Trabalhar com modelos deep learning ou de redes neurais convolucionais (convolutional neural networks – CNN) significa ter que lidar com grandes massas de dados, que chegam facilmente a ordem de gigabytes (ou até terabytes). Não há como escapar disso.
De fato, treinar um modelo de deep learning (DL) não é uma tarefa trivial. Muitas arquiteturas modernas podem chegar a ter milhões de parâmetros diferentes e receberem imagens de altíssima resolução como input.
Imagine um data dataset composto por imagens hiperespectrais (HSI) coletadas por satélites de sensoriamento remoto. Enquanto câmeras comuns capturam imagens em três canais distintos (RGB), um sistema hiperespectral tem resoluções que variam entre 100-1000 canais de espectro contínuo (ou mais).
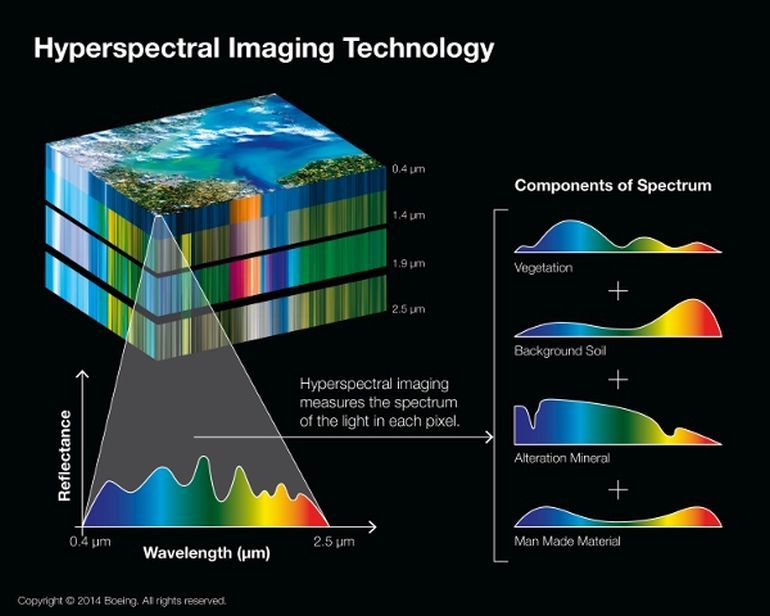
Dificilmente datasets desse tamanho conseguirão ser processados eficientemente na memória da nossa máquina. Ou seja, para trabalhar com volumes grandes de dados é preciso encontrar uma maneira eficiente e fácil de fazê-lo.
Bem, vamos falar hoje então sobre o modelo de dados HDF5, que vai possibilitar você manipular gigabytes de dados como se estivesse usando um simples array do NumPy.
Afinal, o que é HDF5?
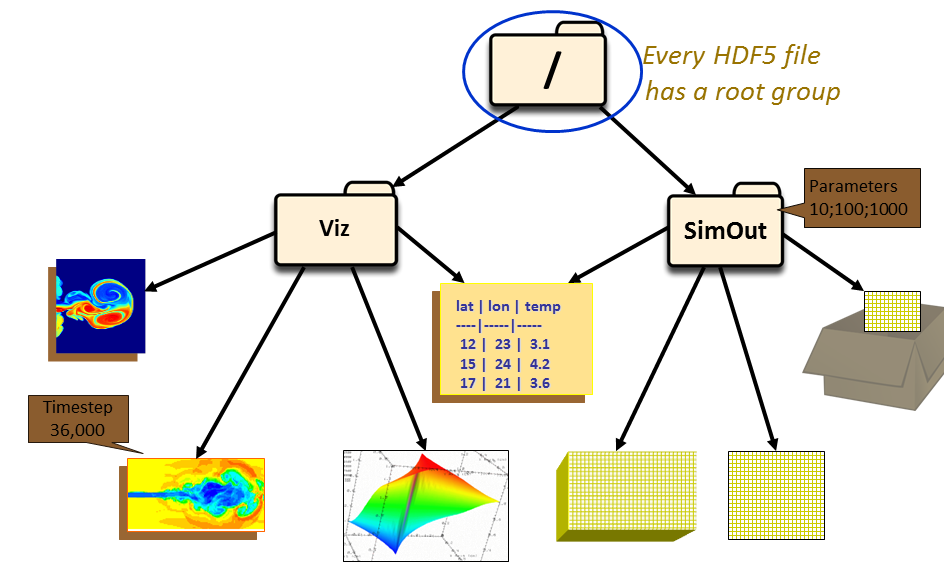
Resumidamente, HDF5 é um modelo de dados que permite que seu conteúdo possa ser facilmente manipulado – mesmo quando o tamanho do dataset ultrapassa os gigabytes.
