
E se eu te dissesse que um modelo originalmente criado para traduzir textos consegue analisar imagens com desempenho comparável e, em alguns cenários, superior ao de Redes Neurais Convolucionais?
Pois é exatamente isso que o Vision Transformer (ViT) propõe. E a ideia por trás dele é tão elegante que cabe em uma frase: Corte a imagem em pedaços, trate cada pedaço como uma “palavra” e deixe o Transformer fazer o resto.
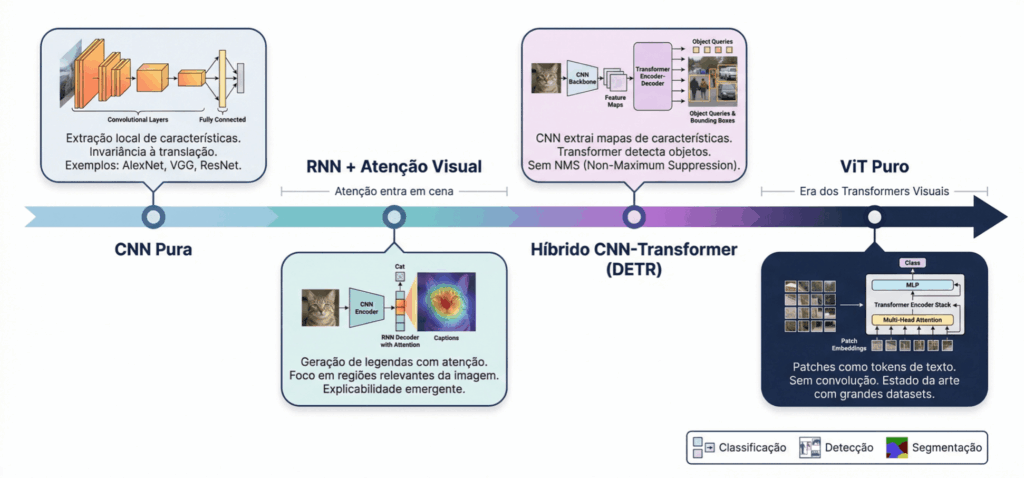
O Vision Transformer (ViT) foi proposto por Dosovitskiy et al. no paper An Image is Worth 16×16 Words, publicado em 2020, e rapidamente se consolidou como uma das arquiteturas mais influentes da visão computacional moderna.
Neste artigo, vou te guiar por cada componente da arquitetura do ViT, desde a criação dos patches até a etapa final de classificação. Ao final, vamos colocar tudo em prática utilizando um modelo pré-treinado para classificar uma imagem real e visualizar os mapas de atenção, entendendo como o modelo distribui seu foco ao longo da imagem.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O Que É o Vision Transformer?
Até 2020, o mundo da visão computacional era dominado por Redes Neurais Convolucionais (CNNs). Desde a LeNet-5 nos anos 90 até a ResNet em 2015, o paradigma era sempre o mesmo: filtros locais deslizando pela imagem, extraindo padrões hierárquicos.
O problema das CNNs é que elas enxergam localmente. Cada filtro olha apenas uma pequena região da imagem por vez. Para que informações distantes se comuniquem, é preciso empilhar muitas camadas.
O ViT propôs algo radical: jogar fora as convoluções e usar apenas Transformers. A mesma arquitetura que revolucionou o processamento de linguagem natural (GPT, BERT) foi aplicada diretamente em imagens.
O resultado? Quando treinado com dados suficientes, o ViT superou as melhores CNNs da época.
Patches: Cortando a Imagem em Pedaços
A primeira pergunta é: como alimentar uma imagem em um Transformer? O Transformer trabalha com sequências de tokens (como palavras em uma frase). Uma imagem é uma grade de pixels, e não uma sequência.
A solução do ViT é simples e engenhosa: dividir a imagem em uma grade de quadrados, chamados de patches. Cada patch é um pedaço da imagem, como uma peça de quebra-cabeça.
Uma imagem de 224×224 pixels dividida em patches de 16×16 gera uma grade de 14×14, ou seja, 196 patches. Cada patch captura uma região local da imagem: um olho, um pedaço do fundo, parte de uma pata.

