
E se você pudesse pegar uma rede neural que levou semanas para ser treinada com milhões de imagens e, em poucos minutos, adaptá-la para resolver o seu problema específico? Isso é transfer learning, e é provavelmente a técnica mais importante para quem trabalha com Deep Learning na prática.
Treinar uma rede neural do zero exige muitos dados e muito poder computacional. Mas a verdade é que a maioria dos problemas do mundo real não precisa disso. As features que uma rede aprende ao classificar aproximadamente 1,28 milhão de imagens do ImageNet (bordas, texturas, formas) são úteis para quase qualquer tarefa visual.
A ideia por trás do transfer learning é simples: reaproveitar esse conhecimento já adquirido e adaptá-lo para uma nova tarefa.
Neste artigo, vamos aplicar transfer learning com PyTorch para classificar 102 espécies de flores usando uma ResNet18 pré-treinada no ImageNet.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O Que É Transfer Learning?
Imagine que você é um chef francês com 20 anos de experiência. Se alguém te pedir para cozinhar comida japonesa, você não precisa aprender o que é sal, fogo ou faca. Você já sabe cortar, temperar, controlar temperatura. Precisa apenas aprender as técnicas e ingredientes específicos da culinária japonesa. Todo o conhecimento base que você acumulou é transferível.
Com redes neurais convolucionais, funciona da mesma forma. Uma ResNet18 treinada no ImageNet aprendeu a detectar bordas nas primeiras camadas, texturas nas intermediárias e padrões complexos nas últimas. Essas representações são genéricas o suficiente para serem úteis em tarefas completamente diferentes, como classificar flores, detectar defeitos industriais ou identificar tumores em raios-X.
![]()
O transfer learning consiste em pegar uma rede pré-treinada em uma tarefa com muitos dados (como o ImageNet) e reutilizá-la em uma nova tarefa com menos dados. Na prática, existem duas estratégias principais:
- Feature Extraction: congelar todas as camadas da rede e treinar apenas um novo classificador no topo.
- Fine-Tuning: descongelar parte das camadas e treinar junto com o classificador, permitindo que a rede ajuste suas representações para a nova tarefa.
O Dataset: Oxford Flowers 102
O Oxford Flowers 102 é um dataset clássico de benchmarking em visão computacional. Ele contém imagens de 102 espécies de flores encontradas no Reino Unido, com 1.020 imagens para treino, 1.020 para validação e 6.149 para teste. Cada batch de treino contém 32 imagens (batch_size=32).

Repare na diversidade: flores de cores, formas e tamanhos muito distintos. Algumas espécies são visualmente parecidas, o que torna a classificação desafiadora. Com apenas 10 imagens de treino por classe em média, treinar uma rede do zero seria inviável. É exatamente o cenário onde transfer learning brilha.
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
test_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406],
[0.229, 0.224, 0.225])
])
train_dataset = torchvision.datasets.Flowers102(
root="./data", split="train", download=True, transform=train_transform
)
val_dataset = torchvision.datasets.Flowers102(
root="./data", split="val", download=True, transform=test_transform
)
test_dataset = torchvision.datasets.Flowers102(
root="./data", split="test", download=True, transform=test_transform
)
print("Treino:", len(train_dataset), "imagens")
print("Validacao:", len(val_dataset), "imagens")
print("Teste:", len(test_dataset), "imagens")
# Treino: 1020 | Validação: 1020 | Teste: 6149
São 1.020 imagens de treino para 102 classes. São poucos dados para uma rede neural aprender do zero, mas suficientes para adaptar uma rede que já sabe “ver”.
A ResNet18 e o Problema de Domínio
Antes de aplicar transfer learning, vale entender o que a ResNet18 pré-treinada já sabe. Ela foi treinada no ImageNet, um dataset com 1.000 classes que incluem animais, veículos, objetos do dia a dia. Existem algumas classes genéricas de flores (como daisy), mas nenhuma das 102 espécies específicas do Oxford Flowers.
O que acontece quando mostramos uma flor para essa rede?
