Quase todo curso de Machine Learning apresenta o erro quadrático médio como “a métrica certa”, deriva o gradient descent e segue em frente. Quando você pergunta por que elevamos o erro ao quadrado, e não ao cubo ou em valor absoluto, a resposta costuma ser “porque funciona melhor”. Essa resposta está incompleta, e a versão completa revela que o MSE não foi escolhido: ele é consequência de uma hipótese estatística.
Este é o segundo artigo da série Matemática para Machine Learning. No primeiro, construímos o modelo de regressão linear  e aprendemos a fazer predições com pesos escolhidos à mão. Agora fechamos a parte que faltava: como encontrar os melhores pesos. Vamos definir uma função de custo, derivar e implementar o gradient descent do zero, e ao final voltar atrás para mostrar de onde o MSE realmente vem. A notação segue a convenção padrão da literatura de Machine Learning.
e aprendemos a fazer predições com pesos escolhidos à mão. Agora fechamos a parte que faltava: como encontrar os melhores pesos. Vamos definir uma função de custo, derivar e implementar o gradient descent do zero, e ao final voltar atrás para mostrar de onde o MSE realmente vem. A notação segue a convenção padrão da literatura de Machine Learning.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Da pergunta natural ao MSE
Para cada exemplo  , definimos o erro como a diferença entre a predição e o valor real,
, definimos o erro como a diferença entre a predição e o valor real,  . Com
. Com  exemplos, temos um vetor de erros. A pergunta que organiza tudo é direta: como resumir esse vetor em um único número que represente o quão errado o modelo está? Um número é o que se consegue otimizar; um vetor de mil erros só se consegue olhar.
exemplos, temos um vetor de erros. A pergunta que organiza tudo é direta: como resumir esse vetor em um único número que represente o quão errado o modelo está? Um número é o que se consegue otimizar; um vetor de mil erros só se consegue olhar.
A primeira tentativa, somar os erros, falha por uma razão clara. Um erro de  em um exemplo e um erro de
em um exemplo e um erro de  em outro se cancelam, e o modelo “parece perfeito” estando errado nos dois casos. Precisamos de uma medida de magnitude, não de direção. Somar os valores absolutos resolve o cancelamento e é uma função de custo legítima, o Mean Absolute Error, mas tem um inconveniente: a função
em outro se cancelam, e o modelo “parece perfeito” estando errado nos dois casos. Precisamos de uma medida de magnitude, não de direção. Somar os valores absolutos resolve o cancelamento e é uma função de custo legítima, o Mean Absolute Error, mas tem um inconveniente: a função  não é diferenciável em zero, e a otimização que veremos depende de derivadas.
não é diferenciável em zero, e a otimização que veremos depende de derivadas.
Somar os quadrados resolve as duas coisas ao mesmo tempo. O quadrado é sempre positivo, então não há cancelamento, e é uma função suave, infinitamente diferenciável. Como característica adicional, ele penaliza erros grandes de forma desproporcional: um erro de  contribui com
contribui com  , e um erro de
, e um erro de  contribui com
contribui com  . Por enquanto, aceite o erro quadrático como uma escolha razoável de engenharia. Ao final do artigo veremos que ela não foi uma escolha, foi uma consequência.
. Por enquanto, aceite o erro quadrático como uma escolha razoável de engenharia. Ao final do artigo veremos que ela não foi uma escolha, foi uma consequência.
