O campo de Machine Learning oferece tantas opções de algoritmos que é muito difícil alguém conhecer todos e se manter atualizado a cada dia.
A escolha do algoritmo correto tem um enorme impacto na qualidade da solução, por isso é importante não apenas usar uma biblioteca pronta (sem ter a mínima ideia do que está por trás), mas ter pelo menos uma noção da teoria por trás dos modelos e algoritmos que você implementa.
Uma das primeiras técnicas que a(o) cientista de dados costuma ter contato no começo dos seus estudos é a Análise de Regressão, onde aprende a implementar um modelo de Regressão Linear Simples.
Entretanto, muita gente acaba apenas decorando como usar o scikit-learn e nunca mais vai atrás do conceito estatístico que está por trás da Regressão Linear.
Neste post, quero trazer uma conceituação um pouco mais aprofundada que o normal. O objetivo é apenas convidar você a despertar esse lado curioso pelas coisas que implementamos no dia-a-dia, afinal é isso que vai te destacar da média.

Para ir acompanhar o código deste artigo e conseguir replicar exatamente os resultados, acesse o notebook com todo o código no repositório do Github clicando no botão acima.
E se você está aprendendo e quer saber como se tornar um cientista de dados, leia este artigo do nosso blog 🙂
O que é Análise de Regressão
O objetivo da análise de regressão é explorar o relacionamento existente entre duas ou mais variáveis, visando obter informações sobre uma delas a partir dos valores conhecidas das outras.
Confuso? Simplificadamente, a frase aí de cima quis dizer que a análise de regressão busca entender o relacionamento entre variáveis, e esse relacionamento pode ser representado por uma equação matemática.
Vamos supor que você queira saber o preço de venda de uma casa sua e acredita que existe um relacionamento entre as variáveis que você está considerando (área construída, número de quartos e localização) com esse preço.
Seria possível fazer uma análise de regressão baseado nas outras casas da cidade, obter os pesos para os parâmetros em um modelo Regressão Linear e inferir qual o preço de venda que você deve colocar.
Relação não determinística
Um ponto importante, mas muito desconhecido, é que nos nossos problemas do cotidiano, muitas variáveis x e y aparentam estar relacionadas uma com a outra, porém de maneira não determinística.
Uma relação determínistica, por exemplo, é quando queremos saber a distância percorrida por um carro, mantendo velocidade constante ao longo de
segundos. Nesse exemplo, sabemos que a distância percorrida será
, pois as variáveis estão relacionadas deterministicamente.
Um exemplo de variáveis relacionadas de maneira não determinística é se quisessemos saber sendo
. Não é algo exato.
Para entender melhor essa relação determinística, veja os gráficos que vamos gerar em Python abaixo.
# importar pacotes necessários
import numpy as np
import matplotlib.pyplot as plt
# exemplo de plots determinísticos
np.random.seed(42)
det_x = np.arange(0,10,0.1)
det_y = 2 * det_x + 3
# exemplo de plots não determinísticos
non_det_x = np.arange(0, 10, 0.1)
non_det_y = 2 * non_det_x + np.random.normal(size=100)
# plotar determinísticos vs. não determinísticos
fig, axs = plt.subplots(1, 2, figsize=(10,4), constrained_layout=True)
axs[0].scatter(det_x, det_y, s=2)
axs[0].set_title("Determinístico")
axs[1].scatter(non_det_x, non_det_y, s=2)
axs[1].set_title("Não Determinístico")
plt.show()
Olhando rapidamente você já consegue ver uma diferença importante, que apesar dos dois gráficos estarem mostrando pontos que se espalham sobre uma “reta virtual”, um deles não segue um padrão exato, determinístico. Parece que há algum tipo de aleatoriedade envolvida.
