Treinar o YOLOv9 em um conjunto de dados personalizado envolve etapas como preparação das imagens específicas para a tarefa de detecção, realizar as anotações e configurar corretamente o formato a ser exportado.
Neste artigo, vamos mostrar como treinar um modelo YOLOv9 em um dataset personalizado. Especificamente, vamos treinar um modelo de Visão Computacional capaz de detectar e rastrear foguetes da SpaceX. Mas caso você queira, poderá usar qualquer outro conjunto de dados.
Caso você seja aluno da minha Especialização em Visão Computacional, saiba que há uma aula inteira dedicada sobre o modelo.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O que é YOLOv9
Lançado em 21 de fevereiro de 2024, pelos pesquisadores Chien-Yao Wang, I-Hau Yeh e Hong-Yuan Mark Liao através do artigo “YOLOv9: Aprendendo o Que Você Quer Aprender Usando Informações de Gradiente Programável”, o novo modelo YOLOv9 demonstrou precisão superior em comparação com modelos YOLO anteriores.
Implementando conceitos como Informações de Gradiente Programável (PGI) para mitigar perdas de transmissão de dados em redes profundas, e Rede de Agregação de Camadas Eficientes Generalizadas (GELAN) para otimizar a eficiência dos parâmetros, você irá se surpreender com o desempenho da arquitetura inovadora.
Eu escrevi um artigo introdutório, então se você quer saber mais detalhes técnicos sobre o YOLOv9, confira este link.
Como Instalar o YOLOv9
Instalar o YOLOv9 não é tão simples quanto instalar pacotes do PyPI ou Conda, uma vez que ainda não há um pacote oficial disponível.
No entanto, para facilitar o processo de instalação e torná-lo acessível a todos, eu criei um fork do repositório original e um notebook do Google Colab para facilitar o aprendizado.
# Verifique se a GPU está ativada
!nvidia-smi
# Clone o repositório YOLOv9
!git clone https://github.com/carlosfab/yolov9.git
# Mude o diretório de trabalho atual para o repositório YOLOv9 clonado
%cd yolov9
# Instale as dependências necessárias do YOLOv9 a partir do arquivo requirements.txt
!pip install -r requirements.txt -q
Inicialmente, o comando !nvidia-smi é executado para verificar se uma GPU está ativa e disponível para uso. Após isso, o repositório YOLOv9 é clonado do GitHub usando !git clone https://github.com/carlosfab/yolov9.git.
O comando subsequente, %cd yolov9, navega para o diretório do repositório clonado. Por último, o comando !pip install -r requirements.txt -q instala todas as dependências necessárias listadas no arquivo requirements.txt de forma silenciosa.
# Importa as bibliotecas necessárias
import sys
import os
import requests
from tqdm.notebook import tqdm
from pathlib import Path
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
from IPython.display import display, Image
from PIL import Image as PILImage
# Configura os diretórios para código e dados
CODE_FOLDER = Path(".").resolve() # Diretório de código
WEIGHTS_FOLDER = CODE_FOLDER / "weights" # Diretório para pesos do modelo
DATA_FOLDER = CODE_FOLDER / "data" # Diretório para dados
# Cria os diretórios para pesos e dados, se eles não existirem
WEIGHTS_FOLDER.mkdir(exist_ok=True, parents=True)
DATA_FOLDER.mkdir(exist_ok=True, parents=True)
# Adiciona o diretório de código ao caminho do Python para importação de módulos
sys.path.append(str(CODE_FOLDER))
Para começar, importamos as bibliotecas necessárias para o nosso projeto. Com as importações concluídas, definimos então as seguintes variáveis-chave:
CODE_FOLDER: Especifica o caminho do diretório para o código, garantindo que todos os scripts e módulos estejam centralmente localizados para fácil acesso e gestão.WEIGHTS_FOLDER: Designa um diretório para armazenar os pesos do modelo.DATA_FOLDER: Este diretório é identificado para armazenar nossas amostras de dados. É usado para inferência após o modelo personalizado ter sido treinado.
# URLs dos arquivos de pesos
weight_files = [
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt"
]
# Itera sobre a lista de URLs para baixar os arquivos de pesos
for i, url in enumerate(weight_files, start=1):
filename = url.split('/')[-1]
response = requests.get(url, stream=True)
total_size_in_bytes = int(response.headers.get('content-length', 0))
block_size = 1024 # 1 Quilobyte
progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True, desc=f"Baixando arquivo {i}/{len(weight_files)}: {filename}")
with open(WEIGHTS_FOLDER / filename, 'wb') as file:
for data in response.iter_content(block_size):
progress_bar.update(len(data))
file.write(data)
progress_bar.close()
Este trecho de código baixa os arquivos de pesos do modelo YOLOv9 a partir dos URLs fornecidos. Ele itera pela lista weight_files, buscando cada arquivo via requisições HTTP e salvando-os no WEIGHTS_FOLDER.
