
Imagine que você tira uma foto de um tênis na rua e, em menos de um segundo, recebe dezenas de produtos visualmente parecidos para comprar.
Por trás desses resultados, existe um sistema de Machine Learning cuidadosamente projetado. É o chamado visual search. Inclusive, esse é um case muito cobrado em entrevistas.
Neste artigo, vou te guiar pelos 7 passos do framework de ML System Design para projetar um sistema completo de busca visual.
O Que É Machine Learning System Design?
Antes de mergulhar no visual search, vale entender o framework. ML System Design é a disciplina de projetar sistemas de Machine Learning de ponta a ponta. Não basta escolher um modelo e treinar. Você precisa pensar em requisitos, dados, infraestrutura, métricas e monitoramento.
O framework que vamos seguir tem 7 passos:
- Requisitos: o que o sistema precisa fazer?
- Formulação como problema de ML: como traduzir a necessidade de negócio em uma tarefa de aprendizado?
- Dados: de onde vêm e como preparar?
- Seleção do modelo: qual arquitetura usar?
- Treinamento: como o modelo aprende?
- Métricas de avaliação: como medir se funciona?
- Deploy e monitoramento: como colocar em produção e manter?
Qual Problema Estamos Resolvendo?
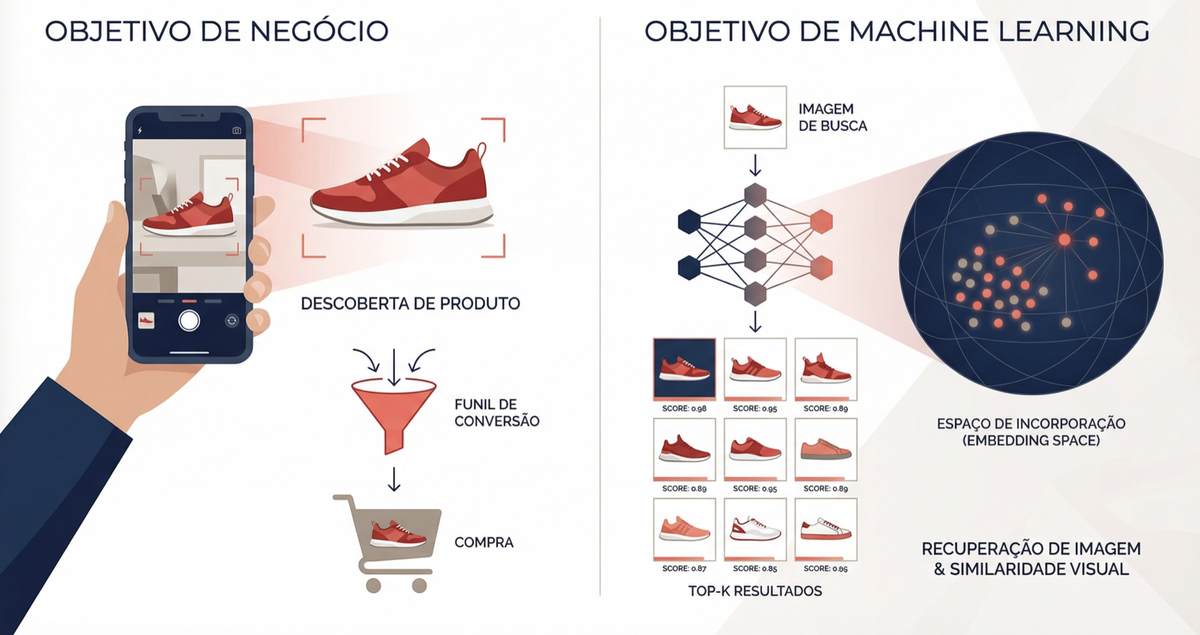
Nosso cenário é um e-commerce com 50 milhões de imagens no catálogo. O usuário tira uma foto de um produto com o celular e o sistema precisa retornar os itens mais parecidos em menos de 200 milissegundos.
O objetivo de negócio é claro: aumentar conversões. Mais cliques em produtos relevantes significam mais vendas. Mas atenção: o modelo de ML não otimiza diretamente a taxa de conversão. Ele otimiza uma proxy, que é a similaridade visual entre imagens.
A conexão entre “imagens parecidas” e “mais vendas” é uma hipótese de negócio que será validada com métricas online.
Como Transformar em Problema de ML?