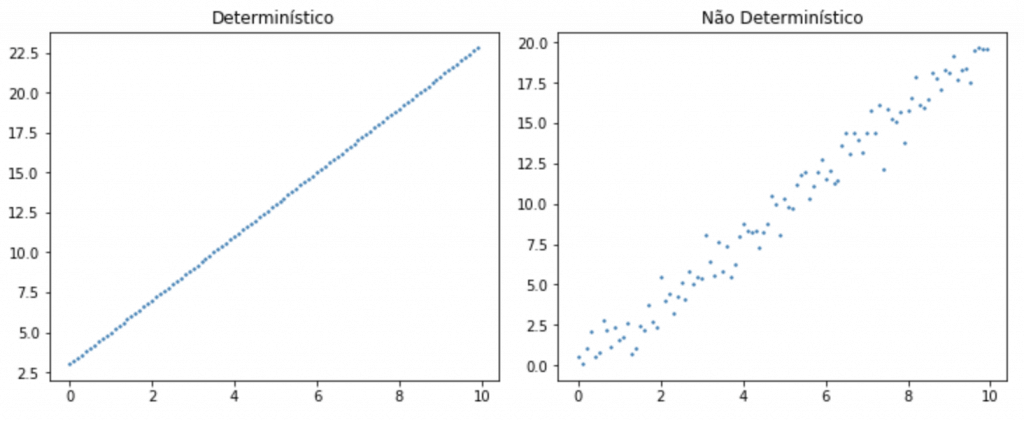
Ou seja, nos modelos de Regressão Linear que usamos em Machine Learning, não temos uma relação perfeita entre as variáveis, pois as observações do dataset não cabem exatamente em uma reta.
Isso significa que temos um modelo probabilístico, que captura a aleatoriedade que é inerente de qualquer processo do mundo real.
Pense: você consegue traçar uma reta pegando todos os pontos no gráfico da esquerda? E consegue traçar uma reta pegando todos os pontos no gráfico da direita?
Voltando para aquele exemplo de vender sua casa, basta imaginar que seu vizinho tem uma casa do mesmo tamanho, mesmo número de quartos, mesma localização, porém elas dificilmente teriam o mesmo preço exato.
É característica de uma pessoa realmente inteligente ser movida pela estatística.
George Bernard Shaw
O modelo de Regressão Linear Simples
Para representar a relação entre uma variável dependente () e uma variável independente (
), usamos o modelo
que determina uma linha reta com inclinação e intercepto
, com a variável aleatória (erro)
, considerada normalmente distribuída com
e
.
Para simplificar, vamos assumir a premissa de que o valor médio da variável para um dado valor de
é
. Dessa maneira, a equação da seguinte forma:
Quando a gente implementa um modelo de Regressão Linear com o scikit-learn, a gente quer encontrar os valores dos parâmetros e
que melhor representam o relacionamento entre as variáveis.
Antes de você chamar o fit() do seu modelo, e
são parâmetros totalmente desconhecidos.
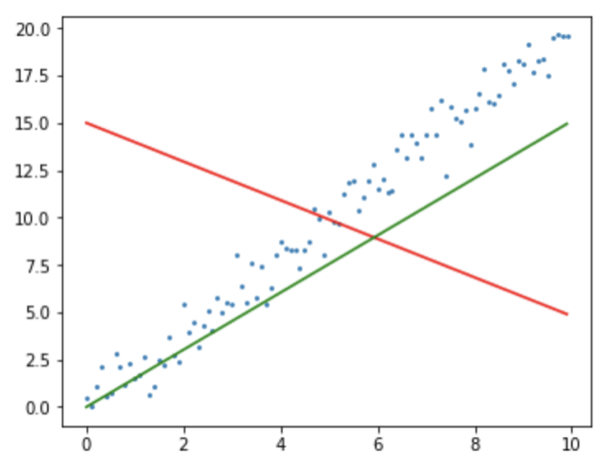
Olhando no gráfico acima, você é capaz de dizer qual reta seria mais plausível?
Parece óbvio que é a reta verde, porém não seria possível essa análise visual caso tivessemos centenas de variáveis. E também temos um problema, o computador não consegue “olhar” para ver qual reta fica melhor.
