
Estimativa de profundidade monocular é uma tarefa da Visão Computacional, que consiste em prever as informações de profundidade de uma cena, ou seja, a distância relativa à câmera de cada pixel, dada uma única imagem RGB.
Esta tarefa desafiadora é um pré-requisito chave para determinar o entendimento da cena para aplicações como a reconstrução de cena 3D, robótica, Computação Espacial (Apple Vision Pro e Quest 3) e navegação autônoma. Aplicações como essas explicam por que o engenheiro de visão computacional é um dos profissionais mais demandados da indústria.

Enquanto várias abordagens foram desenvolvidas para a estimativa de profundidade, Depth Anything representa hoje um avanço significativo no campo da percepção de profundidade monocular.
Neste artigo nós exploraremos algumas das bases teóricas da percepção de profundidade monocular, e clonaremos o repositório Depth Anything para fazermos nossos próprios testes em um ambiente de desenvolvimento local.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Percepção de Profundidade Monocular
A percepção de profundidade é o que nos permite interpretar o mundo tridimensional a partir de imagens bidimensionais projetadas em nossas retinas. Essa habilidade evoluiu como um aspecto crucial para a sobrevivência, possibilitando aos humanos navegar pelo ambiente, evitar predadores e localizar recursos.
O cérebro humano realiza essa façanha por meio de uma série de interpretações das informações visuais, onde a sobreposição do campo visual binocular fornece uma rica percepção de profundidade.
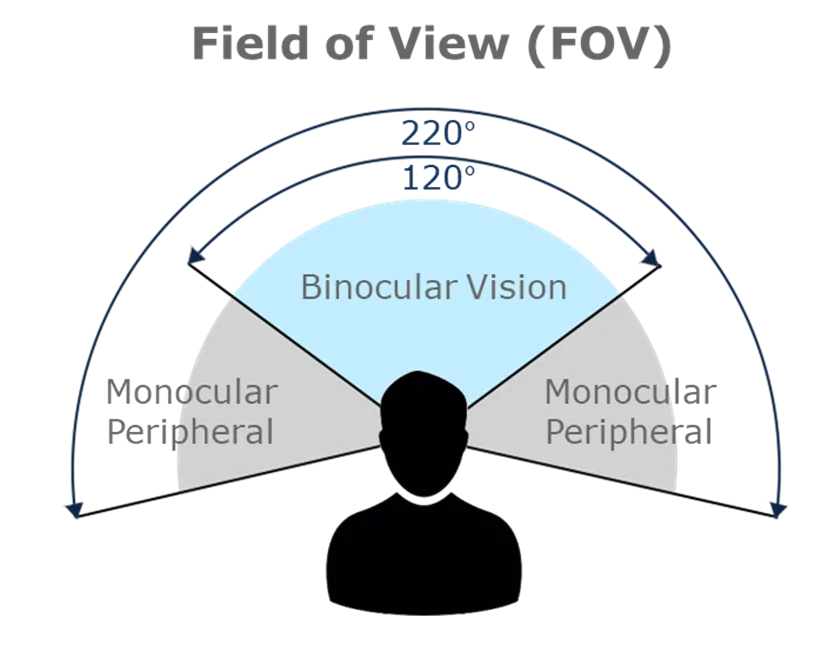
Além da visão binocular, essa percepção é enriquecida por várias pistas monoculares (depth cues), elementos no ambiente que permitem ao observador único inferir a profundidade mesmo com um olho fechado. Entre essas pistas estão occlusão, tamanho relativo, sombras projetadas, e perspectiva linear.
Esses mesmos princípios e mecanismos de percepção encontram um paralelo na Visão Computacional, onde a essência da estimativa também reside em capturar a estrutura espacial de uma cena para representar com precisão seus aspectos tridimensionais.
Depth Anything para Estimativa de Profundidade
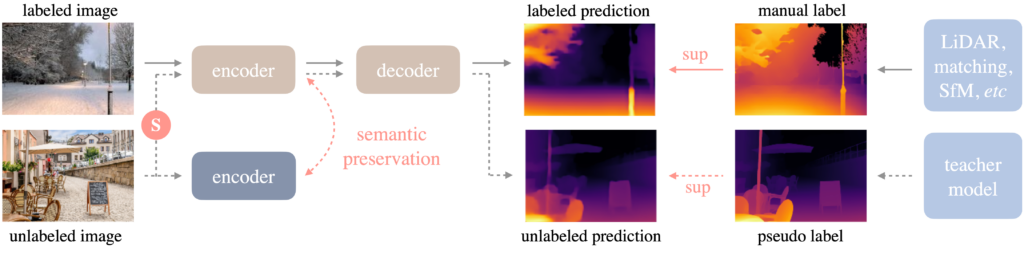
O modelo Depth Anything, introduzido no trabalho “Depth Anything: Unleashing the Power of Large-Scale Unlabeled Data”, representa um avanço significativo em estimativa de profundidade monocular. Baseado na arquitetura DPT (Dense Prediction Transformer), foi treinado em um vasto conjunto de dados com mais de 62 milhões de imagens não rotuladas.

