Você sabia que o Metallica escolhe seu setlist de acordo com as estatísticas disponibilizadas pelo Spotify? Aqui, não só você verá isso, mas também como funcionam o sistema de recomendações e o recurso retrospectiva dessa gigante do streaming de música.
Comparando os hábitos e a cultura da população média mundial no tempo, percebemos como a tecnologia produziu mudanças na sociedade. As redes sociais e os aplicativos como o Tinder, por exemplo, mudaram muito a forma como conhecemos e interagimos com as pessoas hoje em dia: se por um lado facilitou, por outro tornou as relações mais superficiais (liquidez das relações, já dizia Bauman).
“Você tem um artista como o Metallica, que muda o setlist deles de cidade para cidade apenas olhando os dados do Spotify para ver quais as músicas mais populares da cidade.“
Daniel Ek
Com a indústria da música, o efeito não foi tão diferente assim. Parte considerável da receita das bandas, o disco de vinil e o CD passaram a ser consumidos apenas por fãs das bandas.
No entanto, na música um componente ainda permanece, em essência, o mesmo: os shows. As apresentações musicais continuam sendo presenciais (salvo as lives, as quais marcaram o período pandêmico) e tendo uma enorme importância para a receita das bandas e para seus fãs.
Em função dessa relevância, os grupos musicais planejam a estrutura do palco (iluminação, aparelhos de som, cenário) até o famoso setlist. Certamente esse, a lista de músicas, é o aspecto principal de um show, aquilo sobre o qual o fã que comprou o ingresso quer saber em primeiro lugar.
Setlist Baseado em Dados
Ora, assim como as grandes empresas fazem uso dos dados para orientar suas tomadas de decisões (leia o fantástico livro “Data Science para Negócios”, de Foster Provost e Tom Fawcett), na música não poderia ser diferente.
Como exemplo, cito a famosa banda norte-americana de heavy metal Metallica. Segundo Daniel Ek, CEO da Spotify, em uma teleconferência de sua empresa em 2018, o Metallica utiliza os dados do Spotify para criar uma playlist com as músicas mais executadas pelo público da cidade onde tocarão. Ou seja, se forem tocar na cidade de São Paulo, olharão quais músicas são as mais executadas no Spotify pelos paulistanos – obviamente, há músicas que são praticamente fixas, tal como “Creep” é para Radiohead e “Take on Me” é para A-ha.
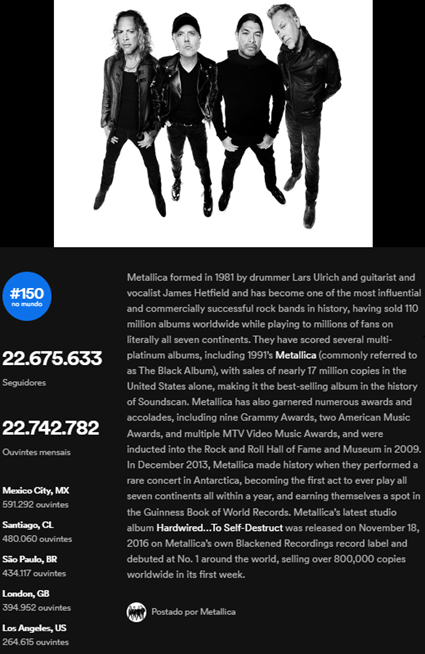
O serviço de streaming de música, podcast e vídeo sueco, o Spotify, fornece esses dados (analytics, vide imagem abaixo), tal como o Instagram (principalmente a comercial e a de criador de conteúdo) e o YouTube fornecem para seus usuários. Os dados disponibilizados por essa plataforma incluem, por exemplo, o número de execuções de músicas e álbuns no tempo e no espaço (geograficamente).