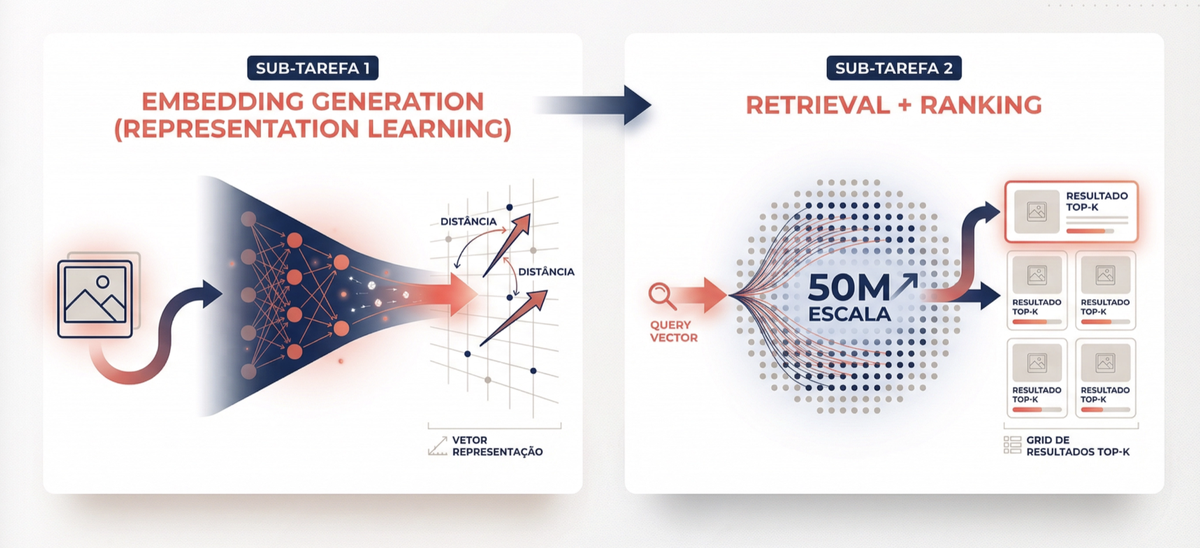
Aqui está o coração do sistema. O problema se divide em duas sub-tarefas:
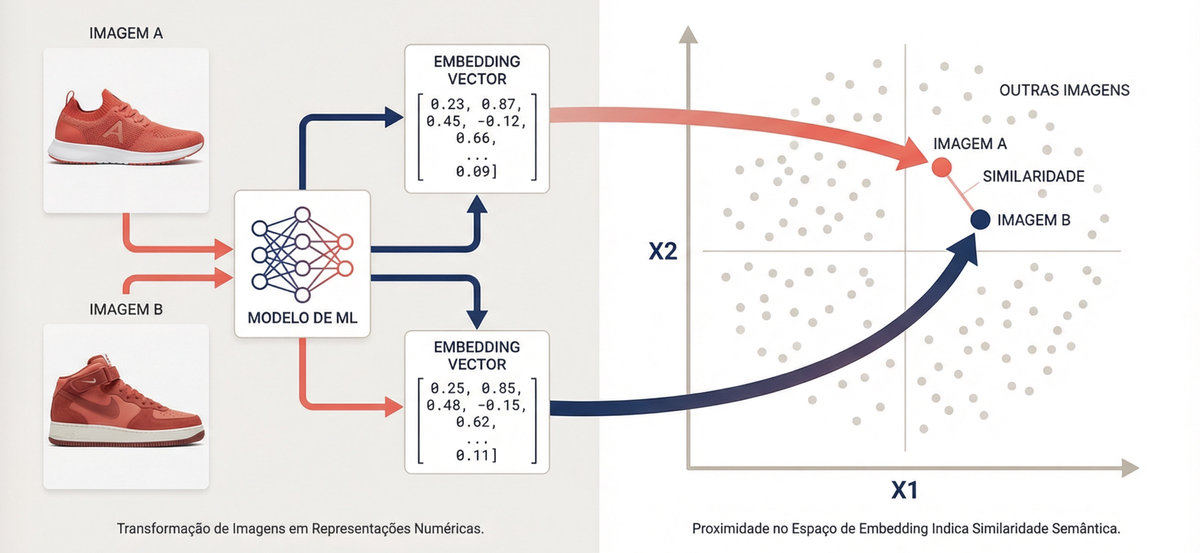
1. Geração de embeddings — transformar cada imagem em um vetor numérico denso que captura suas características visuais. Pense no embedding como o DNA visual da imagem. Produtos parecidos geram vetores próximos no espaço de embeddings, assim como palavras com significados parecidos ficam próximas em modelos de linguagem.
