
Você já treinou uma rede neural, mas não faz ideia do que ela está olhando para tomar essa decisão? A verdade é que redes neurais profundas, especialmente modelos de _deep learning_, funcionam como caixas-pretas. Você alimenta uma imagem, recebe uma predição, mas o que acontece entre a entrada e a saída permanece um mistério.
O Grad-CAM (Gradient-weighted Class Activation Mapping) resolve exatamente isso. Ele gera um mapa de calor que mostra quais regiões da imagem foram mais importantes para a decisão do modelo. É como pedir para a rede neural pegar um marca-texto e destacar o que ela olhou antes de responder.
Neste artigo, vamos implementar o Grad-CAM do zero com PyTorch, aplicá-lo a uma ResNet18 treinada para classificar 102 espécies de flores, e analisar visualmente o que muda quando o modelo acerta e quando ele erra.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O Que É Grad-CAM?
Redes convolucionais aprendem filtros hierárquicos: as primeiras camadas detectam bordas e texturas, as intermediárias combinam esses padrões em partes de objetos, e as últimas reconhecem objetos inteiros. Se você quer saber o que sua rede aprendeu, o lugar certo para olhar é justamente a última camada convolucional, onde os filtros carregam a informação mais rica e abstrata sobre a imagem.
O Grad-CAM, proposto por Selvaraju et al. (ICCV 2017), faz exatamente isso. Ele usa os gradientes que fluem para a última camada convolucional para calcular a importância de cada canal de ativação. Canais que influenciam fortemente a predição de uma classe recebem peso alto. Canais irrelevantes recebem peso baixo. O resultado é um mapa de calor que destaca as regiões da imagem que mais contribuíram para a decisão.
Pense assim: quando você pergunta “por que você acha que isso é uma rosa?”, o Grad-CAM é a resposta visual da rede. Ele aponta para as pétalas, para o formato da flor, para as características que levaram àquela classe.
Como Funciona: Dos Gradientes ao Mapa de Calor
O algoritmo do Grad-CAM tem quatro passos:
- Forward pass: a imagem passa pela rede normalmente. Capturamos as ativações da última camada convolucional (um tensor com vários canais, cada um destacando padrões diferentes).
- Backward pass: fazemos backpropagation a partir da classe predita. Capturamos os gradientes que chegam naquela mesma camada.
- Pesos por canal: para cada canal, calculamos a média global dos gradientes (Global Average Pooling). Isso nos dá um peso escalar por canal, que representa “o quanto esse canal importa para a classe predita”.
- Combinação ponderada: multiplicamos cada mapa de ativação pelo seu peso e somamos tudo. Aplicamos ReLU para manter apenas as contribuições positivas. O resultado é o mapa de calor Grad-CAM.
Em termos matemáticos:
![\[\alpha_k = \frac{1}{Z} \sum_i \sum_j \frac{\partial y^c}{\partial A^k_{ij}}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-1130ca3759def9be519a74b73d6b905f_l3.png "Rendered by QuickLaTeX.com")
![\[L_{\text{Grad-CAM}} = \text{ReLU}\left(\sum_k \alpha_k \cdot A^k\right)\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-3455b68ab995086b7fbeb9f299f5c1fa_l3.png "Rendered by QuickLaTeX.com")
Onde  é o peso do canal
é o peso do canal  ,
,  é o mapa de ativação desse canal e
é o mapa de ativação desse canal e  é o score da classe
é o score da classe  . O ReLU garante que só regiões com influência positiva apareçam no mapa.
. O ReLU garante que só regiões com influência positiva apareçam no mapa.
Implementação com PyTorch Hooks
A parte mais elegante da implementação é que não precisamos modificar a arquitetura da rede. O PyTorch oferece hooks, que são funções que interceptam ativações e gradientes durante o forward e o backward pass.
Vamos criar uma classe GradCAM que registra hooks na saída do último bloco residual de uma ResNet18, layer4[-1]. Essa posição captura as ativações após batch normalization, skip connection e ReLU, sendo a prática padrão na literatura:
class GradCAM:
def __init__(self, model, target_layer):
self.model = model
self.activations = None
self.gradients = None
# Registrar hooks e salvar handles para remoção
self._fwd_handle = target_layer.register_forward_hook(self._save_activation)
self._bwd_handle = target_layer.register_full_backward_hook(self._save_gradient)
def _save_activation(self, module, input, output):
self.activations = output.detach()
def _save_gradient(self, module, grad_input, grad_output):
self.gradients = grad_output[0].detach()
Os dois hooks fazem todo o trabalho pesado. O forward hook salva as ativações quando a imagem passa pela camada. O backward hook salva os gradientes quando fazemos backpropagation. Salvamos os handles retornados para poder remover os hooks depois, evitando vazamento de memória.