A questão é, como encontrar boas estimativas de e
para que nosso modelo forneça boas estimativas?
Se até agora tudo ainda está confuso para você, e você não consegue enxergar uma reta na equação acima, eu aconselho você revisar a equação fundamental da reta, que ficou esquecida na sua cabeça desde a época de ensino médio.
Estimando os parâmetros do modelo
De acordo com (DEVORE, 2014), um método usado para verificar se uma reta oferece um bom ajuste aos dados é o Método dos Mínimos Quadrados. Por esse método, o desvio vertical do ponto da reta
é:
A soma dos quadrados de tais desvios verticais dos pontos à reta é, portanto,
Uma reta é razoável se as distâncias verticais (desvios) dos pontos analisados em relação à reta são pequenas.
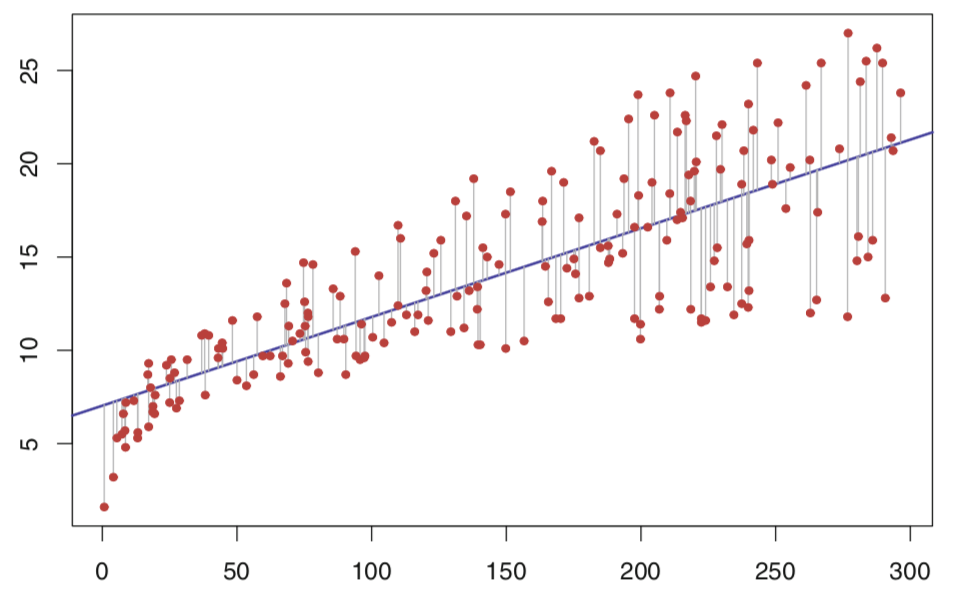
Ou seja, a reta que tem o melhor ajuste possível é aquela na qual se tem a menor soma possível de desvios quadrados. Os valores de minimização e
são encontrados quando se resolvem as derivadas parciais abaixo, igualando-as a
.
Essa etapa requer um conhecimento mais avançado de cálculo, e eu não vou entrar em mais detalhes. Tudo que você precisa saber é que a cada iteração do algoritmo a gente espera encontrar a menor soma possível de desvios quadrados.
Implementando Regressão Linear com Python
Para ver na prática uma aplicação simples e direta da Regressão Linear, vamos usar as variáveis que plotamos lá em cima, non_det_x e non_det_y.
Lembrando que aqui eu estou ignorando completamente as etapas de split entre datasets de treino e teste ou qualquer outro tipo de etapa. O objetivo é apenas encontrar uma reta com um fit ideal aos nossos pontos.
# importar os pacotes necessários from sklearn.datasets import load_diabetes from sklearn.linear_model import LinearRegression from sklearn.metrics import mean_squared_error # criar modelo linear e otimizar lm_model = LinearRegression() lm_model.fit(non_det_x.reshape(-1,1), non_det_y) # extrair coeficientes slope = lm_model.coef_ intercept = lm_model.intercept_
Como temos apenas uma variável, nosso x é um vetor (1 dimensão).