Loss e cost: uma distinção que importa
Vale separar dois termos que costumam ser usados como sinônimos. A loss é o erro em um único exemplo:
![\[L\left(f_{w,b}(x^{(i)}), y^{(i)}\right) = \frac{1}{2}\left(f_{w,b}(x^{(i)}) - y^{(i)}\right)^2.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-6880cad9f242c43e1eff8742e58bc112_l3.png "Rendered by QuickLaTeX.com")
A cost é o erro médio ao longo de todo o conjunto de dados, considerando os exemplos:
![\[J(w,b) = \frac{1}{2m} \sum_{i=1}^{m} \left(f_{w,b}(x^{(i)}) - y^{(i)}\right)^2.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-b1af52a1d4fda35bb9e46d291d9d21a0_l3.png "Rendered by QuickLaTeX.com")
A loss olha para um exemplo; a cost olha para o conjunto inteiro. Quando treinamos o modelo, estamos minimizando a cost. O fator  , aparentemente arbitrário, tem uma única finalidade: quando derivarmos a função, o quadrado produz um fator
, aparentemente arbitrário, tem uma única finalidade: quando derivarmos a função, o quadrado produz um fator  que cancela com ele, deixando a fórmula final mais limpa. A implementação dessas duas funções é uma tradução direta da definição:
que cancela com ele, deixando a fórmula final mais limpa. A implementação dessas duas funções é uma tradução direta da definição:
def modelo(x, w, b):
return w * x + b
def custo(x, y, w, b):
"""Cost function (MSE com fator 1/2) da regressão linear."""
erro = modelo(x, w, b) - y
return np.mean(erro ** 2) / 2
print("J(w=0, b=0) =", round(custo(x, y, 0.0, 0.0), 3))
print("J(w=2, b=1) =", round(custo(x, y, 2.0, 1.0), 3))
J(w=0, b=0) = 73.636 J(w=2, b=1) = 1.018
Os dados foram gerados em torno de  . Por isso o custo cai de
. Por isso o custo cai de  , com parâmetros nulos, para cerca de
, com parâmetros nulos, para cerca de  quando usamos os parâmetros que de fato geraram os dados. Treinar é, precisamente, encontrar o par
quando usamos os parâmetros que de fato geraram os dados. Treinar é, precisamente, encontrar o par  que torna esse número o menor possível.
que torna esse número o menor possível.
A superfície de custo: a tigela
Com os dados fixos,  é uma função apenas dos parâmetros. Cada combinação de
é uma função apenas dos parâmetros. Cada combinação de  e
e  produz um valor de custo, e podemos visualizar todos eles de uma vez. Como a cost é uma soma de quadrados de funções lineares nos parâmetros, a superfície resultante é convexa, com um único mínimo global. É a famosa tigela: vista em três dimensões, uma superfície que afunda em um ponto; vista de cima, curvas de nível elípticas e concêntricas em torno do ótimo.
produz um valor de custo, e podemos visualizar todos eles de uma vez. Como a cost é uma soma de quadrados de funções lineares nos parâmetros, a superfície resultante é convexa, com um único mínimo global. É a famosa tigela: vista em três dimensões, uma superfície que afunda em um ponto; vista de cima, curvas de nível elípticas e concêntricas em torno do ótimo.
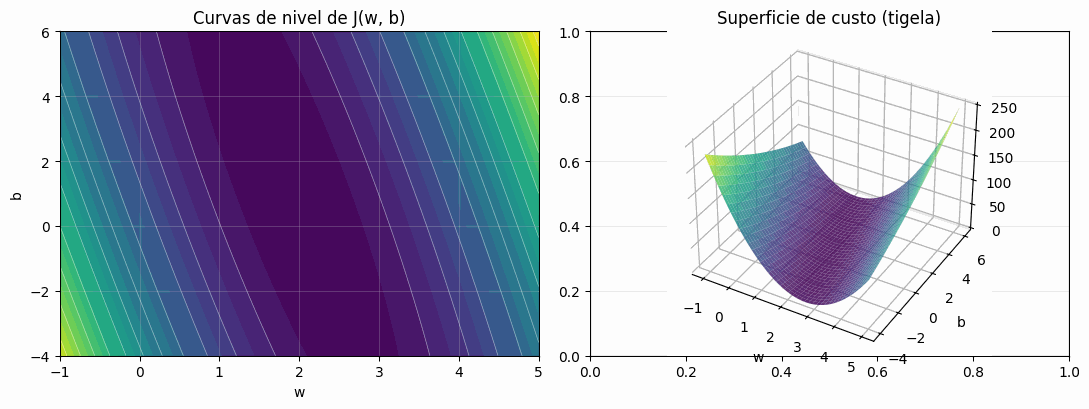
Essa geometria é o que motiva o algoritmo de treinamento. Olhando o gráfico, é fácil enxergar o mínimo. Mas e quando o modelo tem um milhão de parâmetros, como uma rede neural? Não há como plotar uma superfície em um espaço de um milhão de dimensões e simplesmente “ver” o fundo. Precisamos de um método que encontre o mínimo usando apenas informação local, sem nunca enxergar o mapa inteiro. Esse método é o gradient descent.