Pense assim: se o Transformer de texto processa uma sequência de palavras, o ViT processa uma sequência de patches. Cada patch é um “token visual”.
# Dividir uma imagem 224x224 em patches 16x16
patch_size = 16
img_size = 224
n_patches_lado = img_size // patch_size
n_patches_total = n_patches_lado ** 2
print(f"Grade: {n_patches_lado}x{n_patches_lado} = {n_patches_total} patches")
# Grade: 14x14 = 196 patches
Olhando os patches individualmente, vemos que cada um captura uma região diferente da foto: alguns contêm partes do gato, outros pedaços do fundo ou dos galhos.

Patch Embedding: De Pixels para Vetores
Cada patch é uma matriz de pixels (16x16x3 para imagens RGB). Mas o Transformer trabalha com vetores de dimensão fixa. Precisamos converter cada patch em um vetor numérico (isso é o patch embedding).
Na prática, o ViT usa uma convolução com kernel e stride iguais ao tamanho do patch. Essa operação faz duas coisas de uma vez: divide a imagem em patches e projeta cada patch para um vetor de dimensão D.
# Conv2d com kernel=16 e stride=16: divide e projeta em uma operação embed_dim = 768 # dimensão do ViT-Base patch_embed = nn.Conv2d(3, embed_dim, kernel_size=16, stride=16) # Entrada: (1, 3, 224, 224) # Após convolução: (1, 768, 14, 14) # Reorganizado: (1, 196, 768)
O resultado é uma sequência de 196 vetores, cada um com 768 dimensões. Cada patch de 16x16x3 pixels (768 valores) virou um vetor de 768 dimensões – uma representação numérica compacta daquela região da imagem.
CLS Token e Positional Embedding
Antes de entrar no Transformer, dois ingredientes são adicionados à sequência.
O CLS token (de classification) é um vetor especial inserido no início da sequência. Ele funciona como um “observador” que não pertence a nenhum patch específico. Ao passar por todas as camadas de atenção, o CLS token vai acumular informação de todos os patches. No final, é ele que usamos para classificar a imagem.
O Positional Embedding resolve um problema fundamental: o Transformer não tem noção de ordem. Sem ele, o modelo não saberia que o patch do canto superior esquerdo é diferente do canto inferior direito. Somamos um vetor de posição a cada token, dando ao modelo a informação de “onde” cada patch estava na imagem original.
A sequência resultante tem 197 tokens (1 CLS + 196 patches), cada um com 768 dimensões. Essa é a entrada do Transformer.
Self-Attention: A Peça Central
O mecanismo de self-attention é o que torna o Transformer tão poderoso. Ele permite que cada token “olhe” para todos os outros tokens e decida a quem prestar atenção.
A analogia mais útil é a de uma sala de aula. Imagine que cada patch é um aluno. Cada aluno gera três coisas:
- Query (Q): “O que eu estou procurando?”
- Key (K): “O que eu tenho para oferecer?”
- Value (V): “Qual informação eu carrego?”
A atenção é calculada comparando a Query de cada token com as Keys de todos os outros. Quanto mais compatíveis Q e K forem, mais atenção um token dá ao outro. O resultado é uma média ponderada dos Values.
![\[\text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-3119b426f2c95ab2ce98b189b3a4b661_l3.png "Rendered by QuickLaTeX.com")
A divisão por  evita que os valores fiquem grandes demais antes do softmax. É um detalhe simples, mas crucial para a estabilidade do treinamento.
evita que os valores fiquem grandes demais antes do softmax. É um detalhe simples, mas crucial para a estabilidade do treinamento.
Na prática, o ViT não usa uma única attention, usa Multi-Head Attention. A ideia é dividir o embedding em múltiplas “cabeças” que operam em paralelo, cada uma aprendendo a prestar atenção em aspectos diferentes: uma cabeça pode focar em cores, outra em formas, outra em texturas. As saídas são concatenadas no final.
