Você já parou para pensar como é possível reconstruir um prédio inteiro em 3D a partir de fotografias comuns? Sem GPS, sem sensor de profundidade, sem laser. Apenas fotos tiradas de diferentes ângulos.
A resposta está no Structure from Motion (SfM), e tudo começa com um passo que muita gente ignora: o feature detection. Antes de qualquer geometria 3D, o algoritmo precisa encontrar pontos distintivos em cada imagem que possam ser reconhecidos em múltiplas vistas. É esse o passo que separa uma reconstrução robusta de um fracasso completo.
Neste artigo, você vai entender o que são features, por que elas importam para reconstrução 3D, e como o algoritmo SIFT funciona por dentro. Vamos implementar cada etapa do zero em Python.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O que o SfM Precisa para Funcionar?
Uma câmera pega o mundo em 3D e projeta tudo numa imagem plana em 2D. Ela comprime uma dimensão. Destrói a profundidade.
Com uma foto só, você não consegue saber onde um ponto estava no espaço. Sabe a direção, mas não a distância. Agora, com duas fotos do mesmo objeto tiradas de posições diferentes, você consegue triangular a posição 3D. É o mesmo princípio dos seus dois olhos.
O pipeline do COLMAP, a ferramenta mais usada para SfM, segue quatro passos. Entender esse pipeline é fundamental para quem estuda matemática da visão computacional e quer ir além da teoria:
- Extração de features em cada imagem
- Correspondência de features entre pares de imagens
- Reconstrução esparsa (geometria epipolar, triangulação, Bundle Adjustment)
- Reconstrução densa (opcional, via Multi-View Stereo)
O primeiro passo é o fundamento de tudo. Se o algoritmo não consegue encontrar pontos confiáveis, nada depois funciona. Vamos mergulhar nele.
O que é Feature Detection?
Um feature é um ponto na imagem que é “interessante” o suficiente para ser detectado novamente em outra imagem da mesma cena. Nem todo pixel serve.
Bons features são:
- Cantos, onde duas bordas se encontram (um canto de janela, uma quina de porta)
- Blobs, regiões com textura distintiva (uma placa, um padrão de tijolos)
- Junções, onde linhas se cruzam
Maus features são:
- Regiões planas, como parede lisa ou céu limpo (nada para “agarrar”)
- Bordas retas, porque você pode deslizar ao longo delas e a aparência não muda
Cada feature detectado tem dois componentes: o keypoint (localização x, y, escala e orientação) e o descriptor (um vetor numérico de 128 números que codifica a aparência da vizinhança).
Por que SIFT?
O COLMAP usa SIFT (Scale-Invariant Feature Transform) por padrão, e com razão. Os descritores SIFT são projetados para ser:
- Invariantes a escala: se você se aproxima ou se afasta, o mesmo feature é detectado
- Invariantes a rotação: se a câmera está inclinada, o descritor permanece o mesmo
- Robustos a mudanças de iluminação: o descritor é baseado em orientações de gradiente, não em valores brutos de pixel
Na prática, quando o COLMAP roda o feature_extractor no dataset South Building (128 imagens de um prédio), ele encontra em média 11.148 keypoints por imagem. Imagens com muita textura arquitetônica chegam a quase 15.000; imagens com muito céu caem para cerca de 8.000.

Repare como os keypoints se concentram nas áreas texturizadas (tijolos, janelas, detalhes decorativos) e são escassos no céu e em superfícies lisas. A razão fica clara quando comparamos diretamente a região de céu com a região do prédio.

O prédio tem aproximadamente 3,4 vezes mais features que a região de céu. Áreas sem features significam sem correspondências, sem correspondências significam sem pontos 3D. Na reconstrução densa, essas regiões aparecem como buracos.
SIFT do Zero: 6 Passos
Agora vem a parte boa. Vamos abrir a caixa-preta e implementar o SIFT passo a passo. O código completo está no notebook que acompanha este artigo.
Passo 1: Espaço de Escalas (Pirâmide Gaussiana)
O insight central do SIFT é que features existem em diferentes escalas. Um canto de janela é visível de perto, mas de longe se mistura com a parede.
Para detectar features em todas as escalas, construímos um espaço de escalas convoluindo a imagem com filtros gaussianos de largura crescente:

Organizamos isso em oitavas. Em cada oitava, o blur aumenta por um fator constante  . Entre oitavas, reduzimos a resolução pela metade.
. Entre oitavas, reduzimos a resolução pela metade.
def construir_espaco_escalas(imagem, n_oitavas=4, n_escalas_por_oitava=5, sigma_base=1.6):
s = n_escalas_por_oitava - 3
k = 2 ** (1.0 / s)
oitavas = []
atual = imagem.copy()
for o in range(n_oitavas):
sigmas = [sigma_base * (k ** i) for i in range(n_escalas_por_oitava)]
imgs_oitava = [gaussian_filter(atual, sigma=sig) for sig in sigmas]
oitavas.append((imgs_oitava, sigmas, atual.shape))
atual = imgs_oitava[-3][::2, ::2]
return oitavas

