Antes de uma rede neural classificar uma imagem ou um modelo de linguagem prever a próxima palavra, existe uma operação que se repete bilhões de vezes por trás de tudo: multiplicar um vetor de pesos por um vetor de dados e somar um número. Entender essa operação com precisão é o que separa quem decora bibliotecas de quem entende o que acontece, e ela aparece em sua forma mais pura no primeiro modelo de Machine Learning que todo estudante encontra: a regressão linear.
Este é o primeiro artigo da série Matemática para Machine Learning. A proposta da série é reconstruir, do zero e com rigor, a base matemática sobre a qual todo o aprendizado de máquina moderno se apoia. Começamos pela regressão linear porque é nesse modelo que aparecem, em sua forma mais limpa, os dois objetos que reencontraremos em todos os artigos seguintes: o vetor de parâmetros e o produto escalar. A notação segue a convenção consolidada na literatura de Machine Learning, e a manteremos do início ao fim da série.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O que é aprendizado supervisionado
Aprendizado supervisionado é o cenário em que dispomos de um conjunto de exemplos rotulados. Cada exemplo é um par  , em que
, em que  é o vetor de features (as características que descrevem o exemplo) e
é o vetor de features (as características que descrevem o exemplo) e  é o alvo que queremos prever. O objetivo é encontrar uma função
é o alvo que queremos prever. O objetivo é encontrar uma função  que, a partir de um
que, a partir de um  qualquer, produza uma previsão
qualquer, produza uma previsão  próxima do valor real.
próxima do valor real.
No caso da regressão, o alvo é um número contínuo: o preço de um imóvel, a temperatura de amanhã, o consumo de energia de uma residência. A regressão linear é a hipótese mais simples para , e é o ponto de partida obrigatório porque toda a maquinaria de treinamento que vem depois (função de custo, gradient descent, retropropagação) é mais fácil de entender quando o modelo é transparente.
Por que representar dados como vetores
Considere um conjunto de imóveis descritos por três features: área em metros quadrados, número de quartos e idade em anos. Cada imóvel é um vetor em  , e o conjunto inteiro é uma matriz
, e o conjunto inteiro é uma matriz  de dimensão
de dimensão  , com
, com  exemplos nas linhas e
exemplos nas linhas e  features nas colunas.
features nas colunas.
import numpy as np
# 5 imóveis, 3 features: [área(m²), quartos, idade(anos)]
X = np.array([
[ 80, 2, 5],
[120, 3, 10],
[ 60, 1, 2],
[200, 4, 15],
[ 95, 2, 8],
], dtype=float)
print("X tem dimensão", X.shape, "->", X.shape[0], "exemplos,", X.shape[1], "features")
print("Primeiro exemplo, x^(1) =", X[0])
X tem dimensão (5, 3) -> 5 exemplos, 3 features Primeiro exemplo, x^(1) = [80. 2. 5.]
Essa escolha de representação não é uma conveniência estética. Ela permite expressar operações sobre o conjunto inteiro como uma única operação de álgebra linear, e essa forma vetorizada é o que torna o treinamento computacionalmente viável.
Produto escalar: a operação central
Dados dois vetores  , o produto escalar é definido como
, o produto escalar é definido como
![\[\mathbf{u} \cdot \mathbf{v} = \sum_{j=1}^{d} u_j v_j = u_1 v_1 + u_2 v_2 + \cdots + u_d v_d.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-b69a8b0d96abebd88a260bab055ff6ae_l3.png "Rendered by QuickLaTeX.com")
O resultado é um único número, um escalar. Essa soma de produtos é a unidade básica de quase toda a computação em Machine Learning, e vale a pena medir o custo de calculá-la de duas formas: com laços explícitos em Python e com a operação vetorizada @ do NumPy.
def soma_ponderada_loop(X, w):
"""Soma ponderada das features com laços em Python puro."""
N, d = X.shape
saida = np.zeros(N)
for i in range(N):
for j in range(d):
saida[i] += X[i, j] * w[j]
return saida
def soma_ponderada_numpy(X, w):
"""Mesma operação, com o produto matricial do NumPy."""
return X @ w
As duas funções produzem o mesmo resultado numérico. A diferença aparece quando aumentamos a escala para  exemplos e
exemplos e  features:
features:
N, d = 100_000, 10 X_grande = np.random.randn(N, d) w_grande = np.random.randn(d) # ... medição de tempo com time.perf_counter() ...