# Pegar uma imagem de flor diretamente do dataset (índice fixo para reprodutibilidade)
img, label = train_dataset[0]
model_original = model_original.to(device)
img_gpu = img.unsqueeze(0).to(device)
with torch.no_grad():
output = model_original(img_gpu)
probs = torch.softmax(output, dim=1)
top5_probs, top5_idx = probs.topk(5)
print("Predições da ResNet18 (ImageNet) para uma flor:")
for i in range(5):
idx = top5_idx[0][i].item()
prob = top5_probs[0][i].item()
print(f" {imagenet_labels[idx]:>30s}: {prob:.1%}")

A rede reconhece que é uma flor: daisy aparece com 69.2% de confiança, seguida de pot (6.4%), bee (5.1%), vase (5.0%) e small white (2.3%). Ela acerta a categoria genérica, mas não consegue distinguir entre as 102 espécies do Oxford Flowers porque nunca foi treinada com essa granularidade. As features internas da rede são boas (ela entende formas, cores, texturas), mas a camada de classificação final mapeia para as 1.000 classes do ImageNet, não para as nossas 102.
É exatamente isso que vamos corrigir com transfer learning: manter as features e substituir o classificador.
Feature Extraction: Congelando a Rede
A primeira abordagem é a mais simples. Pegamos a ResNet18, congelamos todos os pesos (nenhuma camada de convolução é atualizada durante o treino) e substituímos apenas a última camada fully connected por uma nova, com 102 saídas (uma para cada espécie de flor).
model_fe = resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
# Congelar todos os parâmetros do backbone
for param in model_fe.parameters():
param.requires_grad = False
# Trocar a camada fc para 102 classes
# (módulos novos já nascem com requires_grad=True por padrão)
num_features = model_fe.fc.in_features
model_fe.fc = nn.Linear(num_features, 102)
total = sum(p.numel() for p in model_fe.parameters())
treinavel = sum(p.numel() for p in model_fe.parameters() if p.requires_grad)
print(f"Total: {total:,} | Treináveis: {treinavel:,} ({100*treinavel/total:.1f}%)")
# Total: 11,228,838 | Treináveis: 52,326 (0.5%)
De 11,2 milhões de parâmetros, estamos treinando apenas 52.326 (os pesos da nova camada fc: 512 x 102 + 102 de bias). A rede convolucional funciona como um extrator de features fixo, e o classificador no topo aprende a mapear essas features para as 102 espécies.
Após 15 épocas de treinamento, os resultados:
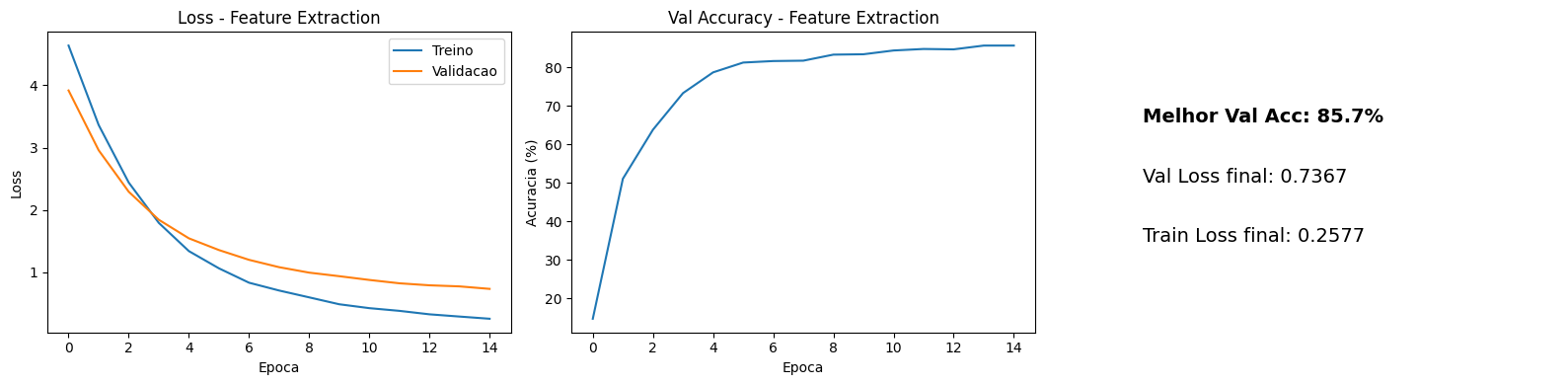
A acurácia de validação atingiu 85.7% com uma val loss final de 0.7367. É um resultado impressionante para 102 classes com tão poucos dados de treino e apenas a camada final sendo treinada. No conjunto de teste (6.149 imagens), o modelo atingiu 83.7% de acurácia. A rede convolucional, mesmo congelada, já extraía features discriminativas o suficiente para separar a maioria das espécies.