Após minimizar a função custo e encontrar o melhor fit os parâmetros da equação da reta que buscamos estarão armazenados como atributos de lm_model, onde e
.
Imprimindo esses parâmetros a gente vê quais valores numéricos melhor representam nossa reta para o modelo de Regressão Linear:
# imprimir os valores encontrados para os parâmetros
print("b0: \t{}".format(intercept))
print("b1: \t{}".format(slope[0]))
# Será impresso os seguintes valores:
# b0: -0.17281285407737457
# b1: 2.0139325932693497
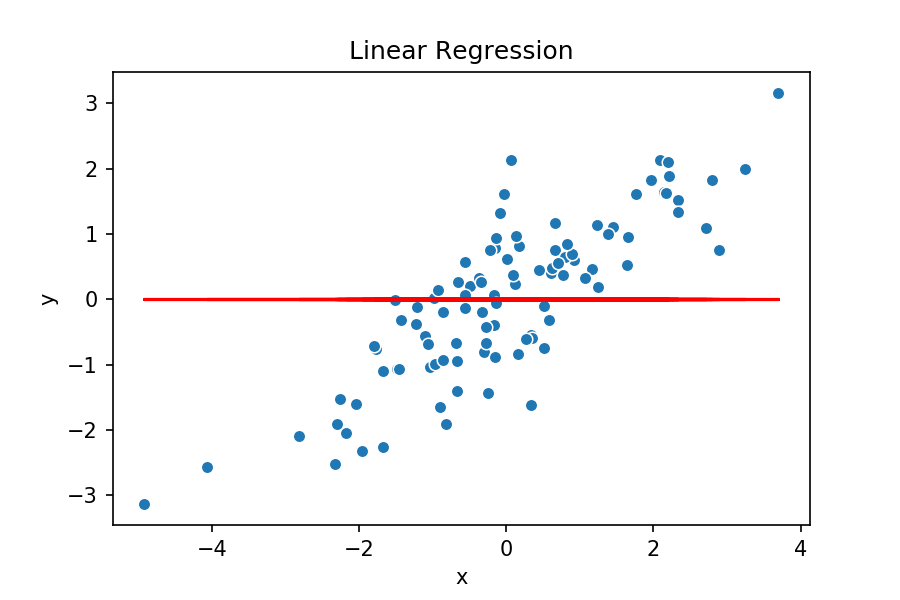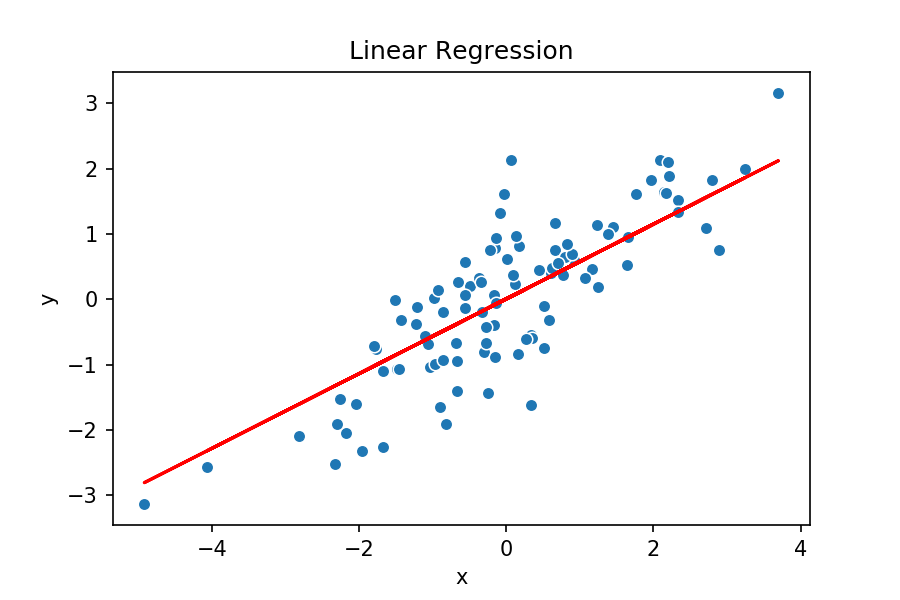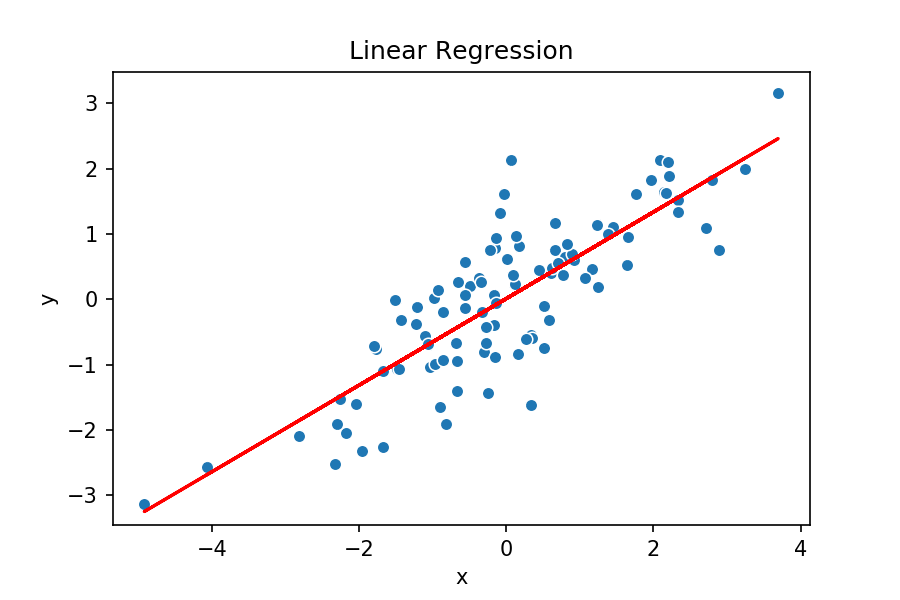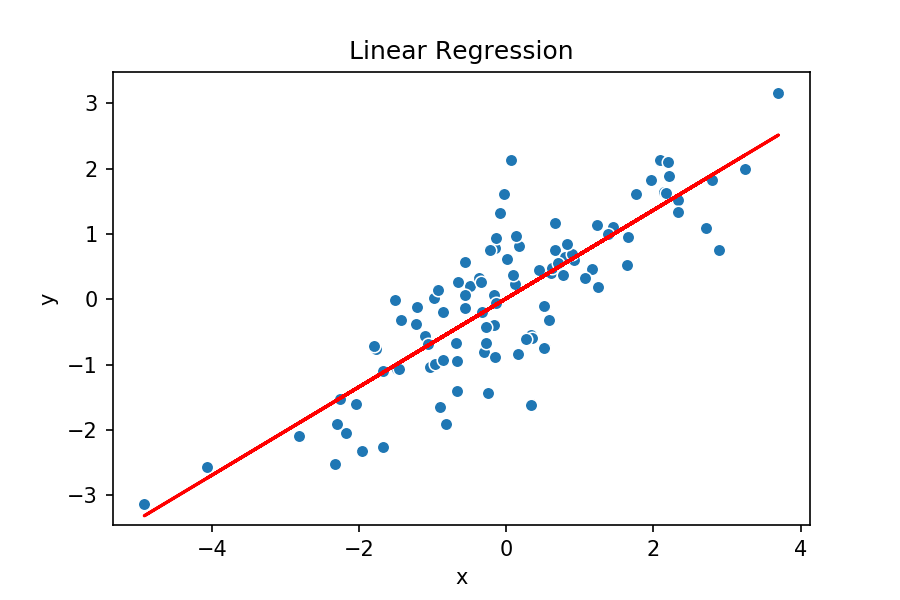
E agora vamos plotar a reta, com os valores de parâmetros obtidos, sobrepondo ela aos pontos e ver como essa solução parece plausível visualmente.