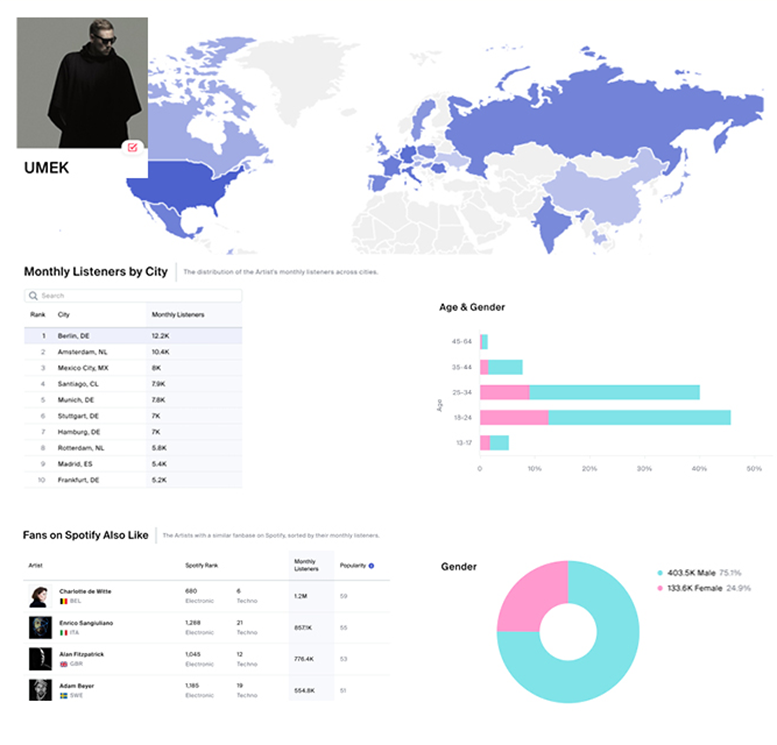
Bem, é claro que não só o Metallica utiliza esses dados para agradar seu público (eles não inventaram a roda), assim como esses dados também não apenas são utilizados para esse fim (por exemplo, podem ser utilizados para medir o grau de satisfação das músicas, servindo como métrica para futuros álbuns).
Pensando no seu dia a dia, você poderia utilizar os dados do seu Instagram para saber quais os melhores horários para publicar uma foto no feed, bem como para saber quais as características do seu público (idade, gênero etc.) e agir com a probabilidade a seu favor. São inúmeros os exemplos do uso de tecnologia e de Data Science para orientar uma tomada de decisão (a criatividade e a fonte de dados que limitarão seu alcance), gerando efeitos mais benéficos do que se usasse apenas a intuição humana.
Voltando ao serviço de streaming de música, há muito mais conteúdo a ser abordado quando se trata do uso de dados. Em primeiro lugar, você entenderá quais as estratégias utilizadas para as recomendações de músicas; em seguida, a retrospectiva, feita anualmente para cada usuário.
Recomendações do Spotify
Administrando 80 milhões de faixas musicais, 4,7 milhões de podcasts, 456 milhões de usuários – sendo 195 assinantes – em 183 mercados (países), a empresa sediada na Suécia oferece o serviço de streaming de música mais popular do mundo. Engana-se quem acredita que ela compete sozinha: ela disputa o enorme mercado da música (streaming) com gigantes, como Apple (Apple Music), Tidal, SoundCloud e Deezer.
Uma empresa assim tem que ter um diferencial para atrair tanto público. E talvez o seu principal diferencial seja o recurso de recomendação, extremamente sofisticado e eficiente. Houve muito investimento do Spotify em Big Data e Análise de Dados para a melhoria da experiência do usuário, pois a receita principal vem dos assinantes, embora os anunciantes também participem da produção de caixa para empresa.
“É a maneira mais sábia de aprender mais sobre nosso público e atendê-los melhor. Esses dados, uso e comportamento nos fornecem a riqueza que nos ajuda literalmente a construir produtos e seguir o comportamento para servir de uma forma que ofereça valor e trabalhe a serviço das pessoas, seu tempo, seus comportamentos e seus humores”, explicou Khartoon Weiss, ex-chefe de um setor do Spotify, em uma entrevista em 2019.
Para que suas recomendações sejam as mais fidedignas possíveis, o Spotify utiliza três técnicas de Machine Learning: Collaborative Filtering, Natural Language Processing (NLP) e Convolutional Neural Network (CNN). A partir dos dados históricos de músicas dos usuários e utilizando essas técnicas de Inteligência Artificial, a empresa consegue entender o gosto de seus usuários e recomendar músicas e playlists.
A Filtragem Colaborativa consiste em relacionar pessoas com gostos musicais similares e sugerir a essas as músicas que faltam na lista de um e sobram na do outro. Por exemplo, digamos que João goste da música A, assim como Sérgio, Samara e Paulo. Porém, Paulo é aquele que possui mais músicas em comum com João, logo se conclui (raciocínio lógico) que ambos possuam gostos musicais similares. Em função dessa característica deles –afinal, as pessoas não saem cada uma de um planeta, totalmente distintas umas das outras –, uma música que João gosta e que Paulo ainda não ouviu será sugerida a esse, e vice-versa.
