O YOLOv9 chegou! Caso você ainda estivesse utilizando modelos anteriores para detecção de objetos, como o YOLOv8 da Ultralytics, não há motivos para se preocupar. Ao longo deste texto, eu irei fornecer todas as informações necessárias para você se atualizar.
Divulgado em 21 de fevereiro de 2024 pelos pesquisadores Chien-Yao Wang, I-Hau Yeh e Hong-Yuan Mark Liao, por meio do artigo “YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information”, este novo modelo demonstrou uma precisão superior em comparação aos modelos YOLO antecessores.
Neste tutorial eu vou apresentar os mecanismos que permitiram ao YOLOv9 atingir a posição de modelo de ponta e ensinar como você pode implementá-lo no Google Colab.
Aprenda Visão Computacional na Prática
O que é YOLOv9?
Abordagens existentes para a detecção de objetos frequentemente enfatizam o design de arquiteturas de rede complexas ou a elaboração de funções objetivo especializadas. No entanto, tendem a negligenciar um problema crucial: a significativa perda de informação dos dados durante sua transmissão pelas camadas da rede.
O YOLOv9 é um modelo de detecção de objetos que introduz o conceito de Programmable Gradient Information (PGI) para lidar com a perda de informação durante a transmissão de dados através de redes profundas.
O PGI permite a preservação completa da informação de entrada necessária para calcular a função objetivo, assegurando assim a obtenção de informações de gradiente confiáveis para a atualização dos pesos da rede.
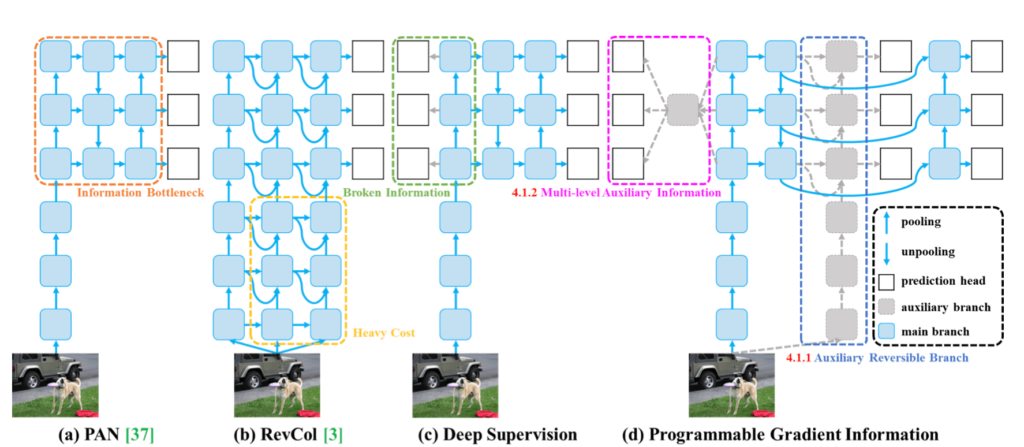
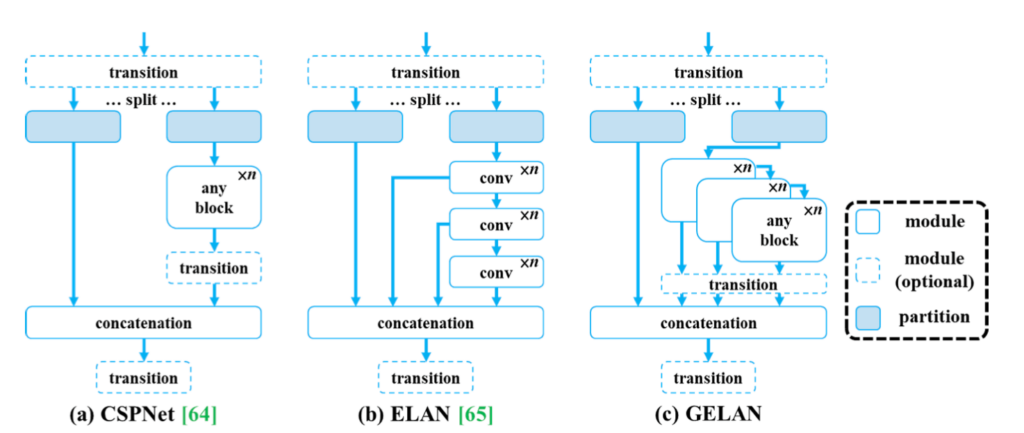
Além disso, o modelo apresenta uma nova arquitetura de rede leve, a Generalized Efficient Layer Aggregation Network (GELAN), baseada no planejamento do caminho do gradiente. Esta arquitetura foi projetada para maximizar a eficiência dos parâmetros e superar métodos existentes em termos de utilização de parâmetros, mesmo utilizando apenas operadores de convolução convencionais.