# plotar pontos e retas com parâmetros otimizados plt.scatter(non_det_x, non_det_y, s=3) plt.plot(non_det_x, (non_det_x * slope + intercept), color='r') plt.show()
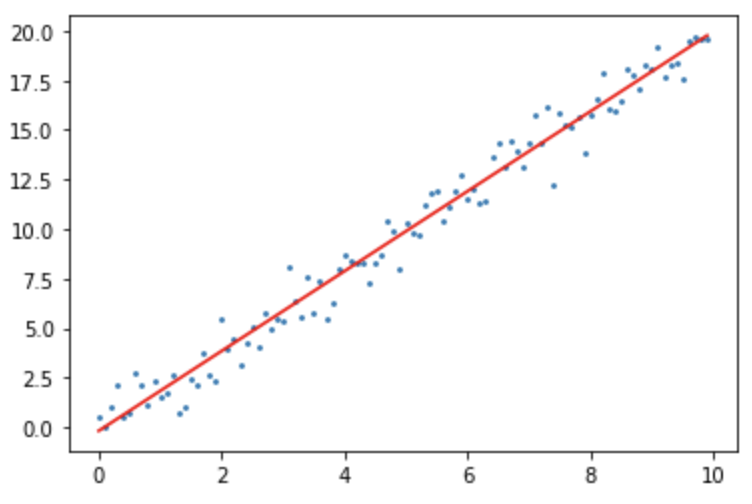
E é isso! Essa solução parece, de fato, atender ao nosso problema.
Agora você sabe não apenas implementar uma Regressão Linear, que é feito com pouquíssimas linhas de código, mas consegue entender a lógica por trás do código 🙂
Resumo
Eu aposto que agora você conseguiu entender o funcionamento básico de um modelo de Regressão Linear, vendo tanto visualmente (como a reta vai “melhorando” a cada iteração) quanto absorvendo conceitos (com a matemática que foi exposta).
Este artigo foi muito mais teórico que aplicação de técnicas de Data Science ou Machine Learning, e tudo isso propositalmente. Ao limitar para uma variável, conseguimos realizar os plots em 2 dimensões e acompanhar mais facilmente tudo.
Obviamente, todo essa teoria pode ser extrapolada para problemas mais complexos envolvendo múltiplas variáveis. A lógica é a mesma!
Lembre-se que o que vai te diferenciar das outras pessoas, da média, é o conceito que você sabe a mais e a criatividade para pensar em soluções fora-da-caixa.
Para receber sempre conteúdos novos e exclusivos, inscreva-se abaixo com seu e-mail e receba todo o material de altíssima qualidade no conforto da sua inbox! Aproveite também para me seguir no Instagram, pois estou sempre gerando conteúdos de valor por lá 🙂




![Data Science: Investigando o naufrágio do Titanic [Pt. 2]](https://sigmoidal.ai/wp-content/uploads/2019/08/Data-Science-Investigando-o-naufragio-do-Titanic-75x75.png)













Como faz pra traçar uma reta na distancia do ponto ate a reta? n esta no codigo
A própria função do Scikit-learn já faz essa conta para você. Mas basicamente se trata de calcular a distância euclidiana 🙂
Estou iniciando os estudos em ml e o artigo foi muito útil. Parabéns !!!
Excelente explicação, muito didática. Estou tendo o primeiro contato com Machine Learning.
Um exercício meu pede que o valor de x seja determinado pelo usuário via comando input. O que eu tô tentando não está funcionando. Alguém consegue me dar uma luz?