Em Machine Learning, alcançar o equilíbrio perfeito entre um modelo que é muito simples e um modelo que é muito complexo é uma tarefa desafiadora, mas fundamental.
Isso nos leva a dois conceitos críticos: underfitting e overfitting. Vamos explorar o que esses termos significam, como eles estão relacionados e como o princípio do Bias-Variance Tradeoff nos ajuda a navegar nesse desafio.

Inscreva-se na Newsletter
Receba artigos sobre Data Science e IA direto no seu email.
✓ Inscrito com sucesso!
Underfitting
O underfitting ocorre quando um modelo simples demais para capturar a complexidade dos dados.
Isso resulta em um desempenho insuficiente, pois o modelo não consegue se ajustar adequadamente aos padrões presentes nos dados de treinamento.
Graficamente, um modelo em underfitting tende a apresentar um alto erro tanto nos dados de treinamento quanto nos dados de teste.
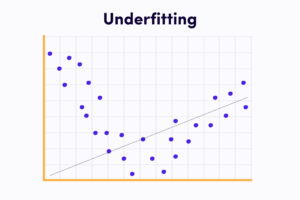
Uma possível causa de underfitting é a escolha de um modelo muito simples, com poucos parâmetros ou uma capacidade limitada para modelar relações complexas.
Por exemplo, tentar ajustar um modelo linear a dados não lineares pode levar ao underfitting.
Overfitting
Por outro lado, o overfitting ocorre quando um modelo é excessivamente complexo e se ajusta muito bem aos dados de treinamento, mas não consegue generalizar bem para novos dados.
Isso resulta em um desempenho ruim nos dados de teste, pois o modelo “decorou” os exemplos de treinamento em vez de aprender padrões significativos.
Graficamente, um modelo em overfitting apresenta um erro baixo nos dados de treinamento, mas um erro alto nos dados de teste.
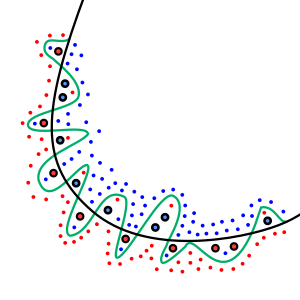
O overfitting pode ser causado por modelos excessivamente complexos, como árvores de decisão profundas ou redes neurais com muitas camadas e neurônios.
Também pode ocorrer quando o conjunto de treinamento é muito pequeno em relação à complexidade do modelo. No geral, é uma boa ideia considerar o tamanho do seu conjunto de dados ao tentar se livrar do overfitting.
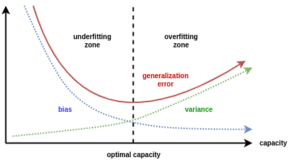
Bias-Variance Trade-off
O princípio do Bias-Variance Trade-off é um conceito-chave para lidar com underfitting e overfitting.
Ele sugere que existe um equilíbrio entre o viés (bias) e a variância (variance) do modelo que afeta seu desempenho. Vamos entender esses termos:
– Viés (Bias): Refere-se à simplificação feita pelo modelo em relação à realidade. Modelos com alto viés tendem a fazer suposições simplificadoras sobre os dados e, assim, podem underfit (errar em subestimar) padrões complexos.
– Variância (Variance): Refere-se à sensibilidade do modelo a pequenas flutuações nos dados de treinamento. Modelos com alta variância podem capturar até mesmo o ruído nos dados e, assim, podem overfit (errar em superajustar) os dados de treinamento.
O objetivo é encontrar um equilíbrio entre bias e variance, onde o modelo seja capaz de capturar os padrões relevantes nos dados, mas ainda generalize bem para novos dados não vistos.
Isso envolve escolher modelos adequados em termos de complexidade e tamanho do conjunto de treinamento.
Encontrando o Equilíbrio
Encontrar o equilíbrio entre underfitting e overfitting é um desafio. Isso envolve a seleção adequada do modelo, a otimização de hiperparâmetros, o aumento do tamanho do conjunto de treinamento e a validação cruzada.
Uma técnica comum para encontrar o ponto ideal é usar a curva de aprendizado, que mostra como o erro de treinamento e o erro de validação mudam à medida que o tamanho do conjunto de treinamento aumenta.
O objetivo é identificar o ponto onde os erros de treinamento e validação convergem, indicando que o modelo está aprendendo bem os padrões dos dados sem overfitting ou underfitting.
Encontrar o equilíbrio certo entre bias e variance é essencial para construir modelos que generalizem bem para novos dados e sejam eficazes na solução de problemas do mundo real.



