2. Retrieval + Ranking — dado o vetor da imagem de busca, encontrar os vetores mais similares no catálogo e ordenar os resultados.
Como Buscar em 50 Milhões de Imagens?
Comparar o vetor de busca com 50 milhões de vetores um a um seria lento demais. A solução é um pipeline em duas etapas, como uma rede de pesca: primeiro você lança a rede larga para capturar muitos candidatos, depois seleciona os melhores peixes.
Etapa 1 — ANN (Approximate Nearest Neighbors): um algoritmo de busca aproximada varre o índice e retorna cerca de 1.000 candidatos em tempo sub-linear. Ferramentas como FAISS (do Meta) são otimizadas para isso. A busca é aproximada — pode perder alguns resultados relevantes — mas a velocidade compensa. Na prática, parâmetros como nprobe (no IVF) ou ef_search (no HNSW) controlam diretamente o trade-off entre recall e latência: valores maiores recuperam mais candidatos relevantes, mas custam mais tempo.
Um detalhe importante de escala: com 50 milhões de imagens e vetores de 2048 dimensões em float32, o índice ocuparia cerca de 400 GB de RAM. Na prática, técnicas como Product Quantization (PQ) comprimem cada vetor de ~8 KB para ~64 bytes, reduzindo o índice para uma fração do tamanho original com perda mínima de qualidade. Sem quantização, esse sistema simplesmente não caberia em memória de forma viável.