Gradient descent: descendo a tigela com derivadas
A ideia é a seguinte. Estando em um ponto qualquer da superfície, calculamos a inclinação local, o gradiente, e damos um passo na direção oposta, a de descida mais rápida. Repetimos até chegar ao fundo. A regra de atualização para os dois parâmetros é
![\[w := w - \alpha \frac{\partial J}{\partial w}, \qquad b := b - \alpha \frac{\partial J}{\partial b},\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-3b72eff8997e588301dfbc368cd5f858_l3.png "Rendered by QuickLaTeX.com")
onde  é o learning rate, a taxa que controla o tamanho do passo. Três pontos merecem atenção. O símbolo
é o learning rate, a taxa que controla o tamanho do passo. Três pontos merecem atenção. O símbolo  é atribuição, não igualdade matemática: significa “calcule o lado direito e guarde no parâmetro”. O learning rate precisa de calibragem, porque um passo grande demais pode ultrapassar o mínimo e divergir, e um passo pequeno demais torna a convergência lenta. E a atualização precisa ser simultânea: ambas as derivadas são calculadas com os valores antigos de e , e só então os dois são atualizados.
é atribuição, não igualdade matemática: significa “calcule o lado direito e guarde no parâmetro”. O learning rate precisa de calibragem, porque um passo grande demais pode ultrapassar o mínimo e divergir, e um passo pequeno demais torna a convergência lenta. E a atualização precisa ser simultânea: ambas as derivadas são calculadas com os valores antigos de e , e só então os dois são atualizados.
Calculando as derivadas a partir da definição da cost, e aqui o fator cumpre seu papel ao cancelar o da regra da cadeia, chegamos a expressões notavelmente simples:
![\[\frac{\partial J}{\partial w} = \frac{1}{m} \sum_{i=1}^{m} \left(f_{w,b}(x^{(i)}) - y^{(i)}\right) x^{(i)}, \qquad \frac{\partial J}{\partial b} = \frac{1}{m} \sum_{i=1}^{m} \left(f_{w,b}(x^{(i)}) - y^{(i)}\right).\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-efc0ddf7ed63c04219834a5f7c597403_l3.png "Rendered by QuickLaTeX.com")
A atualização de é proporcional ao erro multiplicado pela feature  . Faz sentido: um exemplo com
. Faz sentido: um exemplo com  grande, ainda por cima previsto de forma errada, puxa o peso com força para corrigir o modelo naquela região. Essa forma “erro vezes entrada” reaparecerá em toda a série, da classificação às redes neurais. A implementação acompanha as fórmulas linha a linha:
grande, ainda por cima previsto de forma errada, puxa o peso com força para corrigir o modelo naquela região. Essa forma “erro vezes entrada” reaparecerá em toda a série, da classificação às redes neurais. A implementação acompanha as fórmulas linha a linha:
def gradiente(x, y, w, b):
"""Derivadas parciais do custo em relação a w e b."""
erro = modelo(x, w, b) - y
dw = np.mean(erro * x)
db = np.mean(erro)
return dw, db
def gradient_descent(x, y, w, b, alpha, n_iter):
"""Treina a regressão linear, retornando parâmetros e histórico do custo."""
