A qualidade da imagem de entrada é uma das variáveis mais negligenciadas em pipelines de visão computacional. Modelos treinados em datasets curados sofrem degradação significativa de performance quando recebem imagens borradas em produção.
O problema é antigo e bem estudado. Desde o trabalho de Liu et al. (CVPR 2008) sobre detecção de blur parcial, a análise espectral se consolidou como uma das abordagens mais elegantes para o problema.
A ideia central é que o desfoque atua como um filtro passa-baixas no domínio da frequência, atenuando bordas e detalhes finos. A Transformada de Fourier permite quantificar essa atenuação diretamente.
Neste artigo, vamos implementar um detector de blur baseado na FFT 2D com NumPy e OpenCV, validar seu comportamento em um experimento controlado de blur progressivo, e comparar com a variância do Laplaciano.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Por que a FFT detecta blur?
A intuição é surpreendentemente simples. Pense em uma imagem nítida: ela tem bordas bem definidas, texturas detalhadas, transições abruptas entre regiões claras e escuras. Se você já trabalhou com equalização de histograma com OpenCV, sabe que imagens carregam muita informação na distribuição de intensidades. No domínio da frequência, esses detalhes se traduzem como altas frequências.

Agora pense em uma imagem borrada. As bordas ficam suaves, os detalhes somem, as transições viram gradientes lentos. Em termos de frequência, é como se alguém tivesse passado um filtro e removido justamente as altas frequências.
E é exatamente isso que acontece. Do ponto de vista matemático, o blur gaussiano é uma convolução com um kernel que atua como filtro passa-baixas:
![\[g(x, y) = f(x, y) * h(x, y)\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-612978261eafe1c8c466bb967c07a241_l3.png "Rendered by QuickLaTeX.com")
No domínio da frequência, essa convolução se torna uma multiplicação:
![\[G(u, v) = F(u, v) \cdot H(u, v)\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-89fc9410a1fcc16f14c87d55d0ec457a_l3.png "Rendered by QuickLaTeX.com")
Se  é um kernel gaussiano, então
é um kernel gaussiano, então  preserva as baixas frequências e atenua as altas. O resultado é uma imagem com menos detalhes — ou seja, borrada.
preserva as baixas frequências e atenua as altas. O resultado é uma imagem com menos detalhes — ou seja, borrada.
A Transformada de Fourier nos permite enxergar essa diferença diretamente. Veja os espectros de magnitude de uma imagem nítida e uma borrada:

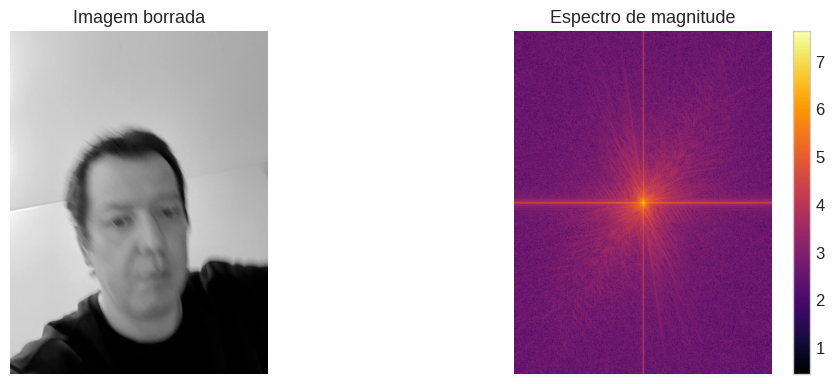
Na imagem nítida, a energia se espalha por todo o espectro. As linhas irradiando do centro representam bordas e texturas em várias direções. Na imagem borrada, quase toda a energia está concentrada no centro. As altas frequências praticamente desapareceram.
Como funciona a detecção de blur com FFT?