Loop : 428.5 ms NumPy : 2.00 ms NumPy é cerca de 214x mais rápido
A operação é a mesma; o que muda é que o NumPy delega a soma de produtos a rotinas de álgebra linear compiladas e otimizadas. Uma diferença de duas ordens de grandeza é exatamente a fronteira entre um treinamento que termina em segundos e um que não termina nunca. É por esse motivo que toda a formulação de Machine Learning é escrita em linguagem vetorial, e é também parte do porquê de Python ter se tornado a linguagem dominante em ciência de dados.
O modelo de regressão linear
Com features, o modelo de regressão linear prevê o alvo combinando linearmente as features e somando um termo independente:
![\[f_{\mathbf{w},b}(\mathbf{x}) = w_1 x_1 + w_2 x_2 + \cdots + w_d x_d + b.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-0d1c32503cf3ecf1328da80e1c165610_l3.png "Rendered by QuickLaTeX.com")
A soma dos termos  é precisamente um produto escalar, o que permite escrever o modelo na forma compacta que usaremos no restante da série:
é precisamente um produto escalar, o que permite escrever o modelo na forma compacta que usaremos no restante da série:
![\[f_{\mathbf{w},b}(\mathbf{x}) = \mathbf{w} \cdot \mathbf{x} + b.\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-d5606e18f95d44c42c9ae8f382728d6a_l3.png "Rendered by QuickLaTeX.com")
O vetor  reúne os pesos, um por feature, e o escalar
reúne os pesos, um por feature, e o escalar  é o termo de viés (bias). Cada peso quantifica quanto a respectiva feature contribui para a previsão; o viés é o valor que o modelo prevê quando todas as features são nulas. A implementação para um único exemplo é uma tradução direta da fórmula:
é o termo de viés (bias). Cada peso quantifica quanto a respectiva feature contribui para a previsão; o viés é o valor que o modelo prevê quando todas as features são nulas. A implementação para um único exemplo é uma tradução direta da fórmula:
def prever_um(x, w, b):
"""Predição do modelo para um único exemplo x."""
return np.dot(w, x) + b
# Pesos e viés escolhidos (preços em milhares de R![) w = np.array([3.0, 15.0, -1.5]) b = 50.0 x1 = X[0] print("w · x^(1) =", np.dot(w, x1)) print("f(x^(1)) = w.x+b =", prever_um(x1, w, b))</pre> <pre class="EnlighterJSRAW" data-enlighter-language="generic">w · x^(1) = 262.5 f(x^(1)) = w.x+b = 312.5</pre> <!-- wp:paragraph --> O produto escalar](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-890961d61b4672af7a3e3ae18c7097ae_l3.png "Rendered by QuickLaTeX.com") \mathbf{w} \cdot \mathbf{x}^{(1)} = 262{,}5
\mathbf{w} \cdot \mathbf{x}^{(1)} = 262{,}5 b = 50
b = 50 312{,}5
312{,}5 15
15 ![associado ao número de quartos significa que, mantidas as demais features fixas, cada quarto adicional acrescenta quinze mil reais à previsão; o coeficiente negativo da idade indica que imóveis mais antigos são previstos com preço menor. <!-- /wp:paragraph --> <!-- wp:paragraph --> A mesma fórmula, aplicada a todos os exemplos de uma vez, é uma única multiplicação de matriz por vetor: <!-- /wp:paragraph --> <!-- wp:paragraph --> <span class="ql-right-eqno"> </span><span class="ql-left-eqno"> </span><img src="https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-2d8c2ee42f249cdcef23be906c9fca8c_l3.png" height="17" width="99" class="ql-img-displayed-equation quicklatex-auto-format" alt="\[\hat{\mathbf{y}} = \mathbf{X}\mathbf{w} + b.\]" title="Rendered by QuickLaTeX.com"/> <!-- /wp:paragraph --> <pre class="EnlighterJSRAW" data-enlighter-language="python">def prever(X, w, b): """Predição vetorizada para todos os exemplos de X.""" return X @ w + b y_hat = prever(X, w, b)</pre> <pre class="EnlighterJSRAW" data-enlighter-language="generic">Imóvel 1: área=80m², quartos=2, idade=5a -> R](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-c928ff071d809ac3678f1f4e8edb7e60_l3.png "Rendered by QuickLaTeX.com")
312 mil
Imóvel 2: área=120m², quartos=3, idade=10a -> R 242 mil
Imóvel 4: área=200m², quartos=4, idade=15a -> R
242 mil
Imóvel 4: área=200m², quartos=4, idade=15a -> R 353 mil
353 mil
A função prever é idêntica em estrutura à soma_ponderada_numpy do início do artigo. A operação de álgebra linear é universal: o que num contexto era um teste de desempenho, em outro é o próprio mecanismo de predição do modelo.