O modelo e a arquitetura propostos foram validados no dataset MS COCO para detecção de objetos, demonstrando capacidade de obter melhores resultados do que os modelos de estado da arte pré-treinados com grandes conjuntos de dados, mesmo para modelos treinados do zero.
Análise de Desempenho
O YOLOv9 supera significativamente os modelos de detecção de objetos em tempo real anteriores em termos de eficiência e precisão. Comparado a modelos leves e médios, como o YOLO MS, o YOLOv9 possui cerca de 10% menos parâmetros e 5 a 15% menos cálculos, ao mesmo tempo que melhora a precisão (AP) em 0,4 a 0,6%.
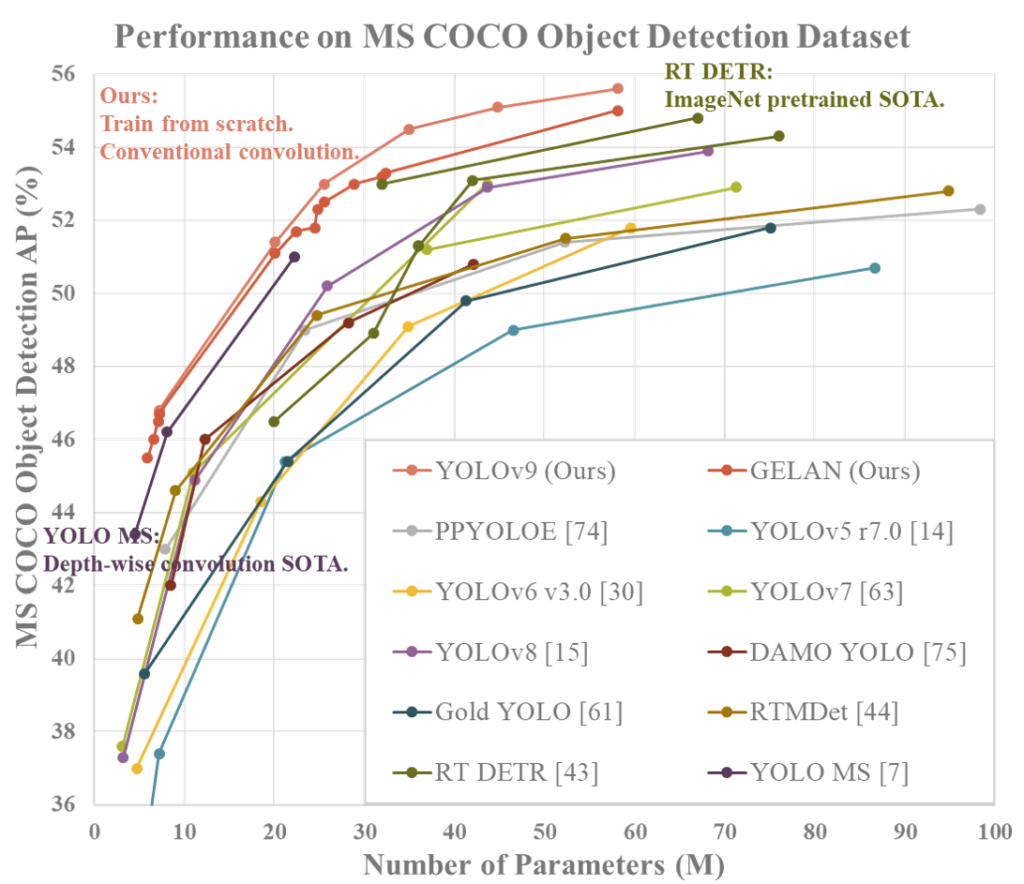
Em comparação com o YOLOv7 AF, o YOLOv9-C reduz os parâmetros em 42% e os cálculos em 21%, mantendo a mesma precisão de 53% em AP. Em relação ao YOLOv8-X, o YOLOv9-X apresenta 15% menos parâmetros e 25% menos cálculos, com uma melhoria significativa de 1,7% em AP.
Esses resultados destacam as melhorias do YOLOv9 em relação aos métodos existentes em todos os aspectos, incluindo a utilização de parâmetros e a complexidade computacional.
Código-Fonte e Licença
Momentos após a publicação do artigo, em 21 de fevereiro de 2024, os autores também disponibilizaram uma implementação do YOLOv9. Há instruções gerais sobre a utilização do modelo, e também comandos para instalação de um ambiente Docker.
São mencionados 4 pesos no README.md: YOLOv9-C, YOLOv9-E, YOLOv9-S e YOLOv9-M. Até o presente momento, os dois últimos não estavam disponíveis ainda.