A ideia do detector é medir quanta energia resta nas altas frequências. Se houver pouca, a imagem provavelmente está borrada. O algoritmo segue cinco passos:
- Calcular a FFT 2D da imagem e centralizar o espectro com
fftshift. - Criar uma máscara circular e zerar a região central — removendo as baixas frequências.
- Aplicar a FFT inversa para reconstruir apenas o conteúdo de altas frequências.
- Calcular a média da magnitude desse sinal reconstruído.
- Comparar com um limiar: se a média estiver abaixo, a imagem é considerada borrada.
Vamos à implementação. Primeiro, carregamos as imagens e convertemos para tons de cinza:
import numpy as np
import cv2
# Carregar imagens e converter para tons de cinza
img_nitida = cv2.imread("imagem_nitida.jpg")
img_borrada = cv2.imread("imagem_borrada.jpg")
gray_nitida = cv2.cvtColor(img_nitida, cv2.COLOR_BGR2GRAY)
gray_borrada = cv2.cvtColor(img_borrada, cv2.COLOR_BGR2GRAY)
Agora, a função principal do detector:
def detect_blur_fft(image, size=60, thresh=5):
"""
Detecta se uma imagem em tons de cinza está borrada usando FFT.
Retorna (média da magnitude, True se borrada).
"""
h, w = image.shape
cy, cx = h // 2, w // 2
# FFT 2D + centralizar componente DC
fft = np.fft.fft2(image)
fft_shift = np.fft.fftshift(fft)
# Máscara circular: zerar baixas frequências (raio <= size)
Y, X = np.ogrid[:h, :w]
dist = np.sqrt((X - cx)**2 + (Y - cy)**2)
fft_shift[dist <= size] = 0
# FFT inversa: reconstruir apenas altas frequências
recon = np.fft.ifft2(np.fft.ifftshift(fft_shift))
# Métrica: média da magnitude (sempre >= 0)
mean_mag = np.mean(np.abs(recon))
return mean_mag, mean_mag <= thresh
Alguns detalhes importantes sobre a implementação:
- A máscara circular é mais adequada do que uma quadrada porque queremos remover todas as frequências abaixo de um determinado módulo, independentemente da orientação, e a distância ao centro no espectro corresponde exatamente ao módulo da frequência espacial.
- Usamos
np.mean(np.abs(recon))como métrica. Ela é sempre não-negativa e monotonicamente relacionada ao conteúdo de alta frequência: quanto maior o valor, mais energia de alta frequência resta na imagem. O valor absoluto depende da resolução e do conteúdo da cena, então o limiar deve ser calibrado por aplicação. - O parâmetro
sizecontrola o raio da máscara. Valores maiores removem mais frequências, tornando o detector mais seletivo. Na prática,sizedeveria ser proporcional à dimensão da imagem. Para imagens de resolução maior, um raio proporcionalmente maior pode ser necessário.
Aplicando nas duas imagens:
mean_nitida, blur_nitida = detect_blur_fft(gray_nitida, size=60, thresh=5)
mean_borrada, blur_borrada = detect_blur_fft(gray_borrada, size=60, thresh=5)
print(f"Nítida — métrica: {mean_nitida:.2f} | {'BORRADA' if blur_nitida else 'NÍTIDA'}")
print(f"Borrada — métrica: {mean_borrada:.2f} | {'BORRADA' if blur_borrada else 'NÍTIDA'}")
O resultado:
Nítida — métrica: 9.03 | NÍTIDA Borrada — métrica: 2.30 | BORRADA
A imagem nítida retornou uma métrica de 9.03 (acima do limiar de 5), enquanto a borrada ficou em 2.30 (abaixo). O detector separou corretamente os dois casos.
