Estima-se que um cientista de dados gasta 80% do tempo de um projeto preparando os dados, e muito menos tempo treinando modelo. Por isso, qualquer boa introdução ao pandas vai direto ao ponto: a maior parte do trabalho está em entender, limpar e organizar a base, e nenhuma biblioteca do ecossistema Python acelera essa etapa mais do que o pandas.
Neste guia prático, você vai sair do zero ao essencial com código rodando: carregar um arquivo csv real (cotações da ação do Banco do Brasil), inspecionar o DataFrame, trabalhar com datas, calcular estatísticas descritivas, criar tabelas do zero e tratar valores ausentes.
É o repertório que se usa nos primeiros minutos de qualquer projeto sério, e o ponto de partida natural para quem quer trabalhar com Data Science na prática.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Introdução ao Pandas: O Que É e Por Que Ele Existe
Pandas é a biblioteca padrão para manipulação de dados tabulares em Python. Se o seu dado cabe em uma planilha, com linhas, colunas e valores numéricos e categóricos misturados, então pandas é a ferramenta. Ele foi criado em 2008 por Wes McKinney quando ele trabalhava em um fundo de investimento e precisava de algo melhor que Excel para análise financeira. Hoje, a documentação oficial do pandas é uma das mais completas do ecossistema Python.
A comparação com o Excel é inevitável e útil. Quando você abre um csv no Excel, ele tropeça em coisas básicas: confunde vírgula com ponto e vírgula, inventa formatação para datas, trava em arquivos com mais de 1 milhão de linhas. O pandas resolve tudo isso e ainda permite encadear operações em código, o que torna a análise reproduzível. Ou seja, você não vai esquecer qual fórmula usou na célula K47 daqui a três meses, porque a “fórmula” está num script versionado.
Pandas se encaixa no início do fluxo de Data Science. Depois de coletar os dados (de um banco SQL, uma API, um arquivo) e antes de qualquer modelagem séria, é com pandas que você ganha consciência situacional sobre o que tem em mãos. Modelos vêm depois. Antes deles, vem entender o dado.
Carregando o Seu Primeiro Dataset
Por convenção, importa-se o pandas com o apelido pd. A função para ler um arquivo csv é pd.read_csv(), e ela aceita tanto um caminho local quanto uma URL, o que é prático quando o dataset está hospedado num GitHub público.
import pandas as pd url = "https://raw.githubusercontent.com/carlosfab/dsnp2/master/datasets/BBAS3.SA.csv" df = pd.read_csv(url) df.head()
A variável df agora guarda um DataFrame com as cotações diárias da ação do Banco do Brasil (BBAS3) de maio de 2019 a maio de 2020. O df.head() mostra as cinco primeiras linhas, com colunas Date, Open, High, Low, Close, Adj Close e Volume. Esse padrão (data + preços OHLC + volume) é o que praticamente toda corretora exporta.
Pandas reconhece muito mais do que csv. Há funções equivalentes para JSON (pd.read_json), Parquet (pd.read_parquet), Excel (pd.read_excel), HTML (pd.read_html), bancos SQL (pd.read_sql) e por aí vai. A lógica é sempre a mesma: uma função pd.read_*() devolvendo um DataFrame.
Inspecionando o DataFrame
Antes de qualquer cálculo, você precisa saber o que tem na sua mão. Quantas linhas, quantas colunas, que tipos, se tem valor faltando. Pandas oferece quatro comandos que você vai usar em todo projeto:
df.shape # (linhas, colunas) df.columns # nomes das colunas df.dtypes # tipo de cada coluna df.info() # resumo completo
No nosso caso, df.shape retorna (248, 7), ou seja, 248 dias de pregão e 7 colunas. df.columns lista os nomes. E df.info() é o método mais informativo dos quatro:
RangeIndex: 248 entries, 0 to 247 Data columns (total 7 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Date 248 non-null object 1 Open 247 non-null float64 2 High 247 non-null float64 3 Low 247 non-null float64 4 Close 247 non-null float64 5 Adj Close 247 non-null float64 6 Volume 247 non-null float64
Repare na coluna Non-Null Count. A coluna Date tem 248 valores não nulos, mas todas as colunas numéricas têm 247. Ou seja, uma linha do dataset tem dados faltando e o pandas já te avisou disso com um único comando. Esse tipo de pista aparece logo na primeira inspeção e evita surpresas mais tarde, quando você for calcular médias, treinar modelos ou plotar gráficos.
