A utilização de Machine Learning para a detecção do câncer de mama vem crescendo cada vez mais e contribuindo para diagnósticos mais rápidos e precisos.
De acordo com a Sociedade Brasileira de Mastologia, uma em cada 12 mulheres terá um tumor nas mamas até os 90 anos. Infelizmente, o câncer de mama é a principal causa de morte entre as mulheres, de todos os diferentes tipos de câncer.

Uma das principais características do câncer de mama é que quanto mais precoce for o seu diagnóstico, maiores são as chances de tratamento. Entretanto, uma pesquisa realizada revelou que mais de 3,8 milhões de mulheres na faixa de 50 a 69 anos nunca haviam feito autoexame ou mamografia.
A fim de aumentar a conscientização a respeito da prevenção e diagnóstico precoce, há, todo ano, a campanha Outubro Rosa, que visa alertar principalmente as mulheres sobre esta causa.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Contribuindo com essa conscientização e com a campanha Outubro Rosa, preparei um projeto de Data Science onde construí um modelo de Machine Learning capaz de detectar o câncer de mama.
Se você está começando na carreira de Cientista de Dados, acompanhe os outros tutoriais aqui do blog 🙂
Importar os Dados
Para a construção do modelo de Machine Learning, foi usado o banco de dados Wisconsin, disponibilizado no Repositório de Machine Learning da UCI.
Os dados que serão utilizados nesta análise também estão disponíveis para download por meio deste link direto e consistem basicamente em um arquivo csv contendo 569 entradas e 32 colunas, onde as observações foram obtidas por meio da aspiração com agulha fina de células da mama. Ressalta-se ainda que a variável alvo pode ser classificada em benigna ou maligna.
Este arquivo será importado para uma estrutura DataFrame utilizando a biblioteca pandas a fim de possibilitar sua manipulação e análise.
# importar os pacotes necessários
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from xgboost import XGBClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.impute import SimpleImputer
# configurar o notebook
sns.set_style()
# importar o dataset em csv
data_path = "https://www.dropbox.com/s/z8nw6pfumdw3bb9/breast-cancer-wisconsin.csv?raw=1"
df = pd.read_csv(data_path)
# eliminar uma coluna com erro
df.drop('Unnamed: 32', axis=1, inplace=True)
Análise Exploratória
A primeira coisa que faremos após importar o dataset será examinar as dimensões do DataFrame e as primeiras entradas. Isso possibilitará criar uma consciência situacional inicial a respeito do formato de entrada e da estrutura geral dos dados.
- A coluna
idrepresenta o número de identificação. - A coluna
diagnosisé a variável alvo.- M – Maligno
- B – Benigno
- A descrição completa para cada uma das features está disponível neste link.
Uma característica é um número de identificação (ID), outro é o diagnóstico de câncer; e 30 são medidas laboratoriais numéricas. O diagnóstico é codificado como “M” para indicar maligno ou “B” para indicar benigno.
# dimensões do df
print("DIMENSÕES DO DATAFRAME:")
print("Linhas:\t\t{}".format(df.shape[0]))
print("Colunas:\t{}".format(df.shape[1]))
## DIMENSÕES DO DATAFRAME:
## Linhas: 569
## Colunas: 32
Já as primeiras 5 entradas desse conjunto de dados permitem adquirirmos uma noção inicial sobre o tipo de formato, exemplos de entrada e formulação das hipóteses iniciais do processo investigativo.