Agora, o método que gera o mapa de calor e o método que remove os hooks:
def generate(self, input_img, class_idx=None):
assert input_img.size(0) == 1, "GradCAM espera batch_size=1"
self.model.eval()
output = self.model(input_img)
if class_idx is None:
class_idx = output.argmax(dim=1).item()
self.model.zero_grad()
output[0, class_idx].backward()
# Pesos: média global dos gradientes por canal
weights = self.gradients.mean(dim=[2, 3], keepdim=True)
# Mapa de ativação ponderado
cam = (weights * self.activations).sum(dim=1, keepdim=True)
cam = torch.relu(cam)
# Normalizar entre 0 e 1
cam = cam - cam.min()
if cam.max() > 0:
cam = cam / cam.max()
return cam.squeeze().cpu().numpy(), class_idx
def remove(self):
"""Remove os hooks registrados para evitar vazamento de memória."""
self._fwd_handle.remove()
self._bwd_handle.remove()
O weights.mean(dim=[2, 3]) é o Global Average Pooling dos gradientes. Cada canal recebe um peso escalar. A multiplicação weights * self.activations pondera cada mapa de ativação pela sua importância. A soma e o ReLU produzem o mapa final. A interpolação para 224×224 é feita na função de visualização, mantendo a classe GradCAM reutilizável.
Visualizando Onde a Rede Foca
Aplicamos o Grad-CAM a uma ResNet18 que foi ajustada com transfer learning e fine-tuning no dataset Oxford Flowers 102, alcançando ~92% de acurácia na validação e ~90% no teste. O modelo aprendeu a distinguir 102 espécies de flores.
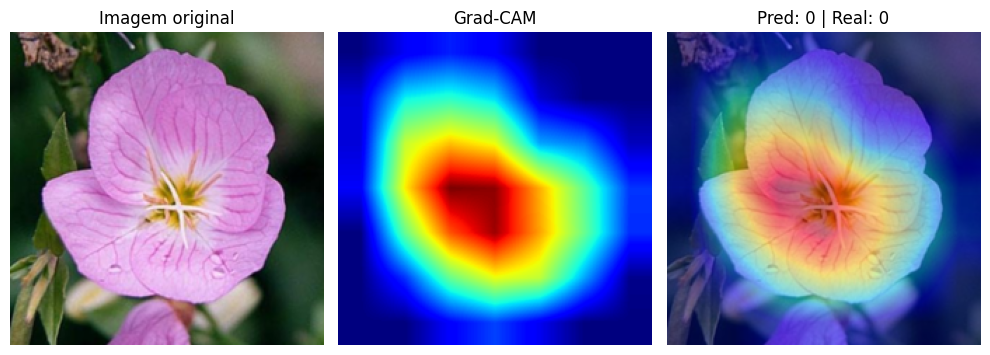
Para a visualização, sobrepomos o mapa de calor à imagem original com transparência (alpha = 0.5). As regiões em vermelho e amarelo indicam onde a rede concentrou sua atenção. As regiões em azul foram praticamente ignoradas.
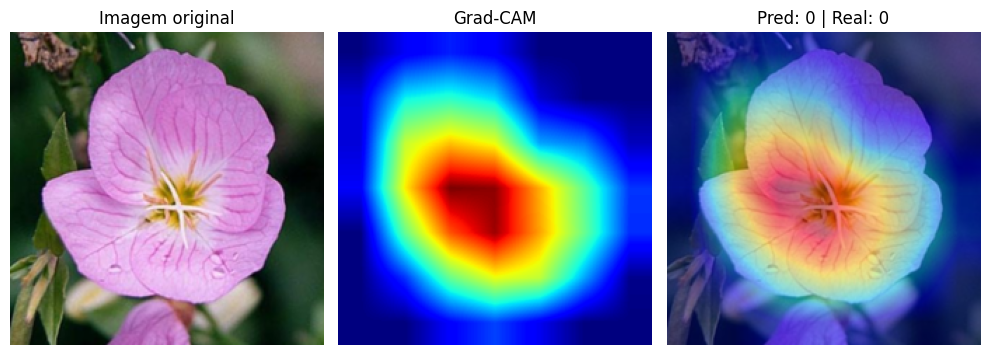
Nas predições corretas, o padrão é claro: a rede foca nas pétalas, no formato e na estrutura central da flor. Ela aprendeu a ignorar folhas, caule e fundo, concentrando sua atenção nas características que realmente diferenciam uma espécie da outra. É exatamente o que um botânico faria ao classificar uma flor pela aparência.