Outro detalhe: a coluna Date apareceu como object, não como data. Volto nesse ponto daqui a pouco.
Os métodos df.head() e df.tail() mostram as primeiras e últimas linhas. Por padrão, retornam cinco; passe um número como argumento se quiser mais ou menos:
df.head(3) # 3 primeiras linhas df.tail(10) # 10 ultimas linhas
Para a maioria dos casos, alternar entre head() e tail() é suficiente para ter ideia do que muda do início para o fim do dataset. Em séries temporais, por exemplo, comparar head() e tail() revela imediatamente o período coberto e se houve mudança grande de magnitude no caminho.
DataFrame vs Series: A Diferença Importa
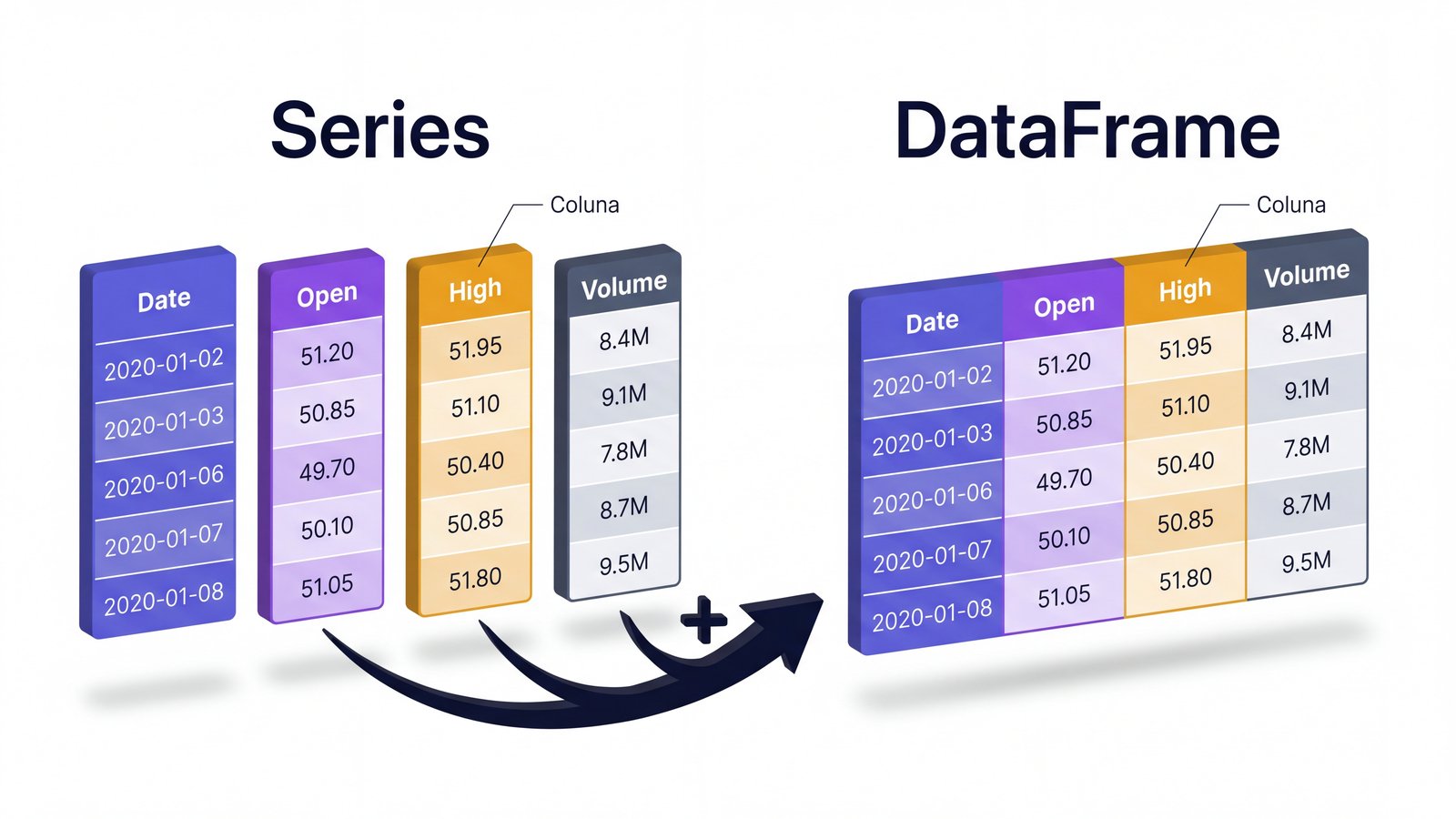
DataFrame é uma Series. O DataFrame é a junção de várias Series alinhadas pelo mesmo índice.Aqui está uma distinção que confunde quem está começando: o DataFrame é a tabela inteira, mas cada coluna isolada é um objeto diferente, chamado Series. Em Python:
type(df) # pandas.core.frame.DataFrame type(df["High"]) # pandas.core.series.Series
Pense no DataFrame como um dicionário de Series, onde a chave é o nome da coluna e o valor é a coluna em si. Isso explica por que existem duas formas equivalentes de selecionar uma coluna:
df["High"] # acesso por colchetes df.High # acesso por atributo
A versão com ponto é mais curta, mas só funciona se o nome da coluna não tiver espaço, acento ou caractere especial. Para nomes complicados ("valor da venda", "R$ total"), você precisa dos colchetes. Pessoalmente, prefiro sempre os colchetes em código de produção: é menos elegante, mas evita bugs sutis quando uma coluna troca de nome.
A Series carrega um índice alinhado com o DataFrame original, o que importa quando você for combinar resultados. Por exemplo, ao calcular df.High - df.Low, o pandas alinha pelos índices antes de subtrair, e o resultado é uma nova Series com o mesmo índice.
Trabalhando com Datas