O Bloco Transformer
Cada bloco do Transformer combina duas operações, ambas com conexões residuais e Layer Normalization:
- Multi-Head Self-Attention — os tokens se comunicam entre si
- Feed-Forward Network (FFN) — cada token é processado individualmente por duas camadas lineares com ativação GELU
A estrutura é:
tokens → LayerNorm → Multi-Head Attention → (+residual) → LayerNorm → FFN → (+residual)O ViT-Base empilha 12 desses blocos em sequência. A cada camada, os tokens ficam mais ricos em informação contextual. O CLS token, que começou sem informação, vai progressivamente “ouvindo” todos os patches e construindo uma representação global da imagem.
As conexões residuais (somar a entrada com a saída) facilitam o fluxo de gradientes durante o treinamento e permitem que o modelo empilhe muitas camadas sem degradar o sinal.
Na Prática: Classificando uma Foto de Gato
A verdade é que, no dia a dia, ninguém implementa o ViT do zero. Usamos modelos pré-treinados e fazemos inferência ou fine-tuning. O torchvision já inclui o ViT-B/16 pré-treinado no ImageNet com 1000 classes.
Vamos carregar o modelo e classificar uma foto real de um gato:
from torchvision.models import vit_b_16, ViT_B_16_Weights
# Carregar modelo pré-treinado no ImageNet
weights = ViT_B_16_Weights.IMAGENET1K_V1
model = vit_b_16(weights=weights)
model.eval()
# Pré-processar e classificar
preprocess = weights.transforms()
img_input = preprocess(img).unsqueeze(0)
with torch.no_grad():
output = model(img_input)
probabilidades = F.softmax(output[0], dim=0)
# Top-5 predições
top5_prob, top5_idx = torch.topk(probabilidades, 5)
categorias = weights.meta["categories"]
for i in range(5):
print(f" {categorias[top5_idx[i]]:30s} {top5_prob[i].item():.1%}")
O resultado:
tiger cat 66.2% tabby 16.1% Egyptian cat 8.3% lynx 0.2% tiger 0.1%
O modelo classificou a imagem como tiger cat com 66.2% de confiança, seguido de tabby (16.1%) e Egyptian cat (8.3%). As três primeiras classes são categorias de gatos domésticos – o modelo acertou em cheio. Tudo isso sem treinar nada, usando apenas os pesos pré-treinados no ImageNet.
Visualizando a Atenção: Onde o ViT Está Olhando?
Uma das grandes vantagens do Vision Transformer é a interpretabilidade. Podemos visualizar quais regiões da imagem foram mais importantes para a decisão do modelo.
Para isso, usamos uma técnica chamada attention rollout. Em vez de olhar a atenção de uma única camada (que costuma ser esparsa e difícil de interpretar), o rollout acumula os pesos de atenção de todas as 12 camadas, levando em conta as conexões residuais.
O resultado é um mapa que mostra, de forma agregada, onde o CLS token concentrou sua atenção ao longo de toda a rede.