Validando com blur progressivo
Para ganhar mais confiança no detector, vamos fazer um experimento: pegar a imagem nítida e aplicar borramentos gaussianos com kernels cada vez maiores, observando como a métrica decai.
kernels = list(range(1, 32, 2)) # 1, 3, 5, ..., 31
for k in kernels:
img_blur = cv2.GaussianBlur(gray_nitida, (k, k), 0) if k > 1 else gray_nitida
mean_val, is_blurry = detect_blur_fft(img_blur, size=60, thresh=5)
print(f"Kernel {k:2d} — métrica: {mean_val:.2f} — {'BORRADA' if is_blurry else 'NÍTIDA'}")
Kernel 1 — métrica: 9.03 — NÍTIDA Kernel 3 — métrica: 6.00 — NÍTIDA Kernel 5 — métrica: 4.81 — BORRADA Kernel 7 — métrica: 3.54 — BORRADA ... Kernel 31 — métrica: 0.89 — BORRADA
A métrica decai monotonicamente, como esperado, cada nível de blur remove mais altas frequências. O gráfico abaixo mostra a curva completa:
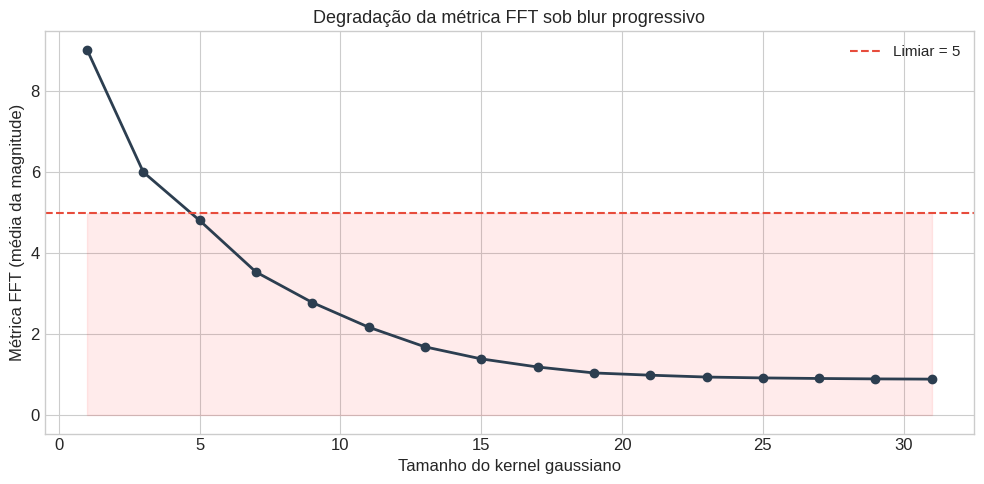
A linha tracejada vermelha marca o limiar. Os pontos acima são classificados como nítidos, os abaixo como borrados. A transição acontece por volta do kernel 5, o que é razoável. Com kernel 3 a imagem ainda é aceitável, mas a partir de 5 o desfoque já é perceptível.
O que acontece no espectro?