Etapa 2 — Re-ranking: um modelo dedicado de Learning to Rank (LTR) reavalia os 1.000 candidatos. Esse modelo vai além da similaridade visual pura e incorpora sinais adicionais como popularidade, disponibilidade, preço e histórico de cliques. O resultado final são os top 20 produtos mais relevantes. Note que o re-ranker é um modelo de ML treinado separadamente — não é uma simples reordenação por score ponderado.
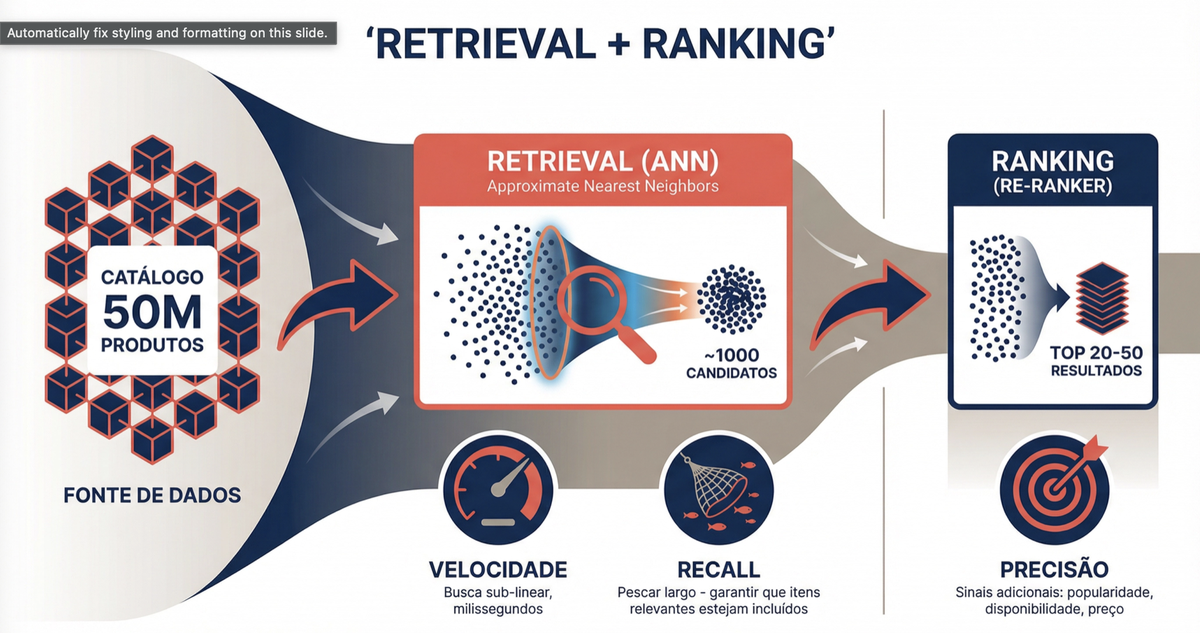
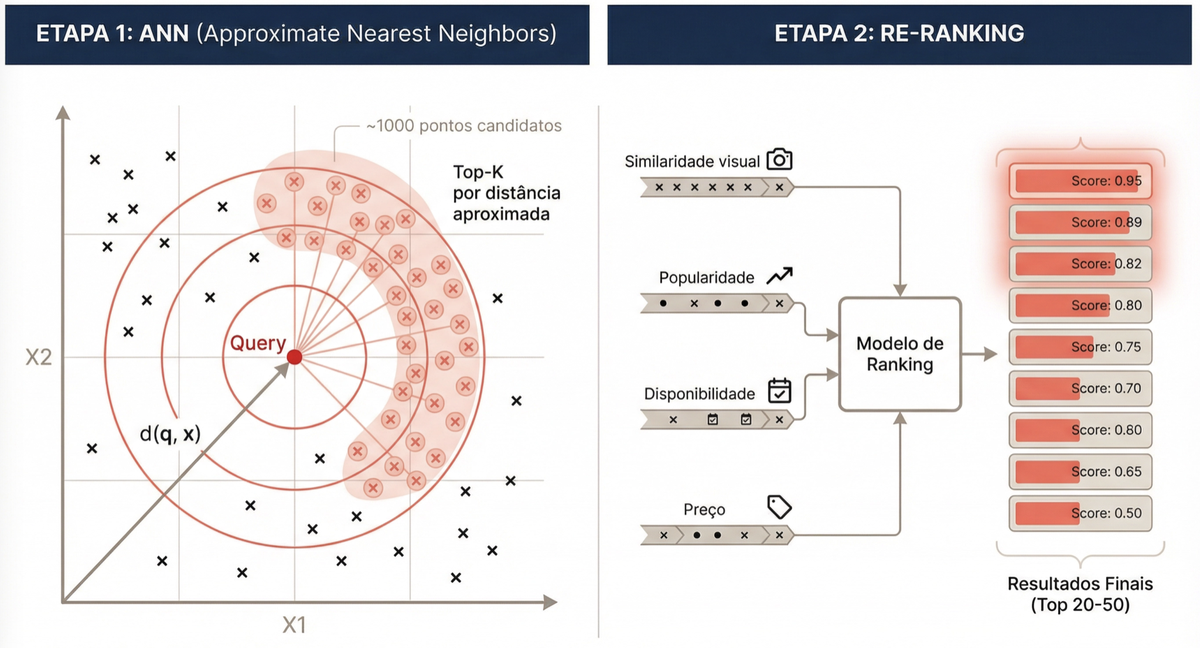
A lógica é simples: na primeira etapa, o que importa é o recall (não perder nenhum item relevante). Na segunda, o foco muda para a precisão (garantir que os resultados exibidos sejam realmente bons).
Como o Modelo Aprende?
O treinamento usa contrastive learning. A ideia é ensinar o modelo a gerar embeddings onde imagens parecidas fiquem próximas e imagens diferentes fiquem distantes.
O processo funciona assim: você define uma imagem âncora, uma imagem positiva (parecida) e várias imagens negativas (diferentes). O modelo processa todas com os mesmos pesos (weight sharing) e a loss function tem dois objetivos simultâneos — minimizar a distância entre âncora e positivo, maximizar a distância entre âncora e negativos.