Quando você importa um csv, o pandas tenta inferir o tipo de cada coluna, mas datas são tratadas como texto a menos que você diga o contrário. No nosso DataFrame, a coluna Date apareceu como object em vez de datetime64. Para conseguir filtrar por mês, ano ou período, é preciso converter explicitamente:
df["Date"] = pd.to_datetime(df["Date"], format="%Y-%m-%d") df.dtypes
Agora Date é datetime64[ns] e ganhamos o acessor .dt, que extrai componentes da data sem precisar de strptime ou regex:
df["Year"] = df.Date.dt.year df["Month"] = df.Date.dt.month df["DayOfWeek"] = df.Date.dt.day_name()
Em três linhas, criamos três colunas novas. Esse tipo de operação, derivar atributos do que já temos, é o pão com manteiga da análise exploratória. A partir daí, fica trivial agrupar por ano, comparar volumes médios por dia da semana ou filtrar só o último trimestre.
Estatísticas Descritivas: O Primeiro Contato com os Números
O método describe() é a forma mais econômica de entender a distribuição das colunas numéricas. Em uma chamada, ele retorna contagem, média, desvio padrão, mínimo, máximo e os quartis (25%, 50%, 75%):
df.describe()
Da saída, três números chamam atenção no nosso BBAS3: o mínimo do Low é R$ 21,91, o máximo do High é R$ 55,70 e a mediana do High é R$ 48,78. Tradução: a ação oscilou entre R$22 e R$56 no período, mas a maior parte do tempo ficou perto de R$48. O período cobre o crash de março de 2020 (início da pandemia de COVID-19), o que explica o vale.
Para uma coluna específica, dá para chamar cada estatística diretamente:
df.High.mean() # 46.58 df.High.median() # 48.78 df.High.std() # 7.48 df.High.min() # 25.00 df.High.max() # 55.70
Os quartis (também chamados de percentis) são tão importantes quanto a média e merecem uma palavra. O Q1 (percentil 25) é o valor abaixo do qual fica 25% dos dados. O Q2 é a mediana (50%). O Q3, 75%. A diferença entre Q3 e Q1 (chamada intervalo interquartil, ou IQR) é uma medida de dispersão robusta a outliers, muito usada em boxplots e em detecção de anomalias.