Para consolidar a intuição, vale a pena visualizar o espectro em diferentes níveis de blur. O painel abaixo mostra a imagem e seu espectro para kernels de 1 a 31:
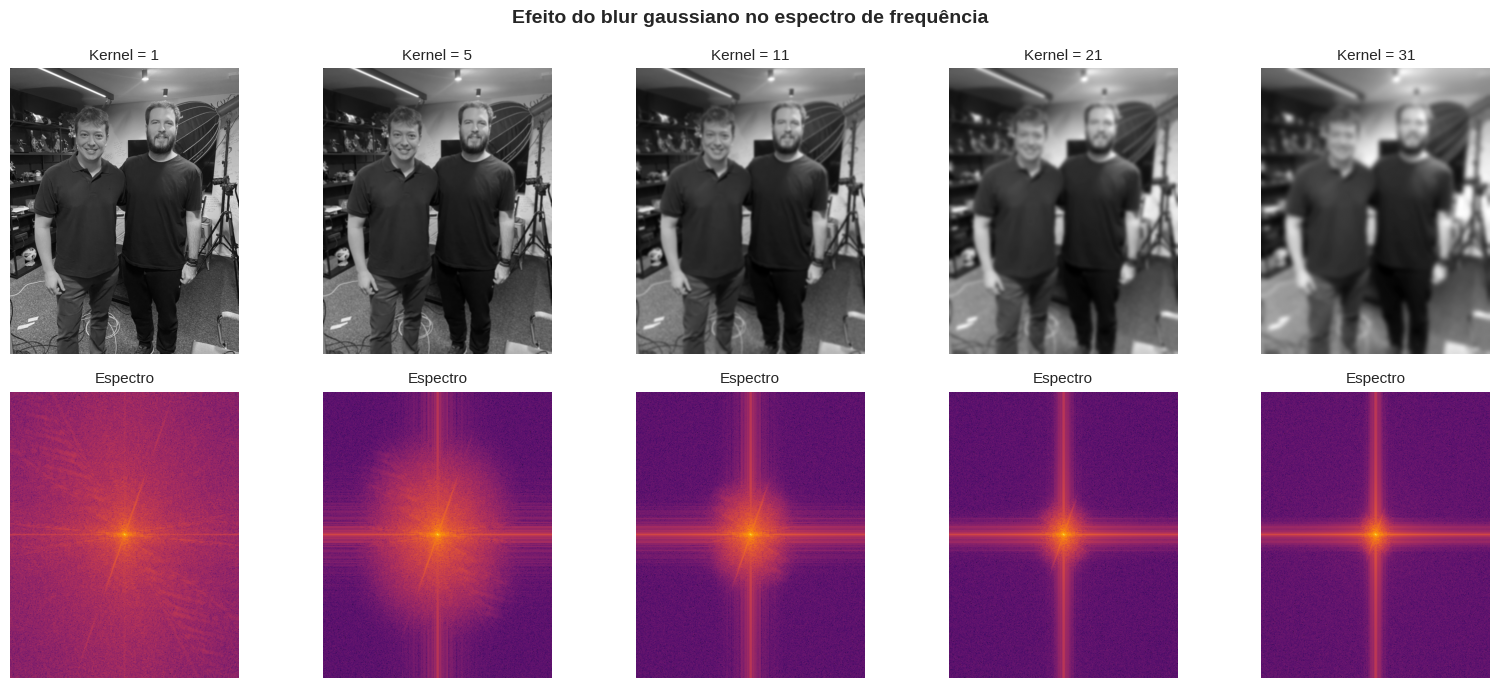
A progressão é clara: conforme o blur aumenta, o espectro se contrai em direção ao centro. Para kernel 31, praticamente toda a energia está concentrada num ponto. Essa é a assinatura visual de uma imagem severamente borrada.
FFT vs. variância do Laplaciano
O detector via FFT não é a única opção. O método mais popular e simples para detecção de blur é a variância do Laplaciano, proposta por Pech-Pacheco et al. (ICPR 2000). A ideia é aplicar o operador Laplaciano (segunda derivada) e medir a variância do resultado:
def variancia_laplaciano(image):
"""Variância do Laplaciano como métrica de nitidez."""
return cv2.Laplacian(image, cv2.CV_64F).var()
Uma linha. É difícil ser mais simples que isso. Como as duas abordagens se comparam no experimento de blur progressivo?