Mas 85.7% não é o limite. As features genéricas do ImageNet são boas, mas não perfeitas para flores. Será que deixar a rede ajustar suas representações melhora o resultado?
Fine-Tuning: Liberando Parte da Rede
No fine-tuning, descongelamos parte das camadas convolucionais e permitimos que elas se adaptem ao novo domínio. A intuição é que as primeiras camadas da rede (que detectam bordas e texturas básicas) são universais, mas as camadas mais profundas (que detectam padrões complexos) podem se beneficiar de um ajuste para o domínio de flores.
A estratégia mais comum é descongelar as últimas camadas da rede. Na ResNet18, descongelamos o layer4 (o último bloco residual) e a nova camada fc.
model_ft = resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)
# Congelar tudo primeiro
for param in model_ft.parameters():
param.requires_grad = False
# Descongelar layer4
for param in model_ft.layer4.parameters():
param.requires_grad = True
# Trocar a fc (módulos novos já nascem com requires_grad=True)
model_ft.fc = nn.Linear(model_ft.fc.in_features, 102)
total_params = sum(p.numel() for p in model_ft.parameters())
trainable_params = sum(p.numel() for p in model_ft.parameters() if p.requires_grad)
print(f"Treináveis: {trainable_params:,} / {total_params:,} ({100*trainable_params/total_params:.1f}%)")
# Treináveis: 8,446,054 / 11,228,838 (75.2%)
Agora estamos treinando 8,4 milhões de parâmetros (75.2% do total). Um detalhe importante é usar learning rates diferentes para cada parte da rede. A camada fc é nova e precisa aprender do zero, então usa um learning rate maior. O layer4 já tem pesos bons e precisa apenas de ajustes finos, então usa um learning rate menor.
# Learning rates diferenciados
optimizer_ft = optim.Adam([
{"params": model_ft.layer4.parameters(), "lr": 1e-4}, # ajuste fino
{"params": model_ft.fc.parameters(), "lr": 1e-3}, # camada nova
])
Essa técnica é chamada de differential learning rate (ou discriminative learning rates). A ideia é que camadas mais profundas, que já possuem representações razoáveis, devem ser atualizadas com passos menores para não destruir o conhecimento pré-treinado. Aqui, o layer4 treina com um learning rate 10 vezes menor que a camada fc.
Após 15 épocas de treinamento:
- Acurácia de validação: 92.5%
- Acurácia de teste: 90.2%
- Val loss final: 0.3378
A melhoria é significativa. A acurácia de validação subiu de 85.7% para 92.5%, e a val loss caiu de 0.7367 para 0.3378. No conjunto de teste (6.149 imagens nunca vistas), o modelo acertou 90.2% das classificações.