Quanto à licença, não foi atribuída uma licença oficial até o momento. No entanto, como você pode ver na imagem abaixo, um dos pesquisadores mencionou a intenção de possivelmente adotar a licença GPL3, um bom sinal para aqueles que pretendem usar o modelo comercialmente.
Como Instalar a YOLOv9
Como mencionei no início do artigo, o YOLOv9 é uma novidade. Isso significa que você não encontrará um pacote disponível para instalação via pip ou conda, por exemplo.
Além disso, como é comum com muitos códigos liberados juntamente com artigos científicos, podem ocorrer problemas de compatibilidade e bugs. Por exemplo, ao tentar executar o modelo no Google Colab pela primeira vez, encontrei o erro AttributeError: 'list' object has no attribute 'device' no arquivo detect.py.
Por esse motivo, fiz um fork do repositório onde o problema foi resolvido temporariamente. Eu também preparei um Jupyter Notebook para você abrir no Colab, e que vai economizar muito tempo. Para instalar o YOLOv9 e começar a detectar objetos nas suas imagens e vídeos, clique no link abaixo:
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →# Clona o repositório do YOLOv9 !git clone https://github.com/carlosfab/yolov9.git # Muda o diretório de trabalho atual para o repositório YOLOv9 clonado %cd yolov9 # Instala as dependências necessárias do YOLOv9 a partir do arquivo requirements.txt !pip install -r requirements.txt -q
Este trecho de código realiza a configuração inicial para trabalhar com o modelo YOLOv9 em um ambiente de desenvolvimento. Primeiramente, clona o fork do YOLOv9 do GitHub para o ambiente local usando o comando git clone. Após a clonagem, o comando %cd é utilizado para mudar o diretório de trabalho atual para o diretório do YOLOv9. Finalmente, as dependências necessárias listadas no arquivo requirements.txt do projeto são instaladas com o comando pip install.
# Importa bibliotecas necessárias
import sys
import requests
from tqdm.notebook import tqdm
from pathlib import Path
from PIL import Image
from io import BytesIO
import matplotlib.pyplot as plt
from matplotlib.pylab import rcParams
# Configuração de diretórios para código e dados
CODE_FOLDER = Path("..").resolve() # Diretório do código
WEIGHTS_FOLDER = CODE_FOLDER / "weights" # Diretório para pesos do modelo
DATA_FOLDER = CODE_FOLDER / "data" # Diretório para dados
# Cria os diretórios para pesos e dados, se não existirem
WEIGHTS_FOLDER.mkdir(exist_ok=True, parents=True)
DATA_FOLDER.mkdir(exist_ok=True, parents=True)
# Adiciona o diretório do código ao path do Python para importação de módulos
sys.path.append(str(CODE_FOLDER))
rcParams['figure.figsize'] = 15, 15
%matplotlib inline
Esse trecho inicializa o ambiente para um projeto de visão computacional, importando as bibliotecas necessárias, além de configurar diretórios para código, dados e pesos do modelo, criando-os caso não existam.
# URLs dos arquivos de pesos
weight_files = [
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-c.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/yolov9-e.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-c.pt",
"https://github.com/WongKinYiu/yolov9/releases/download/v0.1/gelan-e.pt"
]
# Itera sobre a lista de URLs para baixar os arquivos de pesos
for i, url in enumerate(weight_files, start=1):
filename = url.split('/')[-1]
response = requests.get(url, stream=True)
total_size_in_bytes = int(response.headers.get('content-length', 0))
block_size = 1024 # 1 Kilobyte
progress_bar = tqdm(total=total_size_in_bytes, unit='iB', unit_scale=True, desc=f"Baixando arquivo {i}/{len(weight_files)}: {filename}")
with open(WEIGHTS_FOLDER / filename, 'wb') as file:
for data in response.iter_content(block_size):
progress_bar.update(len(data))
file.write(data)
progress_bar.close()
Este trecho de código é responsável por baixar arquivos de pesos para modelos a partir de uma lista de URLs especificada na variável weight_files, salvando-os no diretório designado para pesos. Ele percorre cada URL da lista, extrai o nome do arquivo, executa o download em blocos de 1 Kilobyte para gerenciar o uso de memória eficientemente, e monitora o progresso do download com uma barra de progresso visual.