# Coletar atenção de cada bloco e acumular via rollout
rollout = torch.eye(197).unsqueeze(0) # matriz identidade
for attn in all_attn:
attn_with_residual = attn + torch.eye(197).unsqueeze(0)
attn_with_residual = attn_with_residual / attn_with_residual.sum(dim=-1, keepdim=True)
rollout = attn_with_residual @ rollout
# Extrair atenção do CLS para os 196 patches
cls_attn = rollout[0, 0, 1:].reshape(14, 14).numpy()
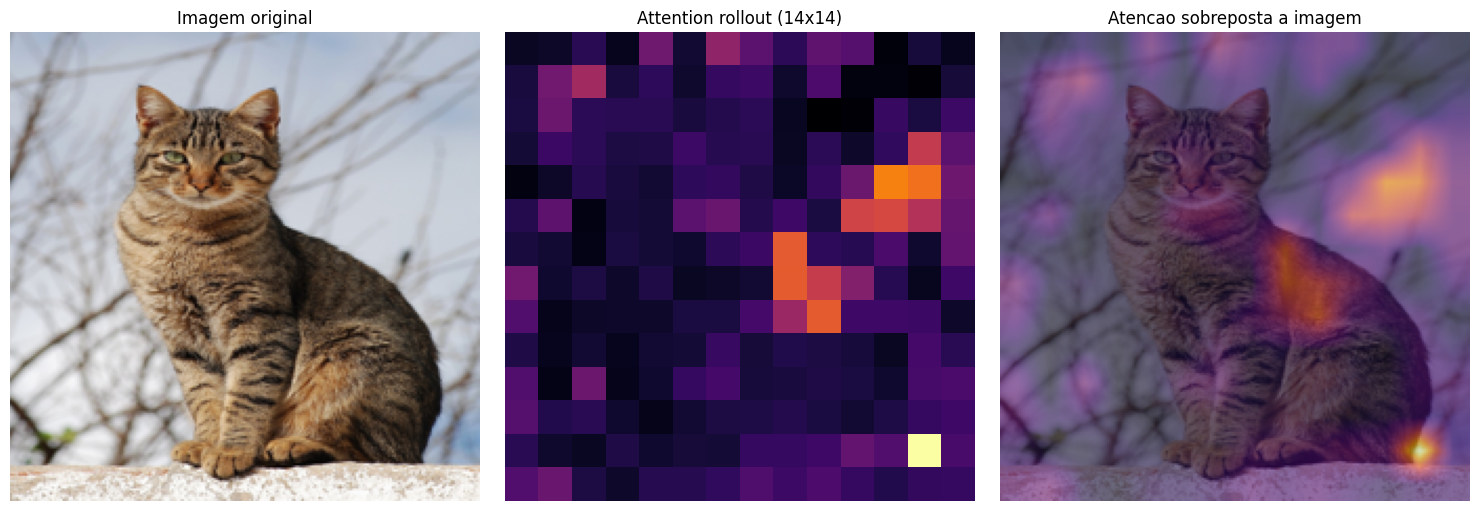
As regiões mais claras no mapa indicam onde o modelo concentrou mais atenção para classificar a imagem. Repare como a atenção se concentra no corpo e na cabeça do gato, ignorando o fundo com galhos e o céu. O ViT aprendeu, sem supervisão explícita, a focar nas regiões mais discriminativas da imagem – exatamente o que um humano faria.
ViT vs CNN: Quando Usar Cada Um?
As CNNs processam a imagem com filtros locais e constroem hierarquias espaciais camada a camada. Elas são eficientes e funcionam bem mesmo com poucos dados. O ViT, por outro lado, processa a imagem de forma global desde a primeira camada.
Ou seja, cada patch pode se relacionar com qualquer outro, independente da distância.
Essa capacidade global tem um preço: o ViT precisa de muito mais dados para aprender boas representações do zero. No paper original, o ViT só superou CNNs quando pré-treinado em datasets massivos como o JFT-300M (300 milhões de imagens). Para datasets menores, CNNs ainda levam vantagem.
Na prática, a estratégia mais comum é usar transfer learning: partir de um ViT pré-treinado em um grande dataset e fazer fine-tuning na sua tarefa específica.
Takeaways
- Imagem como sequência de patches: o ViT divide a imagem em pedaços de 16×16 e trata cada um como um “token”, aplicando a mesma arquitetura Transformer usada em NLP – sem nenhuma convolução.
- Patch embedding com convolução: uma
Conv2dcom kernel e stride iguais ao tamanho do patch divide a imagem e projeta cada patch para um vetor de 768 dimensões em uma única operação.
- CLS token como observador global: um token especial inserido no início da sequência acumula informação de todos os patches via atenção, servindo como representação global da imagem para classificação.
- Self-attention permite comunicação global: diferente das CNNs que enxergam localmente, cada patch no ViT pode se relacionar diretamente com qualquer outro patch da imagem, capturando dependências de longo alcance desde a primeira camada.
- Na prática, use modelos pré-treinados: o ViT-B/16 do torchvision classificou nossa foto de gato como tiger cat com 66% de confiança, e o mapa de atenção confirmou que o modelo foca no animal, ignorando o fundo — tudo com inferência direta, sem treino adicional.



