Feature Extraction vs Fine-Tuning
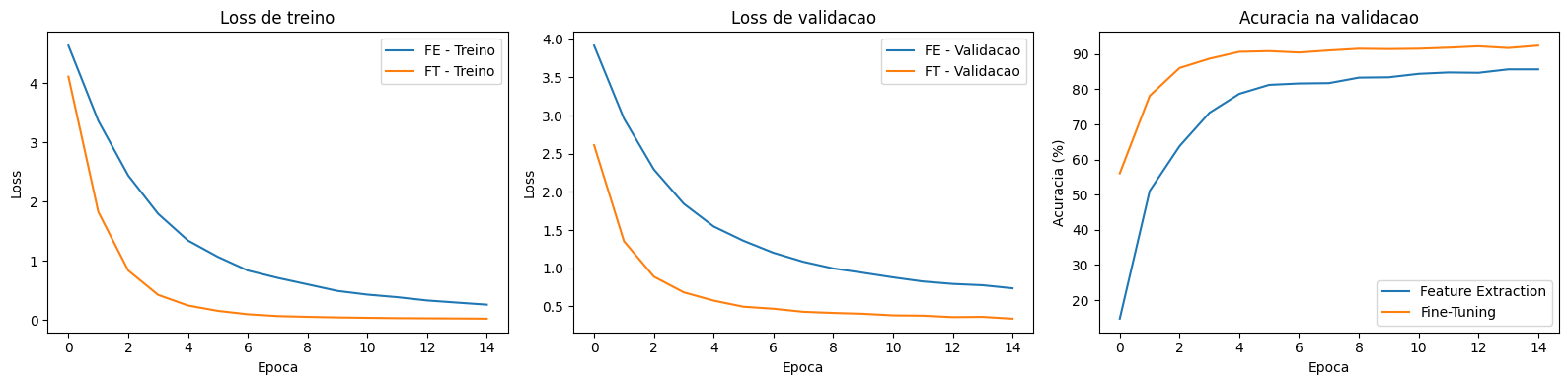
A comparação visual deixa claro o que os números já indicavam. O fine-tuning converge para uma loss muito menor e uma acurácia consistentemente mais alta. Vamos organizar os resultados:
| Métrica | Feature Extraction | Fine-Tuning |
|---|---|---|
| Parâmetros treináveis | 52.326 (0.5%) | 8.446.054 (75.2%) |
| Acurácia de validação | 85.7% | 92.5% |
| Acurácia de teste | 83.7% | 90.2% |
| Val loss final | 0.7367 | 0.3378 |
| Learning rate | 1e-3 (fc) | 1e-4 (layer4), 1e-3 (fc) |
O feature extraction é mais rápido de treinar (menos parâmetros, sem backpropagation pelas camadas convolucionais) e mais resistente a overfitting. É a melhor escolha quando você tem muito poucos dados ou precisa de um resultado rápido.
O fine-tuning entrega resultados superiores quando você tem dados suficientes para ajustar as camadas convolucionais sem overfitting. O differential learning rate é essencial aqui: sem ele, um learning rate alto pode destruir as representações pré-treinadas (o chamado catastrophic forgetting), e um learning rate baixo demais tornaria o treinamento da camada fc lento.
Quando Usar Cada Abordagem?
A escolha entre feature extraction e fine-tuning depende de dois fatores: a quantidade de dados e a similaridade entre o domínio original e o novo.
Se o novo dataset é pequeno e similar ao ImageNet (animais, objetos comuns), feature extraction costuma ser suficiente. Se é grande ou muito diferente (imagens médicas, satélite, microscopia), fine-tuning é quase sempre a melhor opção.
Na dúvida, comece com feature extraction como baseline. Se o resultado não for satisfatório, parta para o fine-tuning descongelando as últimas camadas. É uma abordagem progressiva que minimiza o risco de overfitting. Se quiser se aprofundar, veja nossa lista com os melhores cursos para aprender deep learning em Python.
Takeaways
- Transfer learning reaproveita conhecimento: em vez de treinar do zero, usamos uma rede pré-treinada no ImageNet como ponto de partida. As features genéricas (bordas, texturas, formas) são transferíveis para quase qualquer tarefa visual.
- Feature extraction é simples e eficaz: congelando a rede e treinando apenas a camada final, atingimos 85.7% de acurácia na validação e 83.7% no teste em 102 classes de flores com apenas 52 mil parâmetros treináveis.
- Fine-tuning entrega resultados superiores: descongelando o
layer4da ResNet18 e usando differential learning rate (1e-4 para camadas pré-treinadas, 1e-3 para a camada nova), a acurácia subiu para 92.5% na validação e 90.2% no teste.
- Differential learning rate evita catastrophic forgetting: camadas pré-treinadas devem ser atualizadas com passos menores para preservar o conhecimento adquirido, enquanto camadas novas precisam de passos maiores para aprender rápido.
- Comece simples, evolua se necessário: feature extraction como baseline, fine-tuning quando precisar de mais acurácia. Essa abordagem progressiva é o caminho mais seguro na prática.



