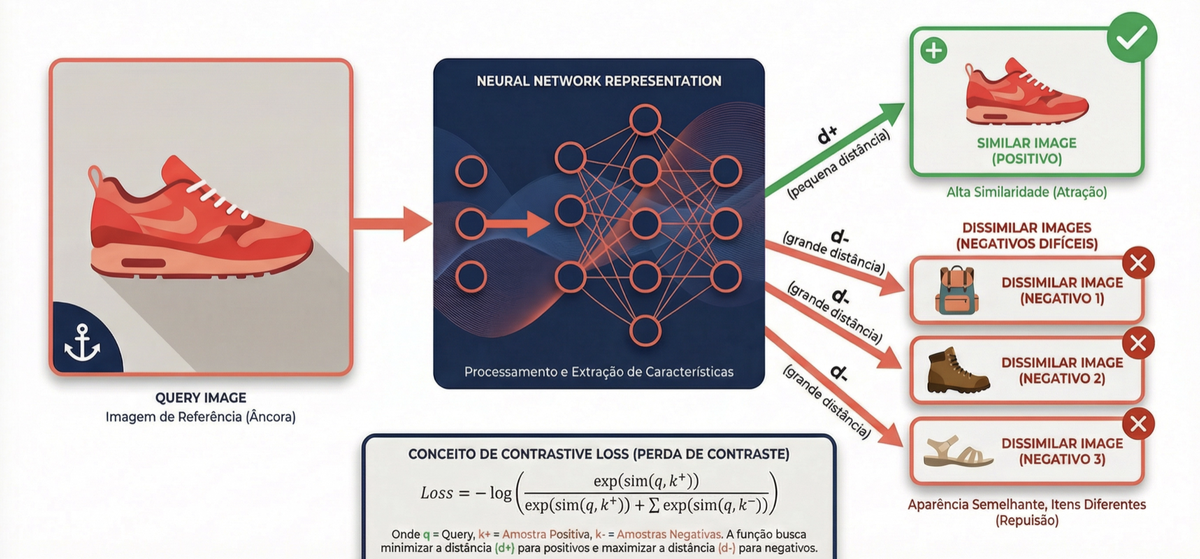
Um detalhe crucial: na prática, a estratégia de seleção de negativos frequentemente tem mais impacto do que trocar uma loss function por outra. Negativos fáceis (um sapato vs. uma paisagem) ensinam pouco. O aprendizado real acontece com hard negatives — exemplos difíceis de distinguir, como uma bota vs. um tênis. São esses casos limítrofes que forçam o modelo a capturar diferenças sutis. Por isso, técnicas de hard negative mining (como selecionar os negativos mais próximos no espaço de embeddings a cada época) são tão importantes quanto a escolha entre triplet loss, contrastive loss ou InfoNCE.
Qual Modelo Usar para Visual Search?
A regra de ouro em entrevistas e na prática: comece simples. Um modelo sofisticado que não supera um baseline trivial é um desperdício de recursos.
Para visual search, a ResNet-50, uma rede neural convolucional com conexões residuais, é um excelente ponto de partida. É rápida, bem documentada, tem pesos pré-treinados no ImageNet e gera embeddings de 2048 dimensões (a saída do average pooling antes da camada FC). Variantes menores como a ResNet-18 geram vetores de 512 dimensões — a escolha depende do trade-off entre qualidade dos embeddings e custo de armazenamento/inferência. Se a ResNet não for suficiente, você pode escalar para arquiteturas mais expressivas.
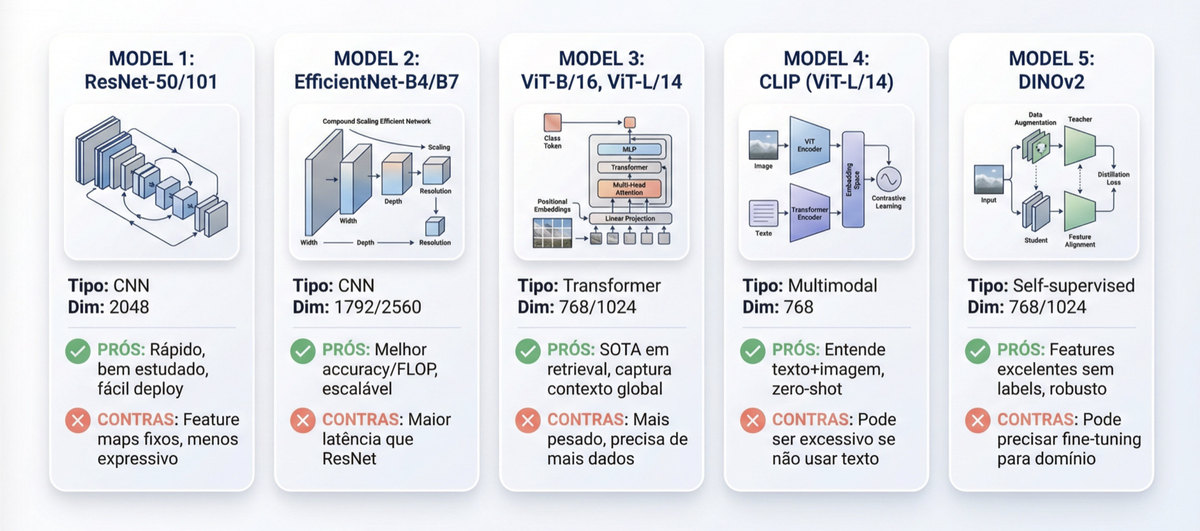
| Modelo | Vantagem | Quando usar |
|---|---|---|
| ResNet-50 | Rápida, fácil de deployar, bom baseline | Começar aqui |
| Vision Transformer (ViT) | Captura contexto global via atenção | Quando precisar de mais expressividade |
| CLIP | Entende texto + imagem (multimodal) | Quando busca textual for necessária |
| DINOv2 | Embeddings visuais de altíssima qualidade (self-supervised) | Forte em retrieval zero-shot; para domínios específicos como moda, um ViT fine-tuned pode superar |
Um ponto importante: CNNs continuam extremamente relevantes na indústria. Modelos como o YOLOv9 alcançam resultados de ponta em detecção de objetos com latência mínima, e muitos sistemas de produção em larga escala ainda rodam sobre backbones convolucionais. Em um sistema de visual search com restrição de 200ms, velocidade importa tanto quanto acurácia.