Conforme o sigma aumenta, detalhes finos desaparecem. Bordas pequenas e texturas são suavizadas, restando apenas estruturas grosseiras.
Passo 2: Diferença de Gaussianas (DoG)
Para encontrar keypoints, precisamos detectar pontos que se “destacam” numa escala particular. O operador ideal seria o Laplaciano da Gaussiana (LoG), mas ele é caro de calcular. O insight de Lowe: a Diferença de Gaussianas é uma boa aproximação:

Como já temos  em múltiplas escalas, calcular DoG é só uma subtração entre níveis consecutivos de blur.
em múltiplas escalas, calcular DoG é só uma subtração entre níveis consecutivos de blur.
def calcular_dog(oitavas):
dog_oitavas = []
for imgs, sigmas, shape in oitavas:
dogs = [imgs[i+1] - imgs[i] for i in range(len(imgs) - 1)]
dog_oitavas.append(dogs)
return dog_oitavas

As regiões vermelho/azul são pontos com forte contraste local. Áreas uniformes ficam perto de zero.
Passo 3: Detecção de Extremos
Um keypoint é um ponto que é extremo local (máximo ou mínimo) no DoG, comparado com seus 26 vizinhos: 8 vizinhos espaciais na mesma escala, mais 9 na escala acima e 9 na escala abaixo.
def detectar_extremos(dog_oitavas, limiar_contraste=0.04):
keypoints = []
for o, dogs in enumerate(dog_oitavas):
for s in range(1, len(dogs) - 1):
anterior, atual, proximo = dogs[s-1], dogs[s], dogs[s+1]
h, w = atual.shape
for y in range(1, h - 1):
for x in range(1, w - 1):
val = atual[y, x]
if abs(val) < limiar_contraste:
continue
cubo = np.array([
anterior[y-1:y+2, x-1:x+2],
atual[y-1:y+2, x-1:x+2],
proximo[y-1:y+2, x-1:x+2],
])
if val == cubo.max() or val == cubo.min():
keypoints.append((o, s, y, x, val))
return keypoints
No nosso recorte de teste, essa etapa encontra 1.026 keypoints brutos. Muitos deles são ruído ou pontos instáveis em bordas. O próximo passo filtra.
Passo 4: Rejeição de Bordas (Filtro tipo Harris)
Pontos em bordas são mal localizados. Para identificá-los, usamos a matriz Hessiana do DoG e verificamos a razão entre os autovalores. Se um autovalor é muito maior que o outro, o ponto está numa borda (curvatura em uma direção apenas).
O teste de Lowe é elegante: só precisa do traço e do determinante da Hessiana, sem decomposição de autovalores.
def filtrar_bordas(dog_oitavas, keypoints, r_limiar=10):
filtrados = []
r_teste = (r_limiar + 1) ** 2 / r_limiar
for o, s, y, x, val in keypoints:
dog = dog_oitavas[o][s]
dxx = dog[y, x+1] + dog[y, x-1] - 2 * dog[y, x]
dyy = dog[y+1, x] + dog[y-1, x] - 2 * dog[y, x]
dxy = (dog[y+1, x+1] - dog[y+1, x-1] - dog[y-1, x+1] + dog[y-1, x-1]) / 4.0
traco = dxx + dyy
det = dxx * dyy - dxy * dxy
if det <= 0:
continue
if traco ** 2 / det < r_teste:
filtrados.append((o, s, y, x, val))
return filtrados

A rejeição de bordas remove quase metade das detecções instáveis. Os keypoints sobreviventes estão principalmente em cantos e blobs bem localizados.
Passo 5: Atribuição de Orientação
Para tornar o descritor invariante a rotação, atribuímos uma orientação dominante a cada keypoint. Calculamos o gradiente (magnitude e direção) na vizinhança e construímos um histograma de 36 bins. O pico do histograma define a orientação dominante.