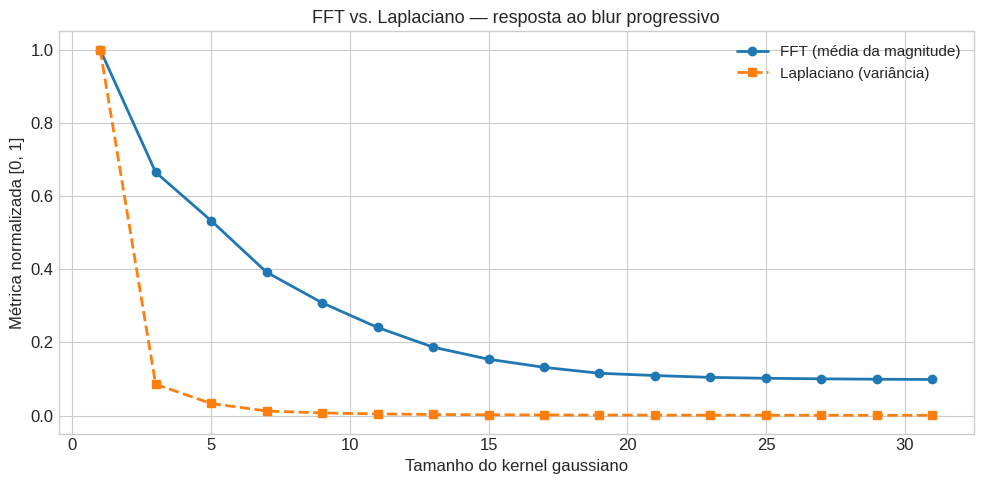
Ambas as métricas decaem com o blur, mas com comportamentos distintos. O Laplaciano cai muito mais rápido. Com kernel 5, já está perto de zero. A FFT decai mais gradualmente, mantendo sensibilidade em níveis intermediários de blur.
Isso faz sentido: a variância do Laplaciano, sendo baseada na segunda derivada, pondera desproporcionalmente as frequências mais altas. Quando o blur as atenua, a métrica despenca. Já a métrica baseada na FFT mede a magnitude média com peso uniforme nas altas frequências, o que produz um decaimento mais gradual.
Na prática, ambos funcionam bem como baseline. A escolha depende do que você precisa: o Laplaciano é mais simples, mais rápido, e não requer parâmetros (não tem equivalente ao size). A FFT oferece mais controle via tamanho da máscara e mantém sensibilidade em níveis intermediários de blur.
Quando o detector falha?
Nenhum método é perfeito. Existem cenários onde o detector FFT pode dar resultados incorretos:
- Imagens com pouca textura: um céu limpo ou uma parede branca têm poucas altas frequências mesmo sem blur, gerando falsos positivos.
- Blur parcial: se apenas parte da imagem está borrada (foco seletivo), a métrica global pode não capturar o problema.
- Tipos diferentes de blur: blur de movimento atenua frequências em uma direção específica, enquanto o gaussiano atenua uniformemente. O detector trata ambos da mesma forma.
- Compressão JPEG: artefatos de compressão introduzem altas frequências espúrias (blocos 8×8), o que pode mascarar o blur e gerar falsos negativos.
- Ruído: imagens com ruído intenso (ISO alto, imagens médicas) apresentam altas frequências elevadas mesmo quando borradas, também gerando falsos negativos.
- Sensibilidade ao limiar: o valor de
threshprecisa ser calibrado para cada aplicação, dependendo da resolução e do conteúdo das imagens.
Para cenários mais robustos, considere análise por patches (como no paper original de Liu et al.), métricas complementares ou modelos de deep learning treinados para classificação de blur.
Takeaways
- Blur é filtragem passa-baixas: o desfoque gaussiano atenua altas frequências, e a FFT permite visualizar e medir isso diretamente.
- O detector é simples e eficaz: zerar o centro do espectro e medir a magnitude restante separa imagens nítidas de borradas com poucas linhas de código.
- Máscara circular é mais adequada: a distância ao centro no espectro corresponde ao módulo da frequência espacial, e a máscara circular respeita essa geometria.
- A variância do Laplaciano é uma alternativa prática: uma única linha de código e desempenho comparável, ideal quando você precisa de algo rápido.
- Ambos os métodos servem como baseline: para controle de qualidade de imagens em pipelines de visão computacional, essas métricas clássicas continuam relevantes mesmo na era do deep learning.



