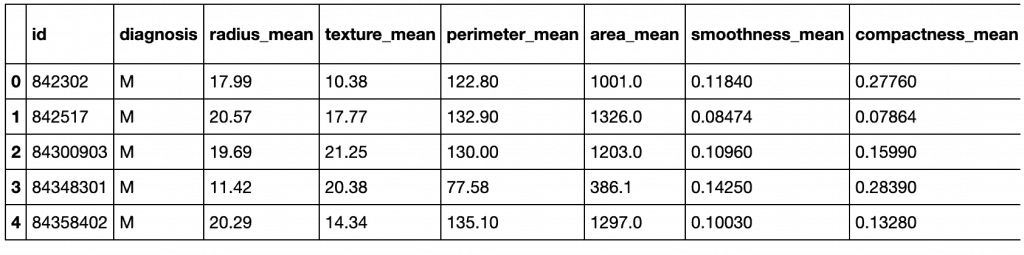
Por meio do método describe, é possível ver um resumo estatístico das variáveis numéricas.
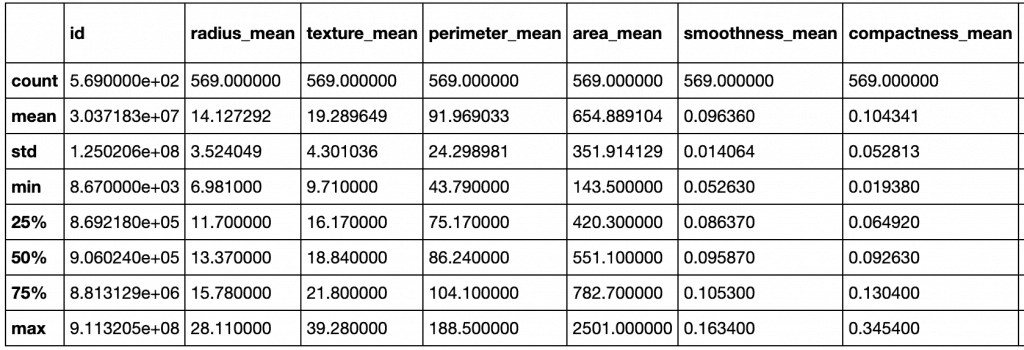
Com exceção da coluna diagnosis, todas as outras são do tipo numérica (int e float). Apesar dessa ser a nossa conclusão olhando as primeiras entradas, é prudente analisar por meio do atributo dtypes para ter certeza que nenhuma foi importada como string.
Como em qualquer projeto de Data Science, a verificação da presença de valores ausentes no dataset é de extrema importância, pois é o reflexo direto da qualidade do mesmo. Para ver essas informações integralmente, acesso o código completo neste Jupyter notebook.
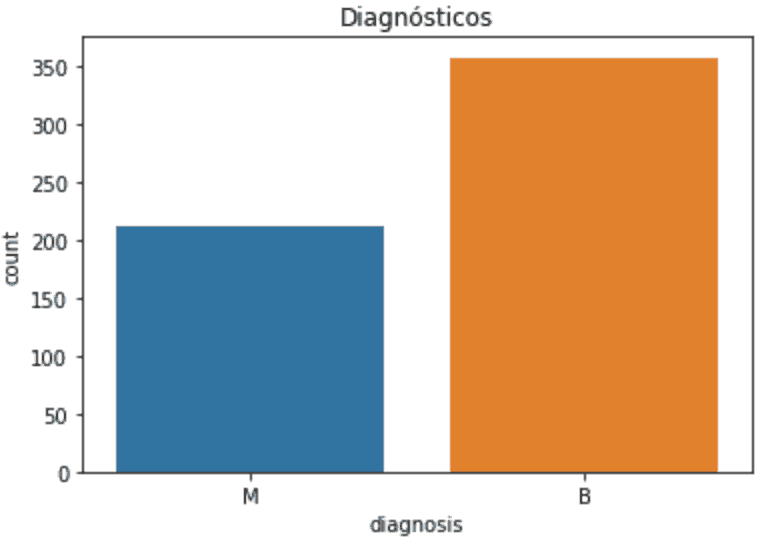
Agora, irei verificar o balanceamento do dataset vendo a porcentagem de valores da variável alvo. Como se pode ver abaixo, existe um pequeno desbalanceamento de valores.