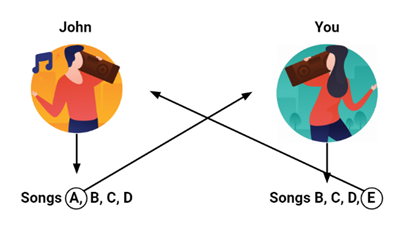
Na verdade, há dois tipos de Filtragem Colaborativa: Explicit Feedback Approach e Implicit Feedback Approach. A primeira é utilizada, por exemplo, pela Netflix, pois há como fazer avaliações, sugerindo conteúdo em função disso. Já a segunda, por não poder se pautar na avaliação (informação mais explícita, objetiva), tem que encontrar outra forma na qual se basear. Nesse sentido, o algoritmo localiza playlists que contenham as músicas que fazem parte do histórico musical do usuário (músicas/playlists executas, playlists criadas). Encontradas essas listas de músicas, as músicas que o usuário já conhece e escuta são eliminadas para se criar uma nova playlist.
Quanto ao Processamento de Linguagem Natural (sigla em inglês NLP), o algoritmo acessa páginas web (blogs, jornais, artigos) para extrair dados de texto sobre músicas e artistas musicais. Com esses dados, as músicas são agrupadas com base nas palavras utilizadas para descrevê-las (por exemplo, rock alternativo, jazz suave, rap melódico). A finalidade disso é identificar os artistas afins e, então, criar listas de reprodução personalizadas.
Por fim, a Rede Neural Convolucional (sigla em inglês CNN) analisa certos parâmetros das músicas, como BPM, volume e tom, para classificá-las. Ou seja, uma música é classificada por suas próprias características, produzindo um catálogo mais objetivo. Em função dessa objetividade, ela é importante para suavizar o viés humano da NLP, afinal são pessoas que escrevem em blogs, artigos e afins. Munidos dessas classificações, as músicas são recomendadas levando em consideração os gostos musicais dos seus usuários.
“Sua mixtape semanal cheia de novas descobertas e pérolas musicais escolhidas só para você. Atualize toda segunda.”
Quem usa o Spotify, deve conhecer o recurso Descobertas da Semana. Bem, uma lista composta por trinta músicas é recomendada aos usuários utilizando as técnicas acima expostas.
Spotify Wrapped: a sua retrospectiva
Panetone, árvore de Natal, música do final da Globo e… claro, a retrospectiva do Spotify compartilhada nas redes sociais.
Desde 2016, a empresa sueca permite que seus usuários tenham acesso aos seus dados musicais, como artistas e músicas mais ouvidos no ano, quantas músicas e quantos minutos ouviu, quantos gêneros musicais ouviu e os mais ouvidos, entre outros dados. Além disso, seus dados são comparados com os dos outros usuários. Por exemplo, é informada a estatística do tempo que você ouve música na plataforma em comparação com os usuários do país em que você reside.
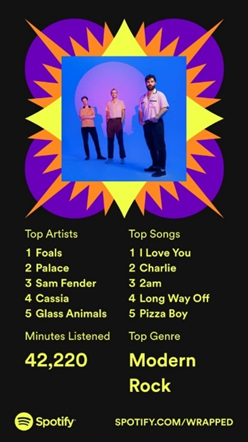
A verdade é que esse serviço é muito bacana: primeiro porque todo mundo gosta de algo personalizado, criado exclusivamente para si; segundo, a experiência traz uma reflexão, pois, enquanto os dados lhe são apresentados, músicas que você ouviu muitas vezes no ano são executadas. Confesso que bate uma sensação de saudade/nostalgia todo ano que minha retrospectiva é compartilhada para mim – a música, assim como o cheiro, são um dos melhores meios para criar e recuperar memórias.
E se quiser ter acesso aos seus dados musicais, ou você espera que o Spotify crie sua lista (final do ano – entre final de novembro e início de dezembro) ou você utiliza o aplicativo da empresa e clica no link do Spotify Wrapped.
Para saber mais desse recurso, acesse este link.
Quanto Ganha um cientista de dados no Spotify
Que profissional de dados não gostaria de trabalhar em uma gigante e que lida com uma das artes mais consumidas, não é verdade?
Segundo a página web Glassdoor, a média global do salário de um cientista de dados nessa empresa é de $ 174,318 mil por ano, o qual é composto por um valor base, de $ 129,809 mil por ano, e um adicional.
Clustering Usando Dados do Spotify
Para finalizar, quem tiver interesse em mais um conteúdo relativo a essa plataforma, sugiro acessar a aula 17 (“Clustering Usando Dados do Spotify”) da Escola de Data Science, ministrada pelo Rafael Duarte.
Só para se situar, conforme definição extraída do Medium, “Clustering (ou agrupamento) consiste na implementação de técnicas computacionais para separar um conjunto de dados em diferentes grupos com base em suas semelhanças”.




















Ótimo artigo Professor, já começo a perceber esse novo mundo que estou triando, e o seu conteúdo é muito bom..
Eu que agradeço a sua visita aqui no blog. Um forte abraço!