Baseado em estruturação hierárquica de dados, é um formato muito usado em machine learning e na comunidade acadêmica. Para você acessar as linha (rows) do conjunto de dados, basta usar uma sintaxe de slices, que já estamos acostumados.
O pacote h5py torna muito prática e intuitiva a implementação desse modelo de dados. Por utilizar “metáforas” como NumPy arrays e estrutura de mapeamento baseada nos dicionários, a biblioteca permite ao programador Python começar a utilizar imediatamente o HDF5, sem precisar qualquer tipo de conhecimento mais aprofundado.
HDF5 é um modelo de dados que permite que seu conteúdo possa ser facilmente manipulado, e com grande eficiência.
HDF5 para deep learning em Python
O código que vou escrever aqui vai permitir você criar uma classe que servirá para dois propósitos:
- Gerar um dataset HDF5 para armazenar raw images, o que melhora muito a velocidade que leva para treinar as nossas CNN; e
- Gerar um dataset para armazenar as features extraídas de CNN já treinadas, facilitando você na hora de aplicar transfer learning.
Neste artigo, vou usar a classe HDF5Dataset para armazenar o conjunto de imagens da competição Dogs vs. Cats do Kaggle. O dataset completo possui 25.000 imagens de gatos e cachorros, e o objetivo da competição é treinar seu algoritmo para dizer se uma imagem escolhida aleatoriamente é classificada como cachorro (label=1) ou gato (label=0).
Após se registrar no Kaggle você é liberado para fazer o download do dataset, que tem a seguinte estrutura:
carlos$ tree -L 1 . ├── sampleSubmission.csv ├── test └── train carlos$ ls -1 train/ | wc -l 25000 carlos$ ls -U train/ | head -2 && ls -U train/ | tail -2 cat.0.jpg cat.1.jpg dog.9998.jpg dog.9999.jpg
No conjunto de treino, realmente são encontradas 25.000 imagens. O padrão dos nomes dos arquivos pode ser visto após o último comando Shell executado acima. So, hands-on! Hora de colocar a mão na massa e começar a escrever código!
Este código é baseado em um dos melhores materiais de DL que tive contato até hoje ( e que definitivamente inspira meus artigos aqui no site): o livro Deep Learning for Computer Vision, de Adrian Rosebrock. Se você, assim como eu, ainda esta engatinhando nessa área, recomendo a sua leitura 🙂
Escrevendo imagens em um dataset HDF5
Vamos começar a escrever a estrutura da class HDF5Dataset que poderá ser usada em qualquer projeto que necessite de eficiência e facilidade na manipulação dos nossos NumPy arrays contendo as raw images. Após, escreveremos um script que importará o dataset train com 25.000 imagens (e seus respectivos labels).
Vou importar todos os pacotes que serão usados no projeto, criar a classe HDF5Data e escrever o método especial __init__, que será chamado quando um objeto da nossa classe for instanciado:
# importar os pacotes necessários
import os
import argparse
from imutils import paths
import progressbar
from sklearn.preprocessing import LabelEncoder
import h5py
import cv2
class HDF5Dataset(object):
"""Escreve o conjunto de dados fornecidos como input (em formato numpy array)
para um conjunto de dados HDF5.