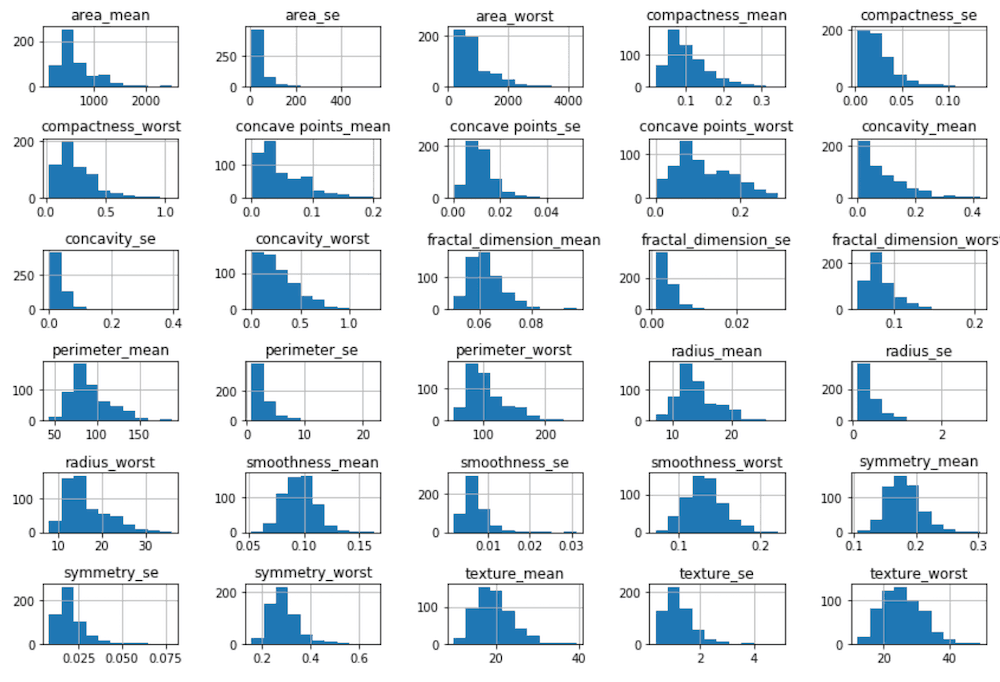
Para ter a noção de como as variáveis estão distribuídas, vou plotar o histograma de todas as variáveis numéricas, excluindo a coluna id, uma vez que ela não acrescenta nenhuma informação importante.
Preste sempre atenção em como os valores de algumas variáveis estão mais bem distribuídos em torno de uma média, e outras tendem a puxar o histograma para a esquerda.
Para ver a força da correlação entre as variáveis, uma opção é plotar um heatmap. Repare no mapa abaixo como diversas variáveis possuem correlação positiva.
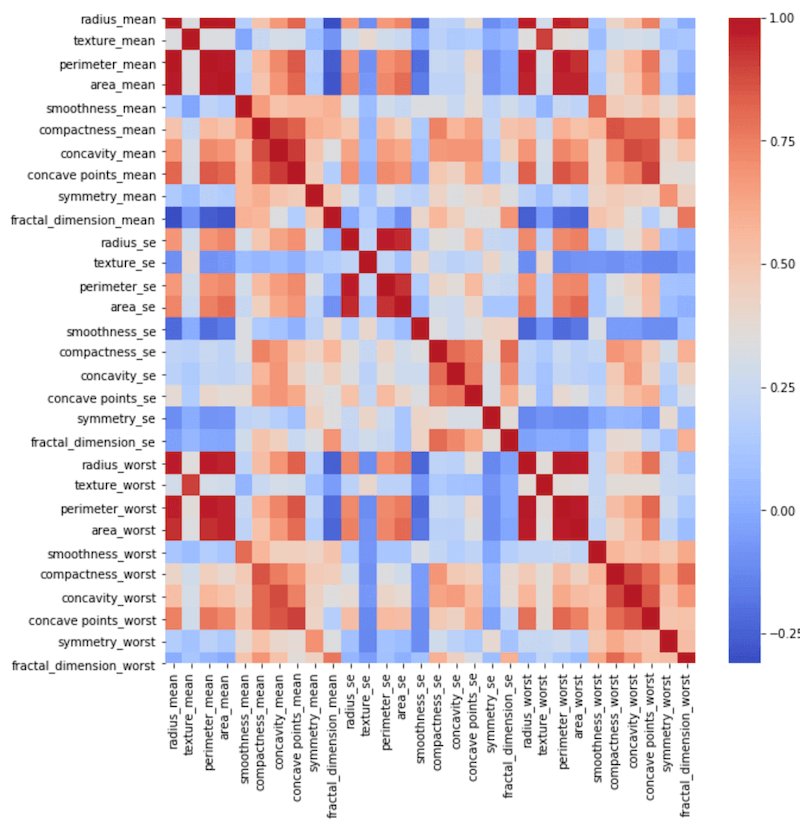
Preparação dos dados
Como parte do pré-processamento dos dados, que irão alimentar o modelo de Machine Learning, vou usar o StardardScaler, que vem junto com sklearn.preprocessing, para padronizar nossos dados numéricos.
Se você olhar no começo do código, vai reparar que a nossa variável alvo é categórica, onde M representa os tumores malignos e B os benignos. Usando LabelEncoder somos capazes de converter variáveis categóricas em numéricas e alimentar o modelo adequadamente.
from sklearn.preprocessing import StandardScaler from sklearn.preprocessing import LabelEncoder from sklearn.model_selection import train_test_split # separar as variáveis independentes da variável alvo X = df.drop(['diagnosis', 'id'], axis=1) y = df['diagnosis'] # padronizar as colunas numéricas X = StandardScaler().fit_transform(X) # label encoder na variável alvo y = LabelEncoder().fit_transform(y) # dividir o dataset entre treino e teste X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