Como Treinar um Modelo YOLOv9 com Dados Personalizados
Criar um conjunto de dados personalizado do zero, o que envolve coletar imagens, anotá-las e formatá-las corretamente, pode ser muito trabalhoso e demorado.
Felizmente, a Roboflow revolucionou essa tarefa, tornando-a significativamente mais simples e eficiente. Vamos ver como isso funciona na prática.
Com a missão Starship Flight 3 agendada para meados de março de 2024, é a oportunidade perfeita treinarmos um modelo capaz de identificar e rastrear foguetes. Utilizaremos este conjunto de dados da Roboflow para treinar nosso modelo.
Este conjunto de dados é estruturado em três classes principais para auxiliar na identificação e rastreamento de elementos associados a lançamentos de foguetes. As classes são definidas da seguinte forma:
- Engine Flames: Captura as chamas produzidas pelo motor do foguete durante o lançamento.
- Rocket Body: Representa o corpo principal do veículo de lançamento, incluindo todas as seções estruturais do foguete.
- Space: Tipicamente retratado como um ponto distante na imagem.
A versão mais recente do conjunto de dados Rocket Detect é extensa, compreendendo mais de 28.000 imagens. Para evitar sessões prolongadas no Colab, utilizaremos a versão 36 do conjunto de dados, que inclui 12.041 imagens.
# Instalação da biblioteca Roboflow
!pip install -q roboflow
# Importação da biblioteca Roboflow
import roboflow
# Autenticação no Roboflow
roboflow.login() # Nota: Certifique-se de configurar sua chave API do Roboflow antes de chamar login()
# Inicialização do cliente Roboflow
rf = roboflow.Roboflow()
# Download do conjunto de dados
project = rf.workspace("nasaspaceflight").project("rocket-detect")
dataset = project.version(36).download("yolov9")
Neste bloco, estamos instalando a biblioteca Roboflow usando !pip install -q roboflow. Após isso, autenticamos no Roboflow executando roboflow.login(), o que necessita de uma chave API que deve ser configurada após você criar sua conta.
Em seguida, instanciamos o cliente Roboflow com rf = roboflow.Roboflow(). Para preparar nosso conjunto de dados para o YOLOv9, identificamos nosso projeto dentro do espaço de trabalho do Roboflow por meio de project = rf.workspace("nasaspaceflight").project("rocket-detect"), e então baixamos a versão 36 do conjunto de dados, que é especificamente formatada para o YOLOv9, usando dataset = project.version(36).download("yolov9").
Treinar o Modelo YOLOv9
Para treinar o modelo YOLOv9, utilizaremos a Interface de Linha de Comando (CLI). É importante familiarizar-se com o comando e seus parâmetros antes de iniciar o processo de treinamento.
Abaixo está um exemplo de um comando de treinamento que emprega a arquitetura GELAN-C:
!python train.py \
--batch 16 --epochs 20 --img 640 --device 0 \
--data {dataset.location}/data.yaml \
--weights {WEIGHTS_FOLDER}/gelan-c.pt \
--cfg models/detect/gelan-c.yaml
Vamos detalhar os argumentos da linha de comando que usaremos:
--batch: O tamanho do lote para o carregador de dados. Pode ser ajustado com base na memória GPU disponível.--epochs: Número de épocas para as quais queremos treinar.--img: Define o tamanho da imagem, padronizando o tamanho de entrada para o treinamento do modelo.--device: Atribui o treinamento para ser executado no dispositivo com ID 0, indicando tipicamente a primeira GPU.--data: Caminho para o arquivo YAML do conjunto de dados.--weights: Especifica os pesos iniciais para o treinamento.--cfg: Indica o arquivo de configuração a ser usado.