historico = []
for _ in range(n_iter):
dw, db = gradiente(x, y, w, b)
w = w - alpha * dw # atualização simultânea
b = b - alpha * db
historico.append(custo(x, y, w, b))
return w, b, historico
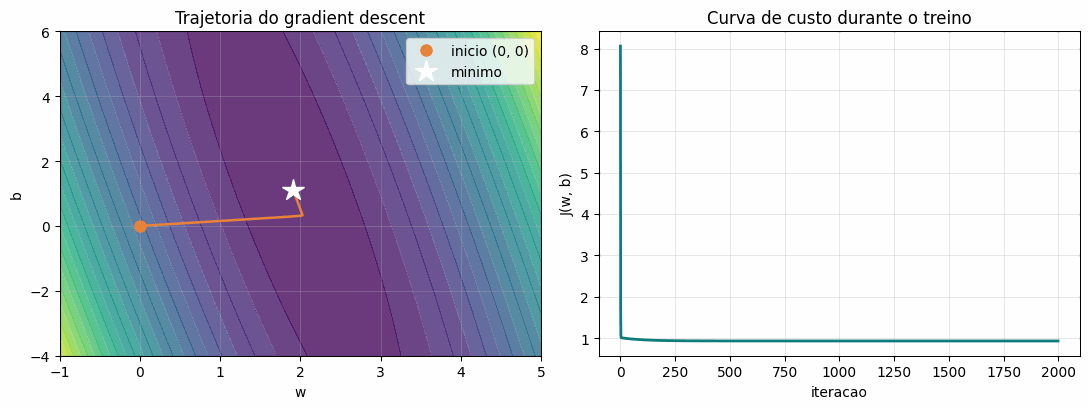
Partindo de  e
e  , com
, com  e duas mil iterações:
e duas mil iterações:
w treinado = 1.913 (gerador usou 2.0) b treinado = 1.097 (gerador usou 1.0) custo final = 0.9283
O algoritmo, usando apenas derivadas locais e sem jamais “ver” a superfície inteira, recuperou parâmetros muito próximos dos que de fato geraram os dados. A figura a seguir torna o processo concreto. À esquerda, o caminho percorrido por sobre as curvas de nível: partindo da origem, cada passo desce na direção oposta ao gradiente até alcançar o mínimo. Note que converge antes de , um reflexo de o custo ser muito mais sensível a do que a neste problema. À direita, o mesmo processo visto como a queda do custo ao longo das iterações.
O resultado desse processo é a reta de melhor ajuste, com a inclinação e o intercepto que o gradient descent encontrou sozinho.
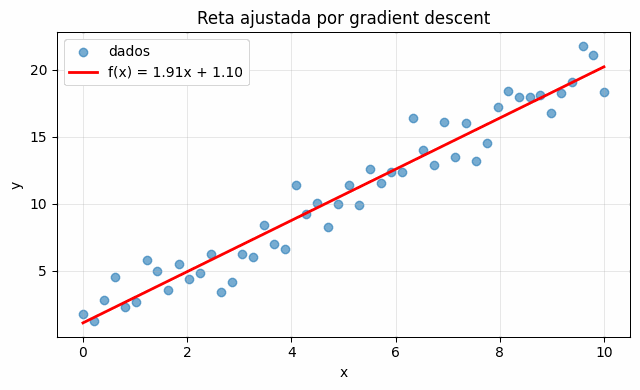
Até aqui, você sabe exatamente o que a maioria dos cursos ensina no primeiro mês: definir uma loss, calcular a cost, derivar e implementar o gradient descent, treinar uma regressão linear. Para a maior parte dos problemas práticos, isso é suficiente. Mas continua de pé a pergunta da abertura: por que o MSE?
A origem escondida do MSE: Maximum Likelihood
A mudança de perspectiva é a parte mais importante deste artigo. Até agora pensamos no modelo como uma máquina que recebe um e devolve um número  . Vamos passar a vê-lo como uma máquina que prevê uma distribuição de probabilidade.
. Vamos passar a vê-lo como uma máquina que prevê uma distribuição de probabilidade.