Por fim, antes de construir o modelo de fato, dividimos o dataset entre treino e teste usando o train_test_split, função que facilita muito o trabalho e que se encontra em sklearn.model_selection.
Modelo de Machine Learning para detecção do câncer de mama
Este problema de detecção de câncer consiste em classificar corretamente um tumor entre benigno e maligno, ou seja, é necessário que o modelo de Machine Learning dê uma classificação ao ser alimentado com diversas variáveis independentes (features).
Aqui, usarei um modelo do tipo Random Forest (Floresta Aleatória) devido à sua flexibilidade e facilidade de uso (uma vez que funciona muito bem mesmo sem o ajuste nos hiperparâmetros).
from sklearn.ensemble import RandomForestClassifier # instanciando o modelo de Random Forest ml_model = RandomForestClassifier(n_estimators = 10, criterion='entropy', random_state = 42) # treinando o modelo ml_model.fit(X_train, y_train)
O algoritmo Random Forest, que usa métodos ensemble, tem esse nome por que cria uma combinação de várias árvores de decisão – uma “floresta” realmente – verificando qual combinação apresenta melhor desempenho e acurácia.
Vamos dar uma checada no desempenho do modelo quando se depara pela primeira vez com o conjunto de testes.
Desempenho do modelo de detecção de câncer de mama
Cada caso é um caso. Nem sempre uma excelente acurácia vai significar que seu modelo está bom.
Por exemplo, quando se trata de detectar câncer, queremos maximizar o número de verdadeiros positivos e minimizar o número de falsos negativos. No entanto, esta é uma balança difícil de equilibrar, e o trade-off pode ser bem subjetivo inclusive.