Mediana é Mais Resistente a Outliers
Repare que a média do High (46,58) é menor que a mediana (48,78). Isso indica que a distribuição é assimétrica, com uma cauda puxando a média para baixo. É exatamente o efeito do crash do COVID, em que poucos dias tiveram preços muito baixos e arrastaram a média.
Para deixar a diferença evidente, considere um exemplo extremo:
amostra = pd.Series([1, 1, 2, 4, 900]) amostra.mean() # 181.6 amostra.median() # 2.0
O outlier 900 puxa a média para 181, mesmo havendo só um valor grande no conjunto. A mediana, por outro lado, é o valor que está no meio depois de ordenar; ela ignora o efeito de outliers. Por isso, em variáveis com cauda longa (renda, preço de imóveis, número de seguidores), a mediana costuma ser um indicador mais honesto do “valor típico” do que a média.
Criando DataFrames do Zero
Nem sempre você parte de um arquivo. Em testes, simulações e exemplos didáticos, é comum precisar construir um DataFrame direto no código. Há três formas principais.
A Partir de um Dicionário
A maneira mais natural em Python: a chave do dicionário vira o nome da coluna, e o valor (uma lista) vira a coluna em si.
dados = {
"nome": ["Carlos", "Theo", "Raquel", "Fernanda"],
"idade": [35, 32, 15, 49],
"cidade": ["Araraquara", "Belém", "Natal", "Curitiba"],
"comprou": [True, False, False, True],
}
clientes = pd.DataFrame(dados)
Essa forma é a mais usada quando os dados já estão organizados por coluna. Se quiser definir um índice próprio, basta atribuir:
clientes.index = [8712, 5831, 4421, 9873]
A Partir de Listas
Quando os dados estão organizados por linha (uma lista de listas), passe a estrutura inteira para o construtor e informe os nomes das colunas:
linhas = [
["Carlos", 35, "Araraquara", True],
["Theo", 32, "Belém", False],
["Raquel", 15, "Natal", False],
["Fernanda", 49, "Curitiba", True],
]
clientes = pd.DataFrame(
linhas,
columns=["nome", "idade", "cidade", "comprou"],
)
A Partir de NumPy
Para simulações ou para gerar datasets sintéticos com determinada distribuição estatística, combina-se numpy com pandas:
import numpy as np
rng = np.random.default_rng(seed=42)
amostras = pd.DataFrame({
"altura_cm": rng.normal(loc=170, scale=10, size=200),
"peso_kg": rng.normal(loc=70, scale=12, size=200),
"horas_sono": rng.normal(loc=7, scale=1.2, size=200),
})
amostras.describe()
Esse padrão é comum em material de aula, em testes unitários de pipelines, e quando você precisa de um dataset mock para validar uma função sem depender de dado real. Fixar a seed (42, no caso) garante que os números aleatórios saiam iguais toda vez, o que torna o exemplo reproduzível para quem ler.
Tratando Valores Ausentes

DataFrame: detectar onde estão os NaN, remover linhas afetadas ou preencher com um valor calculado.Dado real quase nunca vem completo. Campos opcionais ficam em branco, sensores falham, formulários online viram texto livre quando deveriam ser dropdown. Para essa parte, vamos trocar de dataset e usar um real e bem maior: 287 mil corridas de bicicleta compartilhada em Brasília no ano de 2018.
url = "https://dl.dropboxusercontent.com/s/yyfeoxqw61o3iel/df_rides.csv" rides = pd.read_csv(url, parse_dates=["user_birthdate", "ride_date"]) rides.shape # (287322, 10)
Repare no parâmetro parse_dates: passando os nomes das colunas, o pandas já converte para datetime64 na hora da leitura. Em muitos casos, isso te poupa de chamar pd.to_datetime() depois.