A motivação vem dos dados reais. Não existe reta perfeita que passe por todos os pontos de um conjunto de dados real. Imóveis idênticos são vendidos por preços diferentes; sempre há fatores não capturados pelas features e ruído de medição. O modelo honesto dos dados é, então,
![\[y^{(i)} = f_{w,b}(x^{(i)}) + \varepsilon^{(i)}, \qquad \varepsilon^{(i)} \sim \mathcal{N}(0, \sigma^2),\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-9044f0f3dd57c909359533226465de4d_l3.png "Rendered by QuickLaTeX.com")
em que  é um ruído aleatório. A hipótese mais natural, justificada pelo Teorema Central do Limite quando o ruído resulta da soma de muitos fatores independentes, é que ele seja gaussiano, com média zero e variância
é um ruído aleatório. A hipótese mais natural, justificada pelo Teorema Central do Limite quando o ruído resulta da soma de muitos fatores independentes, é que ele seja gaussiano, com média zero e variância  . Nesse quadro, a reta deixa de ser “a previsão” e passa a ser o centro de uma faixa de valores possíveis. Esse é o tipo de distribuição que estudamos em distribuições estatísticas com Python, agora aplicada ao ruído de um modelo.
. Nesse quadro, a reta deixa de ser “a previsão” e passa a ser o centro de uma faixa de valores possíveis. Esse é o tipo de distribuição que estudamos em distribuições estatísticas com Python, agora aplicada ao ruído de um modelo.
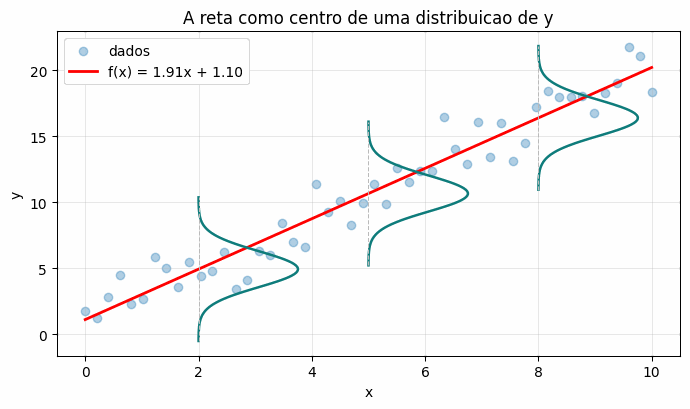
Para cada valor de , o modelo não aponta um único  , e sim uma curva gaussiana de valores possíveis centrada na reta. Treinar o modelo é escolher a reta que torna os dados observados os mais prováveis sob essas distribuições.
, e sim uma curva gaussiana de valores possíveis centrada na reta. Treinar o modelo é escolher a reta que torna os dados observados os mais prováveis sob essas distribuições.
A densidade de observar um  específico é então uma gaussiana centrada na predição:
específico é então uma gaussiana centrada na predição:
![\[p\left(y^{(i)} \mid x^{(i)}; w, b\right) = \frac{1}{\sqrt{2\pi\sigma^2}} \exp\left(-\frac{\left(y^{(i)} - f_{w,b}(x^{(i)})\right)^2}{2\sigma^2}\right).\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-bd8567d80c01db736056f1e5c25b788c_l3.png "Rendered by QuickLaTeX.com")
A pergunta de máxima verossimilhança inverte a perspectiva: dado o conjunto de dados que efetivamente observamos, quais valores de e tornam esses dados os mais prováveis possíveis? Assumindo exemplos independentes, a verossimilhança do conjunto inteiro é o produto das densidades individuais, e queremos o que a maximiza:
![\[L(w, b) = \prod_{i=1}^{m} p\left(y^{(i)} \mid x^{(i)}; w, b\right).\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-f520cabdbcca386864038f2855c392d0_l3.png "Rendered by QuickLaTeX.com")
Maximizar um produto de muitos termos é numericamente instável e analiticamente desagradável. O artifício clássico é aplicar o logaritmo, que é monotônico crescente e portanto preserva o ponto de máximo, transformando o produto em soma. Substituindo a gaussiana e simplificando, a log-verossimilhança fica
![\[\log L(w, b) = -\frac{m}{2}\log(2\pi\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^{m} \left(y^{(i)} - f_{w,b}(x^{(i)})\right)^2.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-d97ed8258a1adafef41b2d0c004d445e_l3.png "Rendered by QuickLaTeX.com")
O primeiro termo é constante em relação a e , e portanto irrelevante para a maximização. O segundo é um múltiplo negativo da nossa soma de erros quadráticos. Maximizar algo negativo equivale a minimizar o positivo, de modo que
![\[\arg\max_{w,b} \log L(w, b) = \arg\min_{w,b} \sum_{i=1}^{m} \left(y^{(i)} - f_{w,b}(x^{(i)})\right)^2.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-51d73a515cdc615a0064347dfa2af0eb_l3.png "Rendered by QuickLaTeX.com")
Esse é o resultado central. Maximizar a verossimilhança sob a hipótese de ruído gaussiano é matematicamente equivalente a minimizar o MSE. O erro quadrático não foi escolhido por ser conveniente; ele decorre da suposição de que o ruído dos dados é gaussiano. Tivéssemos assumido outra distribuição, teríamos outra loss.