:param dims: dimensões dos dados a serem armazenados no dataset
:param output_path: arquivo onde o arquivo hd5f será salvo
:param data_key: nome do dataset que armazenará os dados
:param buffer_size: buffer de memória
"""
def __init__(self, dims, output_path, data_key='imagens', buffer_size=500):
# # verifica se o arquivo já existe, evitando seu overwrite.
if os.path.isfile(output_path):
raise ValueError("O arquivo '{}' já existe e não pode "
"ser apagado.".format(output_path))
# abrir um database HDF5 e criar 02 datasets:
# 1. Para armazenar as imagens; e
# 2. Para armazenar os labels.
self.db = h5py.File(output_path, 'w')
self.data = self.db.create_dataset(data_key, dims, dtype='float')
self.labels = self.db.create_dataset('labels', (dims[0],), dtype='int')
# Definir o buffer e índice da próxima linha disponível
self.buffer_size = buffer_size
self.buffer = {"data": [], "labels": []}
self.idx = 0
O construtor acima aceita quatro parâmetros, sendo dois opcionais. O parâmetro dims informa qual a dimensão dos dados a serem armazenados no dataset. Para armazenar 25.000 imagens RGB de 256 x 256, deve ser passado (25000, 256, 256, 3).
O parâmetro output_path informa onde salvar o arquivo contendo o dataset hdf5 no computador.
O terceiro parâmetro data_key representa o nome do dataset que vai armazenar as imagens raw. Opcional, passa a string imagens por default.
Por fim, o último parâmetro buffer_size é o valor do buffer. Cada vez que esse buffer é atingido, as imagens saem da memória do computador e são escritas no disco. Por padrão, cada vez que atinge-se 500 imagens armazenadas, é chamado o método flush() para esvaziar o buffer.
Ao instanciar um objeto, o construtor verifica se o arquivo já existe para impedir que este seja apagado ou danificado. Estando tudo certo, é criado um arquivo com o nome passado em output_path, e após são criados dois dataset dentro do mesmo arquivo:
- Um que armazenará as imagens raw (Linha 31); e
- Um que armazenará os labels de cada imagem (Linha 32).
Na sequência, são criados o buffer, em formato dicionário e um controle self.idx para o algoritmo saber qual a próxima linha que deve ser escrita. Assim não corremos o risco de perder o controle e escrever em alguma linha que já continha dados.
Método para armazenar os labels das classes
No dataset que está armazenando os labels respectivos a cada imagem, é possível encontrar apenas o valor 1 caso a imagem seja de um cachorro e 0 para gatos.
É interessante armazenar em um outro dataset a “decodificação” do que representam esses números, ou seja, o nome das classes dos labels (0 = "cat"; 1 = "dog"):
def store_class_labels(self, class_labels):
"""
Cria um dataset para armazenar as classes dos labels.
:param class_labels: lista com todos nomes das classes dos labels
"""
dt = h5py.special_dtype(vlen=str)
label_set = self.db.create_dataset("label_names",
shape=(len(class_labels),),
dtype=dt)
label_set[:] = class_labels
Método para adicionar mais imagens e labels ao dataset
Esse é o método responsável para adicionar novas linhas nos datasets de imagens e labels, respectivamente. Aqui a gente pode ver o buffer em ação – e valorizar o seu trabalho 🙂
def add(self, rows, labels):
"""
Adiciona as linhas e labels ao buffer.
:param rows: linhas a serem adicionadas ao dataset
:param labels: labels correspondentes às linhas adicionadas
"""
self.buffer["data"].extend(rows)
self.buffer["labels"].extend(labels)
# verificar se o buffer precisa ser limpo (escrever
# os dados informados no disco)
if len(self.buffer["data"]) >= self.buffer_size:
self.flush()
Todos os arrays passados nos parâmetros são armazenados em uma lista. A cada chamada do método, ele verifica se o tamanho do buffer está extrapolando o valor definido. Caso esteja acima do self.buffer_size, é chamado o método flush().