Aqui, além da métrica de acurácia vou usar a função classification_report para ver ver o desempenho do modelo sobre as métricas de precisão, recall, f1-score e support.
from sklearn.metrics import classification_report
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
# realizar as previsões no dataset de teste
y_pred = ml_model.predict(X_test)
# ver acurácia geral
print('[Acurácia] Random Forest:', accuracy_score(y_test, y_pred))
# imprimir o classification report
print('\n[Classification Report] Random Forest')
print( classification_report(y_test, y_pred))
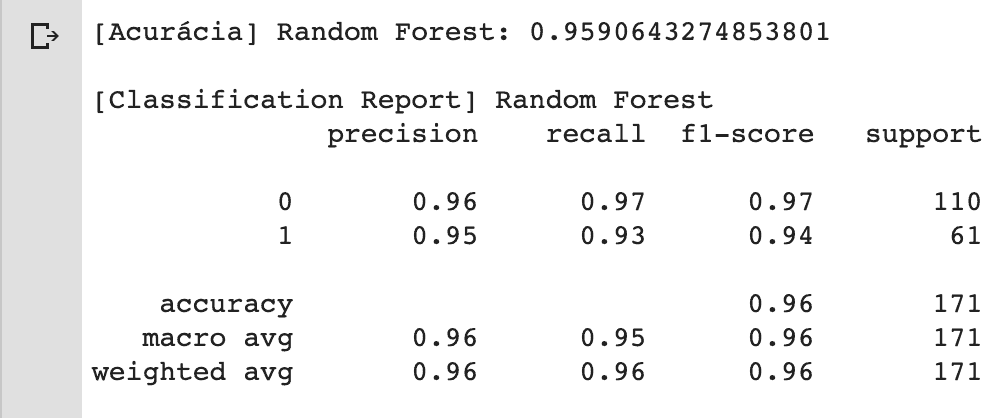
Aparentemente, o modelo está com ótimos valores nas métricas consideradas. Mas como eu disse lá em cima, cada caso é um caso.
Eu acho muito interessante você sempre dar uma checada na matriz de confusão. Para exemplificar, imagine que seu modelo é capaz de detectar com 99,999% de acurácia sempre que um paciente não apresenta um tumor maligno, mas apenas 85% de acurácia quando prevê que o mesmo paciente apresenta esse tumor maligno.
Há vezes em que é melhor ter mais falsos positivos e investigar mais profundamente o caso (como também é o caso de fraudes no cartão de crédito), e ter um modelo menos preciso.
# plotar a matriz de confusão
pd.DataFrame(confusion_matrix(y_test, y_pred),
index=['neg', 'pos'], columns=['pred_neg', 'pred_pos'])

Como você pode confirmar, o modelo classificatório Random Forest para a detecção de câncer de mama foi capaz de atingir uma acurácia superior a 96% e lidou muito bem com ambas as classes.
Outubro Rosa e Machine Learning
Apesar da campanha Outubro Rosa ser em Outubro, a conscientização deve existir durante o ano todo. A importância de um dianóstico precoce do câncer de mama deve estar clara na cabeça de todo mundo.

Avanços e descobertas no campo da Inteligência Artificial ocorrem a todo momento, principalmente na área da saúde. Detecção de câncer por meio de algoritmos de Machine Learning ajuda cada vez mais os médicos a diagnosticarem seus pacientes, aumentando drasticamente as chances dos tratamentos convencionais.
No entanto, mesmo a construção de modelos altamente confiáveis para a detecção de câncer de mama não substitui uma variável, a principal feature, o diagnóstico precoce 😉
Espero ter contribuido um pouco com a causa, apresentando um modelo 100% replicável por qualquer pessoa (basta abrir o código no Google Colab e executar cada linha.
Sinta-se à vontade para modificar, expandir e melhorar esse modelo. Abraços!




















Show o artigo!
Muito obrigado, Tiago! 🙂
Ola, neste caso a classe esta bem desbalanceada , teria que balancear antes de colocar o modelo para rodar correto?
Seria o ideal sim. Ou o modelo pode ficar enviesado para o label com mais ocorrências 🙂
Sobre a pergunta do Ariel de desbalanceamento de dados, como poderíamos “corrigir” esse problema?
Muito bom!!