Cada seta mostra a direção dominante do gradiente. Quando o descritor for calculado, o patch será rotacionado para alinhar com essa orientação. Se a câmera estiver inclinada, o descritor permanece o mesmo.
Passo 6: O Descritor (128 dimensões)
O passo final é o fingerprint. Para cada keypoint:
- Pegamos um patch
 ao redor do keypoint, rotacionado pela orientação
ao redor do keypoint, rotacionado pela orientação - Dividimos em uma grade
 de células
de células - Em cada célula, calculamos um histograma de 8 bins de orientações do gradiente
- Concatenamos:
 valores
valores - Normalizamos, cortamos em 0.2 e renormalizamos
A normalização e o clipping são fundamentais: impedem que um único gradiente domine o descritor, tornando-o robusto a mudanças não-lineares de iluminação.
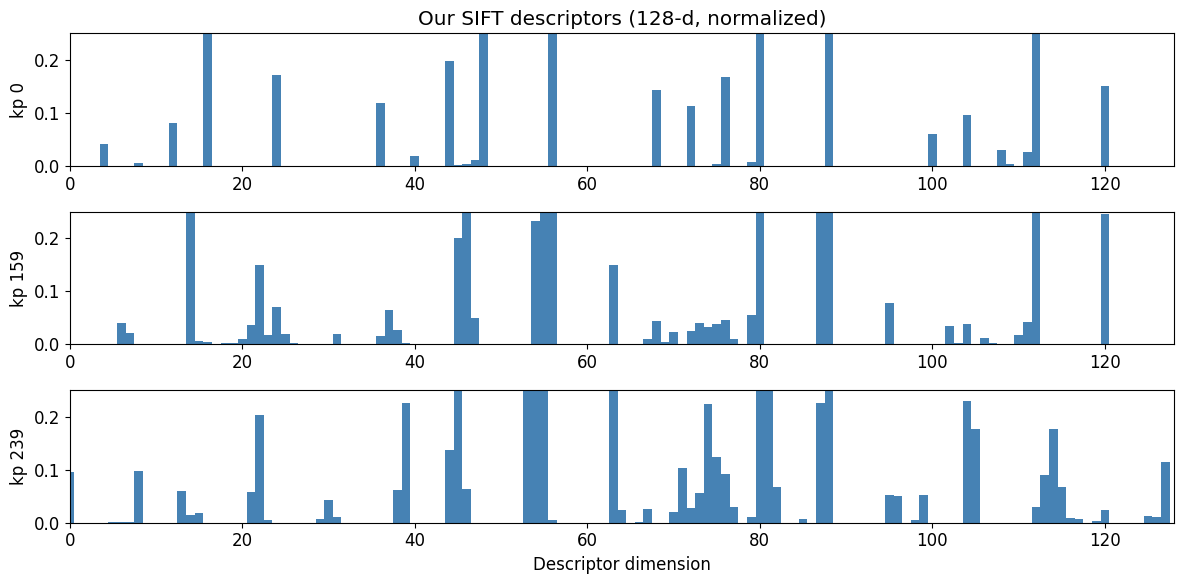
Quando o COLMAP faz feature matching, ele compara a distância euclidiana entre descritores de imagens diferentes. Se dois keypoints têm descritores muito próximos, provavelmente são o mesmo ponto físico visto de ângulos diferentes.
Nosso SIFT versus OpenCV
Para validar a implementação, comparamos com o SIFT otimizado do OpenCV. Os resultados não são idênticos (pulamos refinamento sub-pixel e outras otimizações), mas a distribuição espacial dos keypoints é consistente.

O OpenCV encontra 10.982 keypoints (todas as oitavas, com refinamento sub-pixel), enquanto nossa implementação encontra 479 (apenas oitava 0, sem refinamento). Mas o padrão é o mesmo: concentrados em texturas, escassos em superfícies lisas.
O ponto deste exercício não é igualar a performance do OpenCV. É entender que o SIFT não é mágica. São blurs gaussianos, subtrações, histogramas de gradiente e limiares bem pensados. Cada passo tem uma motivação geométrica ou estatística clara.
Onde Isso se Encaixa no Pipeline
O feature detection é apenas o primeiro passo. Depois dele vem o feature matching (comparar descritores entre pares de imagens usando RANSAC para filtrar correspondências falsas), a estimação da geometria epipolar, a triangulação de pontos 3D, e o Bundle Adjustment que otimiza tudo simultaneamente.
O COLMAP, publicado por Schönberger e Frahm no CVPR 2016, implementa esse pipeline completo. E em 2026, ele ainda é a fundação de praticamente toda técnica moderna de síntese 3D: NeRF precisa das poses das câmeras (COLMAP); Gaussian Splatting precisa das poses e de uma nuvem de pontos inicial (COLMAP); VGGT foi treinado em dados com ground truth gerado por COLMAP. Assim como os Vision Transformers revolucionaram a classificação de imagens, o SIFT revolucionou a forma como extraímos informação geométrica de fotografias.
Quando você vê uma reconstrução 3D bonita saída de um NeRF ou de um Gaussian Splatting, por baixo dos panos alguém rodou o COLMAP antes. E o primeiro passo do COLMAP é exatamente o que você acabou de implementar: feature detection com SIFT.
Takeaways
- Feature detection é o fundamento de toda reconstrução 3D: sem pontos confiáveis, não há correspondências, não há triangulação, não há 3D.
- O SIFT usa 6 etapas: espaço de escalas, Diferença de Gaussianas, detecção de extremos, rejeição de bordas, orientação e descritor de 128 dimensões. Cada etapa tem motivação matemática clara.
- Textura é o que alimenta o pipeline: regiões com textura rica (tijolos, janelas, detalhes) geram milhares de features; superfícies lisas e céu geram buracos na reconstrução.
- O COLMAP (CVPR 2016) ainda é a fundação do 3D moderno: NeRF, Gaussian Splatting e VGGT dependem dele. Entender o fundamento vale mais do que correr atrás de cada ferramenta nova.



