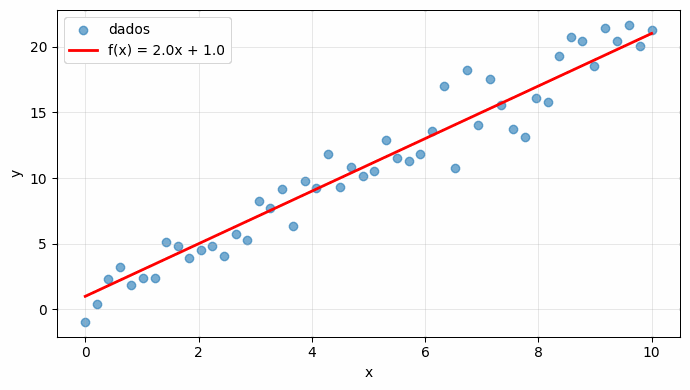
O caso de uma feature: visualizando a reta
Com uma única feature, o modelo se reduz a  , a equação de uma reta em que
, a equação de uma reta em que  é a inclinação e é o intercepto. Gerando dados sintéticos em torno de
é a inclinação e é o intercepto. Gerando dados sintéticos em torno de  com ruído e sobrepondo a reta do modelo, obtemos a figura de abertura deste artigo: uma nuvem de pontos e uma reta que tenta atravessá-la da melhor forma possível.
com ruído e sobrepondo a reta do modelo, obtemos a figura de abertura deste artigo: uma nuvem de pontos e uma reta que tenta atravessá-la da melhor forma possível.
Há um detalhe decisivo. Os pesos usados em todos os exemplos acima foram escolhidos, não aprendidos. A reta da figura passa razoavelmente perto dos pontos porque conhecíamos a regra que gerou os dados, mas em um problema real não temos esse luxo. A pergunta que organiza todo o restante da série é precisamente esta: dado um conjunto de dados, como encontrar os valores de e que fazem a previsão  ficar o mais próxima possível do alvo
ficar o mais próxima possível do alvo  ?
?
Responder a essa pergunta exige dois ingredientes que serão o tema do próximo artigo: uma função de custo, que mede numericamente o quão errado está o modelo, e o gradient descent, o algoritmo que ajusta os parâmetros para reduzir esse custo. A partir do momento em que o modelo deixa de receber pesos prontos e passa a encontrá-los sozinho, ele deixa de ser uma fórmula e passa a ser, de fato, um modelo que aprende.
O vetor de pesos e o produto escalar que isolamos aqui não ficam restritos à regressão linear. São exatamente os mesmos blocos que, empilhados em sucessivas camadas com uma não linearidade entre elas, dão origem às redes neurais multicamadas. Toda a série caminha nessa direção, e tudo começa pela operação simples que você acabou de implementar.
Takeaways
- Dados em Machine Learning são vetores, e conjuntos de dados são matrizes. Essa representação permite expressar predições e treinamento como operações de álgebra linear, e a forma vetorizada chega a ser duas ordens de grandeza mais rápida que laços explícitos.
- O produto escalar é a operação fundamental. A soma
 reaparece em toda a série, da predição de uma regressão à propagação de uma rede neural.
reaparece em toda a série, da predição de uma regressão à propagação de uma rede neural. - A regressão linear é
 , com pesos interpretáveis e um termo de viés, válida igualmente para uma ou milhares de features.
, com pesos interpretáveis e um termo de viés, válida igualmente para uma ou milhares de features. - Escolher pesos não é treinar. O próximo passo é definir uma função de custo e usar gradient descent para encontrar os parâmetros que melhor ajustam o modelo aos dados.



