O sucesso desta abordagem é atribuído a duas estratégias principais.
- A utilização de ferramentas de data augmentation para estabelecer um target de otimização mais desafiador.
- Uso de supervisão auxiliar para assegurar a herança de priores semânticos a partir de codificadores pré-treinados.
A capacidade de generalização do Depth Anything, testada em seis conjuntos de dados públicos e em fotografias capturadas aleatoriamente, superou algumas métricas de modelos existentes, como MiDaS v3.1 e ZoeDepth.
Caso você queria se aprofundar mais nos materiais e métodos utilizados na pesquisa, acesse o artigo original neste link.
Configuração do Ambiente para “Depth Anything”
Para começar a usar o Depth Anything para estimativa de profundidade monocular, é necessário preparar seu ambiente de desenvolvimento seguindo alguns passos simples. Certifique-se de que você tem o Poetry instalado.
Para clonar o repositório e instalar as dependências, siga o passo a passo descrito abaixo:
1. Clone o Repositório: Primeiramente, clone o repositório do projeto utilizando o comando no terminal:
git clone https://github.com/LiheYoung/Depth-Anything.git
2. Acesse o Diretório do Projeto: Em seguida, acesse o diretório do projeto:
cd Depth-Anything
3. Inicialize o Ambiente com Poetry: Se for a primeira vez usando Poetry neste projeto, inicialize o ambiente:
poetry init
4. Ative o Ambiente Virtual: Ative o ambiente virtual criado pelo Poetry:
poetry shell
5. Instale as Dependências: Instale as dependências necessárias, incluindo Gradio, PyTorch, torchvision, opencv-python e huggingface_hub:
poetry add gradio==4.14.0 torch torchvision opencv-python huggingface_hub
6. Execute o Aplicativo: Execute o aplicativo usando Streamlit com o comando:
python app.py