Detectando Valores Ausentes
O método isna() devolve um DataFrame booleano: True onde o valor é nulo, False no resto. Combinado com .sum(), conta nulos por coluna:
rides.isna().sum()
Saída:
user_gender 396 user_birthdate 1 user_residence 179905 ride_date 0 time_start 0 time_end 43285 station_start 0 station_end 0 ride_duration 73174 ride_late 73174
Mais de 60% dos registros não tem user_residence informada, e 43 mil corridas não tem horário de fim, provavelmente sessões que não foram fechadas corretamente no aplicativo. Esse mapa de nulos por coluna é o que vai guiar sua decisão sobre o que fazer com cada uma. Ausência também é informação. Se um campo tem 60% de nulos, talvez ele seja opcional no formulário; se tem 0,01%, talvez seja um caso de erro pontual.
Removendo Linhas: dropna
A solução mais simples (e às vezes a errada) é jogar fora as linhas com nulos. O método dropna() faz isso. Use o parâmetro subset para olhar apenas determinadas colunas:
rides_limpo = rides.dropna(subset=["user_residence"]) print(len(rides_limpo)) # 107417
Caímos de 287 mil para 107 mil registros. Em muitos contextos, descartar 60% da base é inviável, porque a perda de informação é alta demais e pode introduzir viés (talvez quem não preencheu user_residence seja um perfil sistematicamente diferente de quem preencheu). É hora de considerar a alternativa.
Preenchendo Nulos: fillna
Em vez de deletar, dá para preencher. A escolha do valor de preenchimento depende do tipo da coluna e do que faz sentido no domínio:
- Numéricas com distribuição assimétrica: mediana costuma ser melhor que média (mais resistente a outliers).
- Categóricas: a moda (valor mais frequente) ou uma categoria explícita como
"desconhecido". - Séries temporais: o último valor válido (
fillna(method="ffill")) ou interpolação.
Para user_residence, que é uma string categórica, vamos preencher com a moda:
moda_residencia = rides["user_residence"].mode()[0] rides["user_residence"] = rides["user_residence"].fillna(moda_residencia)
A moda do dataset é "DF", o que faz sentido, já que o serviço opera em Brasília. Depois do preenchimento, rides.isna().sum() mostra zero nulos na coluna.
Cuidado importante: imputar com mediana ou moda é uma escolha pragmática quando você não tem informação a priori. Não é uma regra universal. Em pipelines de machine learning, isso vira parte de um
Pipelinedoscikit-learn, e é fundamental calcular as estatísticas de imputação só no conjunto de treino para evitar data leakage, ou seja, vazamento de informação do conjunto de teste para o de treino, o que infla artificialmente a performance do modelo.
Para um tratamento mais aprofundado de cada estratégia, vale a leitura do post sobre como tratar dados ausentes com pandas, que entra em casos mais sutis (ausência informativa, MCAR, MAR, MNAR).
Próximos Passos
Você passou pelo essencial: carregar, inspecionar, criar e tratar DataFrames. É o repertório com que começa todo projeto de Data Science. Daqui para a frente, três caminhos são naturais:
- Visualização: histogramas, boxplots e scatter plots fazem o dado falar de uma forma que tabelas não fazem. Pandas integra direto com
matplotlib, e isso será tema do próximo artigo. - Filtragem e agrupamento: métodos como
.query(),.groupby()e.merge()são o que transformam pandas em uma SQL portátil em código. - Pipelines de ML: quando você for treinar um modelo, todo esse tratamento vira um pipeline formal do
scikit-learn, e aí cuidados comdata leakagee validação cruzada passam a importar muito.
Takeaways
- Pandas é o ponto de partida. Carregar com
read_csv, inspecionar cominfo/shape/head, e o métododescribete dá um diagnóstico em segundos. DataFrameé a tabela;Seriesé a coluna. Saber a diferença evita confusão na hora de selecionar e agregar.- Mediana é mais resistente a outliers que a média. Em distribuições assimétricas (renda, preços, tempo de resposta), reporte mediana sempre que possível.
- Valores ausentes contam uma história. Antes de jogar fora ou preencher, olhe
isna().sum()por coluna para entender a estrutura do problema. - Imputação é uma decisão de domínio, não automática. E em ML, calcule as estatísticas de imputação só no treino para não vazar informação.



