Seu modelo começará o treinamento. Uma vez finalizado, os resultados de cada sessão de treinamento serão automaticamente armazenados em {CODE_FOLDER}/runs/train/.
from prettytable import PrettyTable
import time
# Caminho do diretório que você deseja listar
directory_path = f'{CODE_FOLDER}/runs/train/exp'
# Criar uma tabela bonita
table = PrettyTable()
table.field_names = ["Nome do Arquivo", "Tamanho (KB)", "Data de Modificação"]
# Listar arquivos no diretório
for filename in os.listdir(directory_path):
filepath = os.path.join(directory_path, filename)
if os.path.isfile(filepath):
# Obter o tamanho do arquivo
size = os.path.getsize(filepath) / 1024 # Tamanho em KB
# Obter a data de modificação
mod_time = os.path.getmtime(filepath)
mod_time = time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(mod_time))
# Adicionar linha à tabela
table.add_row([filename, f"{size:.2f}", mod_time])
# Ordenar a tabela por nome do arquivo (opcional)
table.sortby = "Nome do Arquivo"
# Exibir a tabela
print(table)

YOLOv9 gera vários arquivos no diretório de saída. Para revisar esses arquivos, você pode facilmente navegar pelo diretório e modificar o nome do arquivo no comando abaixo conforme necessário para acessar arquivos específicos.
# Caminho para a imagem 'results.png'
results_image_path = f'{CODE_FOLDER}/runs/train/exp/results.png'
# Exibir a imagem com um tamanho específico
Image(filename=results_image_path, width=800)
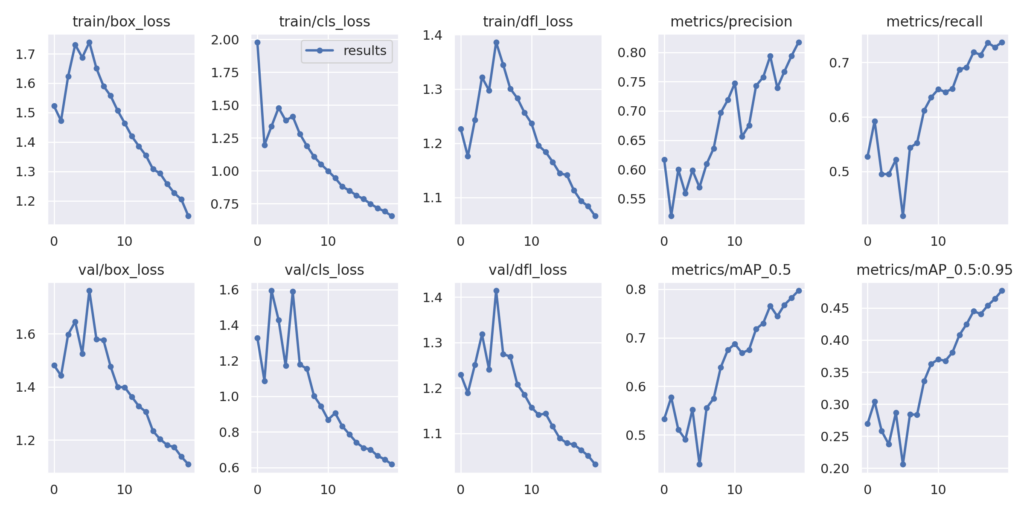
O mAP do modelo em IoU=0.5 é 0.79724, mostrando um forte desempenho de detecção. O mAP através do intervalo de IoU de 0.5 a 0.95 é 0.47729, indicando uma boa detecção de objetos em vários níveis.
Para validar o melhor modelo, use o seguinte comando.
!python val.py \
--img 640 --batch 32 --conf 0.001 --iou 0.7 --device 0 \
--data {dataset.location}/data.yaml \
--weights {CODE_FOLDER}/runs/train/exp/weights/best.pt

Salvando e Carregando Pesos
Durante ou após o treinamento no Google Colab, é comum encontrar o desafio de desconexões após um período de inatividade ou ao atingir o limite máximo de uso contínuo.
Para mitigar esse problema e garantir a continuidade do trabalho, como estamos usando o ambiente do Google Colab, é recomendado salvar os pesos do modelo treinado no Google Drive.
Como Salvar Pesos no Google Drive
Para salvar de forma segura os pesos do seu modelo no Google Drive, executaremos o seguinte código.
# from google.colab import drive
# import shutil
# Montar o Google Drive
drive.mount('/content/drive')
# Definir os caminhos de origem e destino
source_path = f'{CODE_FOLDER}/runs'
destination_path = '/content/drive/MyDrive/yolov9-rocket-detect'
# Verificar se o diretório de destino existe; se sim, removê-lo
if os.path.exists(destination_path):
shutil.rmtree(destination_path)
# Copiar o conteúdo do Google Drive para o ambiente Colab
shutil.copytree(source_path, destination_path)
print("Pesos de treinamento copiados para o Google Drive com sucesso.")