# URL da imagem de teste
url = 'https://sigmoidal.ai/wp-content/uploads/2022/11/314928609_1293071608150779_8666358890956473002_n.jpg'
# Faz a requisição para obter a imagem
response = requests.get(url)
# Define o caminho do arquivo onde a imagem será salva dentro do DATA_FOLDER
image_path = DATA_FOLDER / "test_image.jpg"
# Salva a imagem no diretório especificado
with open(image_path, 'wb') as f:
f.write(response.content)
Este código faz o download de uma imagem de teste a partir de uma URL especificada, utilizando a biblioteca requests para realizar a requisição HTTP e obter o conteúdo da imagem. Após a obtenção da resposta, o conteúdo da imagem é salvo em um arquivo denominado test_image.jpg, localizado dentro de um diretório previamente configurado para dados.
Você também pode subir suas fotos manualmente, caso deseje, arrastando-as para dentro da pasta data.
!python {CODE_FOLDER}/detect.py --weights {WEIGHTS_FOLDER}/yolov9-e.pt --conf 0.1 --source {DATA_FOLDER}/test_image.jpg --device cpu
# !python {CODE_FOLDER}/detect.py --weights {WEIGHTS_FOLDER}/yolov9-e.pt --conf 0.1 --source {DATA_FOLDER}/test_image.jpg --device 0
Agora é só executar o script de detecção, detect.py, localizado no diretório de código CODE_FOLDER, utilizando algum dos pesos que estão salvos no diretório atribuído à variável WEIGHTS_FOLDER. O script é configurado para processar uma imagem de teste (test_image.jpg) encontrada no diretório de dados DATA_FOLDER, com uma confiança mínima (--conf) de 0.1 para a detecção de objetos.
A execução é realizada especificamente na CPU (--device cpu), adequada para ambientes que não dispõem de GPUs. Apesar do Colab fornecer uma certa cota mensal, nem, sempre você terá GPU à disposição. Já a segunda linha, comentada, mostra uma alternativa do comando para execução em uma GPU específica (--device 0).

Atente-se que o resultado de cada teste será salvo dentro da pasta ../runs/detect/..., de maneira similar ao que era feito com o YOLOv8.
Neste tutorial eu mostrei como você pode instalar o YOLOv9 no ambiente do Google Colab. No entanto, neste fork que fiz, preparei a estrutura para que você também consiga usar o poetry para instalar as dependências na sua máquina local.
Caso você seja aluno da minha Especialização em Visão Computacional, saiba que há uma aula inteira dedicada sobre o modelo.
Takeaways
- Introdução ao YOLOv9: Revelando a chegada do YOLOv9, uma evolução significativa em detecção de objetos que supera modelos anteriores como o YOLOv8 da Ultralytics. Este artigo fornece um guia detalhado para se atualizar e implementar o novo modelo.
- Inovação através do Programmable Gradient Information (PGI): O YOLOv9 introduz o conceito de PGI, abordando a perda de informação em redes profundas e permitindo a preservação completa da informação de entrada, o que é crucial para a atualização eficiente dos pesos da rede.
- Arquitetura Avançada GELAN: Além do PGI, o YOLOv9 apresenta a arquitetura Generalized Efficient Layer Aggregation Network (GELAN), otimizando a eficiência dos parâmetros e superando métodos existentes em termos de utilização de parâmetros.
- Desempenho Excepcional: Validado no dataset MS COCO, o YOLOv9 demonstrou superioridade em eficiência e precisão sobre modelos anteriores, oferecendo menos parâmetros e cálculos enquanto melhora a precisão.
- Disponibilidade e Acesso: Logo após sua publicação, os autores disponibilizaram o código-fonte e instruções para uso, apesar de algumas versões dos pesos e licenças específicas ainda estarem pendentes.
- Instalação e Uso Prático: Instruções específicas para a instalação e uso do YOLOv9 no Google Colab são fornecidas, facilitando a aplicação prática do modelo para detecção de objetos em imagens e vídeos.
Neste artigo, eu demonstrei como você pode testar rapidamente essa arquitetura em cima das suas fotos e vídeos. Nos próximos dias, irei trazer mais uma publicação para te ensinar como treinar a YOLOv9 em um dataset customizado. Não deixe de se inscrever e me seguir nas redes sociais.
Cite o Artigo
Use a seguinte entrada para citar este post em sua pesquisa:
Melo Júnior, José Carlos de. “YOLOv9: Aprenda a Detectar Objetos”. Blog do Sigmoidal, 24 fev. 2024. Disponível em: https://sigmoidal.ai/yolov9-aprenda-a-detectar-objetos




















olá, executei seu colab e tive o erro python3: can’t open file ‘/content/detect.py’: [Errno 2] No such file or directory
nao mudei em nada o codigo
como proceder pfv?
Se você executou no Colab e deu erro, pode ser que tenha tido alguma atualização em algum pacote ou arquivo. Vou revisar o código quando eu retornar das férias.