Método flush para esvaziar buffer e escrever no arquivo HDF5
Como explicado acima, para evitar estourar a memória do computador, quando é atingido um valor limite, o método aqui esvazia o buffer e transcreve as informações para o disco, no arquivo HDF5 que foi gerado:
def flush(self):
"""Reseta o buffer e escreve os dados no disco."""
i = self.idx + len(self.buffer["data"])
self.data[self.idx:i] = self.buffer["data"]
self.labels[self.idx:i] = self.buffer["labels"]
self.idx = i
self.buffer = {"data": [], "labels": []}
Finalizando o arquivo HDF5
Por fim, mas não menos importante, um método para fechar nosso arquivo HDF5, mas não sem antes verificar se alguma imagem ficou esquecida no buffer:
def close(self):
"""
Fecha o dataset após verificar se ainda há algum dado
remanescente no buffer.
"""
if len(self.buffer["data"]) > 0:
self.flush()
# fechar o dataset
self.db.close()
Construindo um dataset HDF5
Pronto! A nossa classe já está pronta e totalmente funcional, podendo ser usada nos mais diversos tipos de projetos. Para mostrar como usá-la para armazenar imagens, vou usar o dataset Dogs vs. Cats mencionado logo no começo do artigo.
Não vou me aprofundar nos detalhes do código que virá a seguir, pois não é este o objetivo principal do post. Porém, vamos destacar alguns pontos:
# argumentos de entrada do script
ap = argparse.ArgumentParser()
ap.add_argument('-d', '--dataset', required=True,
help='caminho do dataset')
ap.add_argument('-o', '--output', required=True, default="./tempo.hdf5",
help='caminho para salvar o arquivo HDF5')
ap.add_argument('-s', '--buffer-size', type=int, default=500,
help='buffer para escrever no arquivo HDF5')
args = vars(ap.parse_args())
# armazenar o buffer size
bs = args["buffer_size"]
# importar os nomes dos arquivos das imagens
print("[INFO] carregando imagens...")
imagePaths = list(paths.list_images(args["dataset"]))
# extrair e codificar os labels das classes de cada imagem do dataset
labels = [p.split(os.path.sep)[-1].split(".")[0] for p in imagePaths]
le = LabelEncoder()
labels = le.fit_transform(labels)
Nas Linhas 87-94 são estabelecidos os argumentos que o usuário deve informar na linha de comando ao executar o script.
Na Linha 100, usando paths.list_images() a gente consegue extrair para uma lista o caminho de todas fotos. Na sequência, são extraídos os labels para cada uma das imagens (lembre-se que os nomes dos arquivos seguem um padrão, então é só usar str.split à vontade!) para em seguida serem codificados com o auxílio da classe LabelEncoder do pacote sklearn.
Neste momento, chega finalmente a hora de criar o nosso dataset HDF5. Dependendo do tamanho e quantidade de dados a serem processados e importados, este processo pode demorar muito (principalmente se você não está usando uma GPU):
# iniciar o HDF5 e armazenar os nomes dos labels
dataset = HDF5Dataset((len(imagePaths), 256, 256, 3), args["output"], buffer_size=bs)
dataset.store_class_labels(le.classes_)
# Barra de progresso para acopanhar
widgets = ["[imagens] -> [hdf5]: ", progressbar.Percentage(), " ",
progressbar.Bar(), " ", progressbar.ETA()]
pbar = progressbar.ProgressBar(maxval=len(imagePaths),
widgets=widgets).start()
Detalhe importante!! Eu não estou fazendo nenhum pré-processamento importante nas imagens! Aqui, eu apenas redimensionei cada imagem para o shape (256, 256, 3), pois o objetivo era mostrar como importar imagens para arquivos HDF5.
Caso estivéssemos buscando desempenho e precisão para nossas CNN, seriam necessárias várias preocupações, como normalização, tipo de redimensionamento usado (aspect ratio?), necessidade de gerar mais dados de treino (data augmentation), entre outras.
Bom, para acompanhar o (lento) processo, entre as Linhas 113-116 foi gerada um barra de progresso, que irá informando a porcentagem de imagens já importadas e o tempo remanescente do processo.