Para começar, você deve montar o Google Drive no ambiente Colab. Isso é feito usando a biblioteca google.colab e invocando drive.mount('/content/drive'), que solicita autenticação.
Em seguida, determine o caminho de origem e o caminho de destino no Google Drive. A função shutil.copytree(source_path, destination_path) é então usada para copiar toda a estrutura do diretório da origem para o destino.
Como Carregar Pesos do Google Drive
Para carregar os pesos salvos no seu modelo para inferência, siga estes passos:
from google.colab import drive
import shutil
# Montar o Google Drive
drive.mount('/content/drive')
# Definir os caminhos de origem e destino
source_path = '/content/drive/MyDrive/yolov9-rocket-detect'
destination_path = f'{CODE_FOLDER}/runs'
# Verificar se a origem contém os arquivos necessários
if os.path.exists(source_path):
shutil.copytree(source_path, destination_path, dirs_exist_ok=True)
print("Pesos de treinamento carregados do Google Drive com sucesso.")
else:
print("Diretório de pesos não encontrado no Google Drive.")
Monte o Google Drive no seu ambiente Colab usando drive.mount('/content/drive'), espelhando os passos tomados durante o processo de salvamento, mas com caminhos de origem e destino invertidos. Utilize shutil.copytree(source_path, destination_path, dirs_exist_ok=True) para transferir os pesos de volta ao seu espaço de trabalho.
Executar Inferência em filmagens da SpaceX
Com um modelo YOLOv9 treinado personalizado, agora é possível realizar inferência em filmagens de lançamentos de foguetes da SpaceX.
# Baixar a filmagem de teste
!wget -P {DATA_FOLDER} https://github.com/carlosfab/visao-computacional/raw/main/data/Falcon_9_USSF_124.mp4
# Executar inferência no modelo personalizado
!python detect.py \
--img 1280 --conf 0.1 --device 0 \
--weights {CODE_FOLDER}/runs/train/exp/weights/best.pt \
--source {DATA_FOLDER}/Falcon_9_USSF_124.mp4
Para iniciar a inferência, usamos o script detect.py, especificando os melhores pesos do nosso modelo localizados em {CODE_FOLDER}/runs/train/exp/weights/best.pt.
Para visualizar o vídeo processado no Colab, a biblioteca moviepy oferece um método conveniente.
from moviepy.editor import VideoFileClip
# Caminho para o vídeo processado
processed_video_path = f"{CODE_FOLDER}/runs/detect/exp/Falcon_9_USSF_124.mp4"
# Carregar o vídeo usando MoviePy
clip = VideoFileClip(processed_video_path)
# Exibir o vídeo no notebook com largura ajustada
clip.ipython_display(width=600)
Aqui, mostramos dois exemplos do nosso modelo detector de foguetes.
Nosso modelo reconhece impressionantemente as chamas do motor e o corpo do foguete. Ele detecta com precisão o foguete mesmo quando esse se torna um mero ponto na tela.
Takeaways
- Avanços do YOLOv9: A introdução do YOLOv9, apresentando Informação de Gradiente Programável e Rede de Agregação de Camadas Eficientes Generalizadas, representa um salto significativo na tecnologia de detecção de objetos.
- Treinamento em Dados Personalizados: O guia delineia uma abordagem abrangente para treinar o YOLOv9 em um conjunto de dados personalizado, enfatizando o processo desde a preparação do conjunto de dados até o treinamento do modelo, destacando especificamente o exemplo de rastreamento de lançamentos da SpaceX.
- Papel da Roboflow: A utilização da Roboflow para gerenciamento de conjuntos de dados sublinha os ganhos de eficiência na preparação de dados para treinamento, destacando sua importância na otimização do fluxo de trabalho de treinamento do modelo.
- Salvar e Carregar Pesos: Estratégias para salvar e carregar pesos do modelo no ambiente do Google Colab são discutidas, abordando possíveis interrupções nas sessões de treinamento.
- Insights de Inferência: Demonstrar inferência em filmagens da SpaceX com um modelo YOLOv9 treinado personalizado mostra a capacidade do modelo de detectar e rastrear elementos específicos de forma eficaz.
Neste artigo, tivemos um walkthrough detalhado para treinar o modelo YOLOv9 em um conjunto de dados personalizado. No processo, também realizamos um experimento de treinamento do mundo real para detecção e rastreamento de foguetes.
Se você decidir construir este projeto, ampliar suas capacidades ou treinar com algum outro dataset personalizado, por favor, compartilhe suas experiências comigo no LinkedIn.



















