Excluir valores ausentes
Esta é uma decisão mais radical, e deve ser feita apenas em casos em que não haverá impacto significativo no modelo. Ao eliminar uma linha inteira, você joga fora um monte de informação que poderia ser extremamente importante.
Eu uso essa opção apenas quando meu dataset é consideravelmente grande e a quantidade de valores ausentes é relativamente insignificante.

Para fazer isso, você vai usar o método df.dropna(). Esse método é direto e remove os valores NaN encontrados no DataFrame.
Por padrão, se você não informar o eixo, serão eliminadas todas as linhas relativas à celula contendo o valor ausente (df.dropna(axis=0)).
Caso você deseje eliminar uma coluna inteira em que existam NaN, você deve informar explicitamente com df.dropna(axis=1)
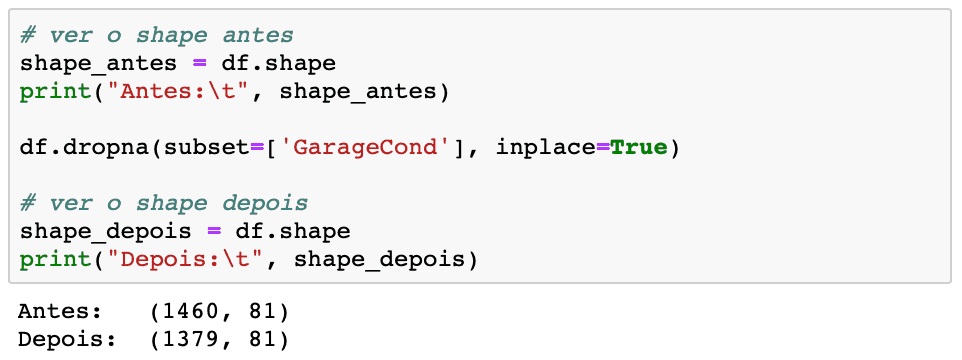
No exemplo abaixo, todos os valores NaN da coluna GarageFinish serão eliminados. Compare o shape antes e depois.
Preencher valores ausentes
Esta abordagem é a mais utilizada, pois você não joga fora informação útil. Aqui, a dúvida que você vai ter é em relação a qual valor usar para preencher os dados faltantes.

Existem técnicas avançadas que são combinadas com o preenchimento de valores, como, por exemplo, analisar correlações ou mesmo construir um modelo preditivo para missing values.
Entretanto, uma abordagem direta e simples consiste em substituir os NaN pela mediana da coluna. Isso é feito mediante o método df.fillna(), informando o valor desejado como argumento.
Vamos extrair a mediana da coluna LotFrontage e preencher os valores faltantes com ela.

Usar valor mais frequente
Para preencher missing values no último exemplo, usamos a mediana da coluna. Entretanto, caso a variável fosse categórica (e não numérica), poderíamos verificar qual o valor mais frequente e usar ele no preenchimento.
Para identificar o valor mais frequente, basta usar o método value_counts(), extrair o maior valor e informar esse como argumento de fillna().

Como você pode aplicar esses métodos e melhorar suas análises de Data Science?
Eu vivo falando, no meu Instagram, sobre a importância da fase de análise de dados em um projeto de Data Science.
Aquilo que diferencia um cientista de dados é a sua capacidade de entender, explorar e tratar os dados da melhor maneira possível.
Em datasets reais, não tenha dúvida de que você vai se deparar com muita inconsistência, lançamentos errados, bases diferentes e muitos valores ausentes.
Saber o que fazer com esses valores vai aumentar muito o desempenho do seu algoritmo de Machine Learning e os seus resultados.
Aproveite para começar a aplicar os métodos que você viu aqui nos seus projetos. Que tal testar esses métodos com os dados do Desafio do Titanic?




















Boa tarde, excelente o conteúdo, apesar de ser iniciante no python, aprendi muito com ele.
Porém, no meu caso gostaria de somar os valores de duas colunas de preços do DataFrame e gerar uma coluna com o valor Total.
Eu fiz da seguinte forma inicialmente: dataframe[‘valor total’] = dataframa[‘valor1’] + dataframe[‘valor2’], porém o retorno foi NaN em todas as linhas da nova coluna, pois em cada linha existe um NaN ou para valor1 ou para valor2, então eu percebi que quando se tem um valor NaN o pandas desconsidera todos os outros e o resultado é NaN. Por exemplo: 5,0 + NaN = NaN, gostaria de saber como faço para o Pandas interpretar o NaN como 0(zero) e fazer com que 5,0 + NaN = 5,0 para eu poder ter o valor total correto.
Parabéns pelo conteúdo, muito didático, obrigada!
Muito legal
Mas uma dúvida, depois que eu tratei os dados
Como chama4 este no datafrane no pandas?
Então, normalmente você estará trabalhando com uma cópia do DataFrame, e alterando aquela linha/coluna especificamente. Algumas vezes, por meio de um apply() com uma função, por exemplo.