O Que Muda Quando o Modelo Erra?
Aqui fica interessante. Quando analisamos as predições incorretas com Grad-CAM, o mapa de calor revela por que o modelo se confundiu.
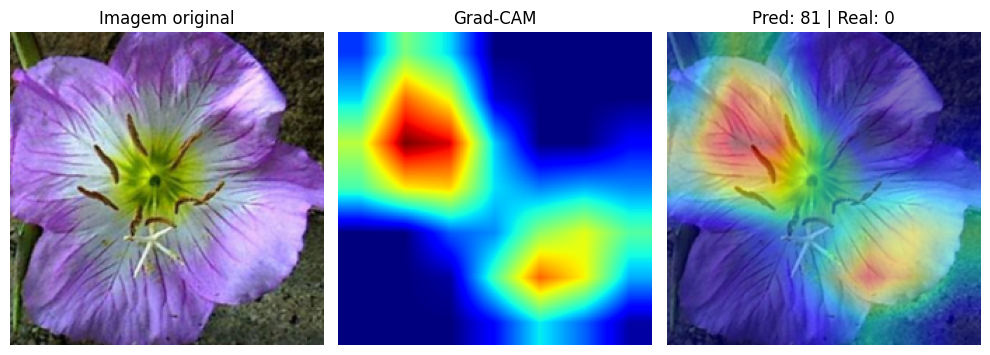
Nos erros, a rede frequentemente foca em regiões do fundo, bordas ou partes pouco informativas da imagem. Em vez de olhar para as pétalas, ela pode dar atenção ao caule, às folhas ou até à textura do fundo. O modelo não está necessariamente “quebrado”. Ele pode estar usando atalhos visuais que funcionaram no treino mas não generalizam para aquela imagem específica.
Essa análise é extremamente valiosa na prática. Se você está desenvolvendo um modelo para produção, o Grad-CAM permite diagnosticar falhas sistemáticas. Se o modelo consistentemente erra olhando para o fundo, talvez o dataset tenha viés (flores vermelhas sempre fotografadas com fundo verde, por exemplo). Sem o Grad-CAM, você veria apenas o número de erros, sem entender a causa.
Por Que Isso Importa?
Explicabilidade não é um luxo acadêmico. Em aplicações reais de visão computacional, entender o que o modelo aprendeu é tão importante quanto a acurácia.
Na medicina, um modelo que classifica tumores olhando para a régua de escala na imagem em vez do tecido é perigoso, mesmo que tenha acurácia alta no teste. Na indústria, um sistema de inspeção visual que foca no fundo da esteira em vez da peça pode causar defeitos não detectados. O Grad-CAM transforma a caixa-preta em algo auditável.
Além disso, o Grad-CAM funciona com qualquer CNN. Se você já tem uma rede treinada, basta registrar os hooks na última camada convolucional. Não precisa retreinar, não precisa modificar a arquitetura. São poucas linhas de código para ganhar uma camada inteira de interpretabilidade.
Takeaways
- Grad-CAM gera mapas de calor que mostram onde a CNN olha. Ele usa os gradientes da última camada convolucional para calcular a importância de cada canal de ativação, produzindo um mapa visual das regiões mais relevantes para a predição.
- A implementação com PyTorch hooks é simples e não invasiva. Basta registrar um forward hook (ativações) e um backward hook (gradientes) na camada desejada. Nenhuma modificação na arquitetura da rede é necessária.
- Predições corretas focam nas features certas. Nas classificações corretas do Oxford Flowers 102, a rede concentrou atenção nas pétalas e na estrutura da flor, ignorando fundo e folhagem.
- Predições erradas revelam o motivo do erro. Quando o modelo erra, o Grad-CAM mostra que a atenção se dispersa para regiões irrelevantes. Isso permite diagnosticar falhas sistemáticas e viés no dataset.
- Explicabilidade é essencial para produção. Um modelo com 90% de acurácia que olha para o lugar errado pode ser mais perigoso do que um com 85% que olha para o lugar certo. O Grad-CAM permite auditar essa diferença.
O Grad-CAM é especialmente útil em tarefas de visão computacional onde a confiança no modelo precisa ser justificada. Se quiser aprofundar seus conhecimentos, confira os melhores cursos para aprender deep learning.



