Por fim, vamos criar um loop para importar cada imagem + label do conjunto de dados do Kaggle:
# processar e importar as imagens e labels
for (i, (path, label)) in enumerate(zip(imagePaths, labels)):
image = cv2.imread(path)
image = cv2.resize(image, (256, 256), interpolation=cv2.INTER_AREA)
dataset.add([image], [label])
pbar.update(i)
# finalizar e fechar o arquivo HDF5
pbar.finish()
dataset.close()
De maneira simples, usei a biblioteca OpenCV para ler e redimensionar cada imagem. A cada iteração é chamado o método HDF5Data.add, que joga as imagens no buffer até o limite de self.buffer_size ser atingido.
Atingido o limite do buffer, é chamado o método HDF5Data.flush para escrever as imagens no arquivo do disco e esvaziar o buffer.
Por fim, o arquivo é fechado e temos à disposição um arquivo com facilidade de acesso/fatiamento e super eficiente.
Executando o script
Com todo o código implementado no mesmo arquivo, vamos executar o script digitando o seguinte comando no Shell:
carlos$ python data_hdf5.py --dataset dataset/train/ --output ./train_dataset.hdf5 [INFO] carregando imagens… [imagens] -> [hdf5]: 100% |#####################################| Time: 0:02:19
Simples assim, todas as imagens estão eficientemente armazenadas em uma estrutura muito usada em DL, o formato HDF5.
Para abrir o arquivo e acessar suas fotos, é só importar o pacote h5py e abrir o arquivo em formato de leitura usando
db = h5py.File(“./nome_do_arquivo.hdf5”, “r”)
Para acessar a primeira foto do dataset, é só usar
db[“imagens”][0]
Para ver o shape do dataset com as images, é só usar
db[“imagens”].shape
E é isso mesmo, exatamente como manipular um array do NumPy.
Tudo maravilhoso? Bem, se você rodou o código, no entanto, com certeza percebeu um “problema”: o tamanho do arquivo gerado!
Antes você tinha um conjunto de imagens que não era cerca de 600 MB, e agora tem um arquivo que chega a “alguns” GB! O que aconteceu?
Resumindo em uma frase: “There is no free lunch!”
O ganho de desempenho e facilidade de manipulação significam que as imagens tiveram que ser importadas do jeito que elas realmente são, sem nenhum algoritmo de compressão agindo por trás. As imagens foram importadas como raw images, em formato NumPy arrays.
Para trabalharmos em projetos pequenos e poucas imagens, eficiência não é um problema sério. Entretanto, ao avançar mais nesse mundo, é inevitável ter que pensar nos pequenos detalhes do pipeline e da infraestrutura que estamos usando.
Resumo
Neste artigo você teve um contato com o formato HDF5, muito utilizado em projetos acadêmicos e em machine learning.
Apesar de várias bibliotecas terem seu próprio jeito de lidar com grandes banco de dados e imagens, se você quer eficiência e velocidade, provavelmente vai acabar tendo um contato maior com esse (ou outros) formato de dataset.
Entretanto, essa eficiência não vem de graça: você vai gerar arquivos com vários gigabytes a mais em relação ao dataset original – onde as imagens estavam compactadas por algum tipo de algoritmo. Ao importar imagens como NumPy arrays, você estará trabalhando com raw images.
Não entrei em detalhes, mas a mesma classe serve para armazenar as features extraídas após o treinamento de uma CNN qualquer. Para isso ser feito, você teria apenas que transformar o output da CNN em vetor (flatten) e prestar atenção nas dimensões a serem informadas na execução do script.
Bem, não tem como aprofundar muito mais no conteúdo e explicações. A ideia é apenas compartilhar coisas que estou aprendendo e que acho que estão sendo úteis para o meu aprendizado.
Se você ficou com alguma dúvida ou plotou algum erro conceitual/código, compartilhe aqui nos comentários! Também estou na batalha para aprender essa área fascinante da deep learning, mas ainda estou no começo da caminhada. Abraços!





![Data Science: Investigando o naufrágio do Titanic [Pt. 1]](https://sigmoidal.ai/wp-content/uploads/2019/07/Data-Science-Investigando-o-naufragio-do-Titanic-2-75x75.webp)














Muito legal! Obrigado pelo conhecimento!