Com o app Streamlit rodando, você pode carregar suas fotos diretamente pela UI. Caso você tenha alguma dificuldade ao instalar as dependências no seu computador, você também consegue testar o Depth Anything nesta demo oficial.
Mas se você quiser acessar o passo a passo em vídeo, eu disponibilizei uma aula completa no meu curso de Visão Computacional.
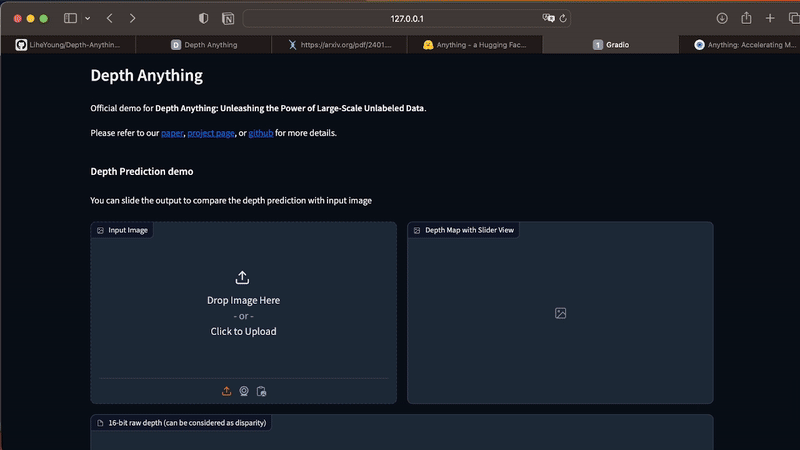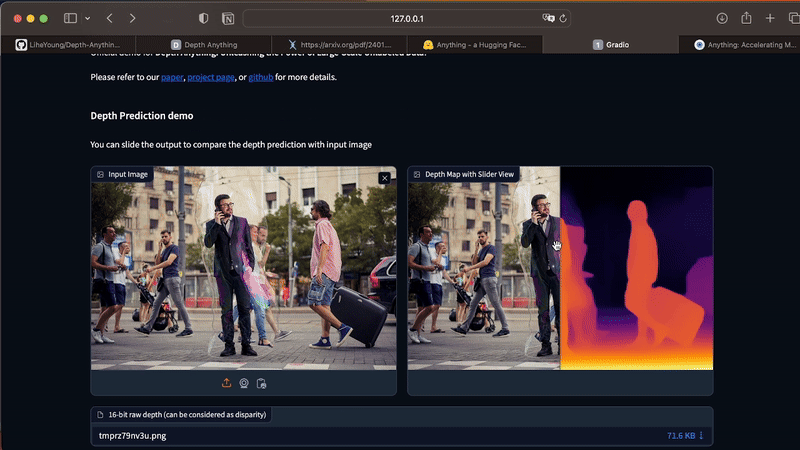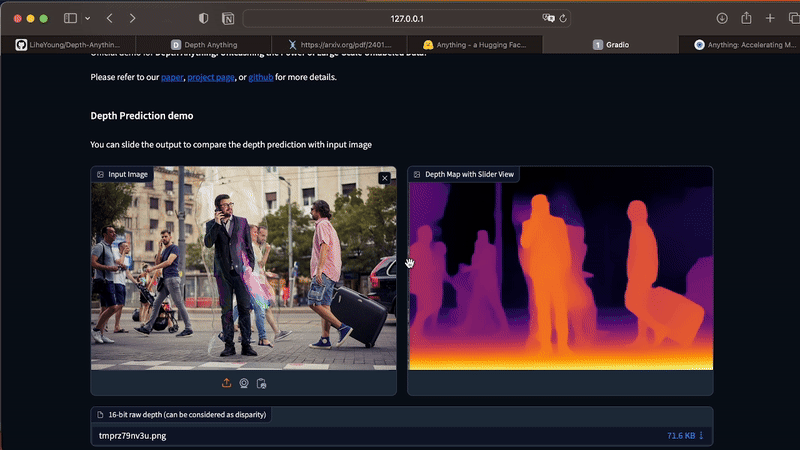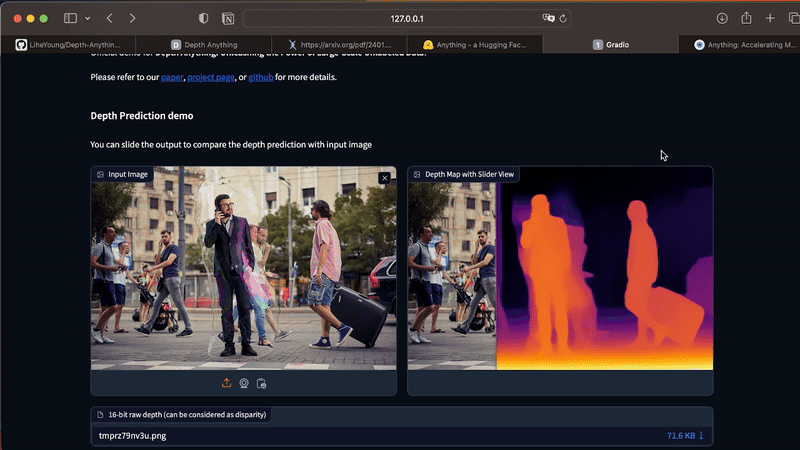
O app funciona apenas para imagens estáticas. Para gerar mapas de profundidade a partir de vídeos, execute o comando abaixo no seu Terminal. Como esse processo é custoso em termos de processamento, eu recomendo que você inicie seus testes com vídeos curtos, entre 3 e 10 segundos.
python run_video.py --encoder vitl --video-path /caminho/para/seu/video.mov --outdir /caminho/para/salvar
Takeaways
- Essência da Percepção de Profundidade Monocular: A estimativa de profundidade monocular é fundamental para compreender a estrutura espacial de uma cena a partir de uma única imagem, permitindo aplicações como reconstrução 3D de cenas com Gaussian Splatting.
- Avanços com Depth Anything: Representando um salto significativo na percepção de profundidade monocular, o modelo Depth Anything utiliza a arquitetura DPT e foi treinado em um conjunto de dados extenso, mostrando excelente capacidade de generalização.
- Configuração do Ambiente: Um guia passo a passo para configurar o ambiente de desenvolvimento para utilizar o Depth Anything, incluindo a instalação de dependências e a execução de aplicativos para testes práticos.
- Aplicação Prática: O artigo fornece instruções detalhadas para testar a estimativa de profundidade com imagens e vídeos, facilitando a experimentação prática e a visualização dos resultados do modelo Depth Anything.



















