A avaliação de modelos de classificação em Machine Learning é uma etapa crítica para determinar o quão bem o modelo está se comportando na tarefa de prever as classes das amostras.
Existem diversas métricas de avaliação disponíveis para medir o desempenho de modelos de classificação. Aqui, exploraremos algumas das métricas mais comuns, incluindo a Acurácia, a Precisão, o Recall, a F1-Score e a Área sob a Curva ROC (AUC-ROC).
Vamos analisar cada uma dessas métricas e e aprender como calculá-las.

Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Acurácia
A Acurácia é uma métrica simples e amplamente utilizada que mede a proporção de previsões corretas feitas pelo modelo. A fórmula para calcular a acurácia é:
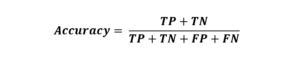
A acurácia é fácil de entender e interpretar, mas pode ser enganosa em conjuntos de dados desbalanceados, onde uma classe é muito mais comum do que a outra.
É necessário ter muita atenção ao utilizar essa métrica, por sua simplicidade. Dependendo da natureza do seu problema e do custo do erro, pode ser melhor avaliar e otimizar seu modelo a partir de uma outra métrica.
Precisão
A Precisão é uma métrica que mede a proporção de previsões positivas feitas pelo modelo que estão corretas.
Ela é especialmente útil quando o custo de falsos positivos é alto. Ou seja, ter um falso positivo é um grande problema. Um exemplo clássico disso seria classificação de emails entre Spam e Normais.
É preferível deixar um Spam ir para a Caixa de Entrada (Falso Negativo) do que mandar um email importante para a caixa de Spam (Falso Positivo).
A fórmula para calcular a precisão é:

Recall (Sensibilidade)
O Recall, também conhecido como Sensibilidade, mede a proporção de exemplos positivos que foram corretamente identificados pelo modelo.
Ele é especialmente útil quando o custo de falsos negativos é alto.
Aqui, o problema é o oposto do Precision. Um exemplo clássico seria a identificação de fraudes em cartão de crédito.
É preferível bloquear uma transação autêntica (Falso Positivo) do que aprovar uma transação fraudulenta (Falso Negativo).
A fórmula para calcular o recall é:
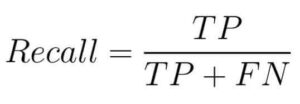
F1-Score
O F1-Score é a média harmônica entre a Precisão e o Recall e fornece um equilíbrio entre essas duas métricas. Ele é útil quando você deseja levar em consideração tanto os falsos positivos quanto os falsos negativos.
A fórmula para calcular o F1-Score é:

Área sob a Curva ROC (AUC-ROC)
A AUC-ROC é uma métrica que avalia o desempenho de modelos de classificação binária em diferentes limites de decisão.
Ela mede a área sob a curva da Taxa de Verdadeiros Positivos (Recall) em função da Taxa de Falsos Positivos.
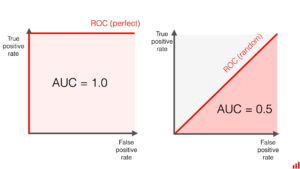
Quanto maior a AUC-ROC, melhor o modelo está em separar as classes.
Um valor de AUC-ROC de 0,5 indica um desempenho aleatório, enquanto um valor de 1 indica um desempenho perfeito, como podemos ver nas imagens abaixo.
Escolhendo a Métrica Certa
A escolha da métrica depende do problema específico e dos requisitos do projeto. Se você está lidando com um problema de classificação binária equilibrada, a acurácia pode ser uma métrica adequada.
No entanto, em problemas desequilibrados ou quando os custos de falsos positivos e falsos negativos são diferentes, outras métricas, como precisão, recall ou F1-Score, podem ser mais apropriadas.
A AUC-ROC é útil para avaliar modelos em diferentes limiares de decisão.
As métricas de avaliação em modelos de classificação desempenham um papel fundamental na medição do desempenho do modelo e na escolha do modelo final.
É importante entender as nuances de cada métrica e escolher aquela que melhor atende aos objetivos do SEU projeto.


