Uma consequência verificável: se a hipótese é razoável, os resíduos do modelo treinado devem parecer ruído gaussiano centrado em zero.
residuos = y - modelo(x, w, b)
print(f"média dos resíduos = {residuos.mean():.3f} (esperado ~ 0)")
print(f"desvio padrão = {residuos.std():.3f}")
média dos resíduos = 0.000 (esperado ~ 0) desvio padrão = 1.363
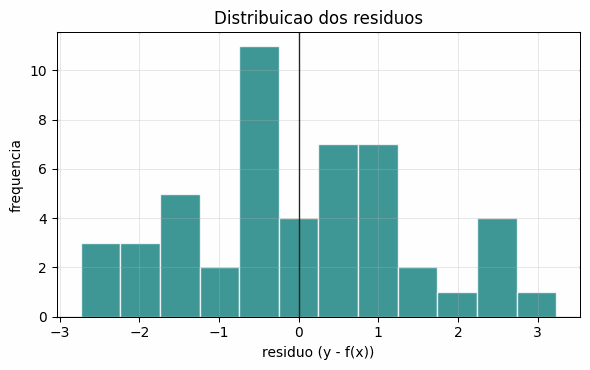
Os resíduos têm média praticamente nula e se distribuem de forma aproximadamente simétrica em torno de zero, exatamente o comportamento que a hipótese gaussiana prevê.
Por que essa mudança de perspectiva importa
Com esse ponto de vista, várias coisas que antes pareciam arbitrárias se tornam consequências. A classificação usa cross-entropy porque o alvo não é um número contínuo com ruído gaussiano, e sim uma resposta discreta, modelada por uma distribuição de Bernoulli. A regressão de contagem usa a loss de Poisson porque contagens seguem uma distribuição de Poisson. O procedimento é sempre o mesmo: escolher uma distribuição para os dados, escrever a verossimilhança, aplicar o logaritmo e inverter o sinal. O que muda de um caso para outro é apenas a distribuição.
É exatamente esse o caminho do próximo artigo. Vamos trocar o ruído gaussiano pela distribuição de Bernoulli e aplicar o mesmo procedimento, do qual vai surgir, naturalmente, a binary cross-entropy da classificação. A operação de “erro vezes entrada” que derivamos aqui para o gradiente continuará valendo, sustentando mais adiante até o treinamento das redes neurais multicamadas. A lição que vale para o resto da série é que toda função de custo é uma escolha de distribuição de probabilidade disfarçada.
Takeaways
- A função de custo resume o erro do modelo em um único número. O MSE penaliza erros grandes de forma desproporcional e, por ser suave e diferenciável, é adequado à otimização por derivadas.
- A superfície da regressão linear é uma tigela convexa, com um único mínimo global, o que garante que o gradient descent encontre a melhor solução.
- O gradient descent treina o modelo usando apenas derivadas locais. No experimento, recuperou os parâmetros geradores (
 ,
,  ) sem nunca enxergar a superfície inteira, e a atualização tem a forma “erro vezes entrada”.
) sem nunca enxergar a superfície inteira, e a atualização tem a forma “erro vezes entrada”. - O MSE é uma consequência, não uma escolha. Minimizá-lo é equivalente a maximizar a verossimilhança sob ruído gaussiano. Trocar a distribuição do ruído gera outra loss, e é assim que surge a cross-entropy da classificação.



