Como Colocar em Produção?
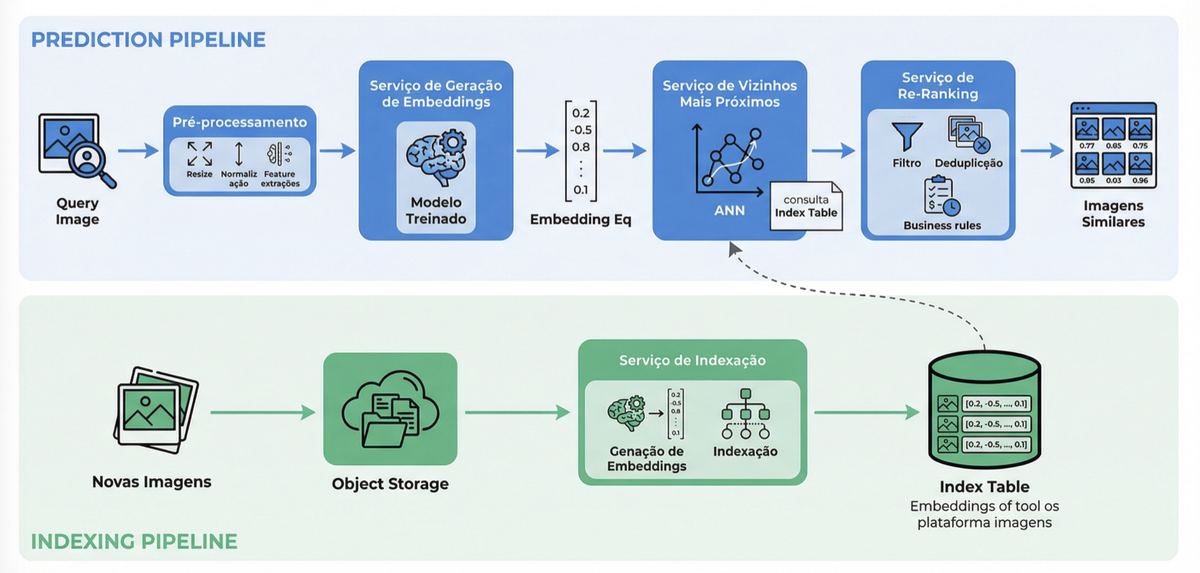
O sistema em produção opera com dois pipelines separados:
Pipeline offline (indexação): processa as imagens do catálogo em batch. Cada imagem passa por pré-processamento (resize para 224×224, normalização), o modelo gera o embedding, o vetor é quantizado e indexado no motor de busca vetorial. Quando novos produtos chegam, o pipeline roda novamente para atualizar o índice.
Pipeline online (serving): atende as buscas em tempo real. O usuário faz upload da foto, o mesmo pré-processamento é aplicado, o modelo gera o embedding da query, o serviço de ANN busca os candidatos no índice, e o re-ranker refina os resultados. Para cumprir a meta de 200ms end-to-end, a escolha do runtime de inferência é crítica — ferramentas como ONNX Runtime, TorchServe ou NVIDIA Triton Inference Server otimizam a execução do modelo com batching dinâmico, quantização em tempo de inferência e suporte a GPU.
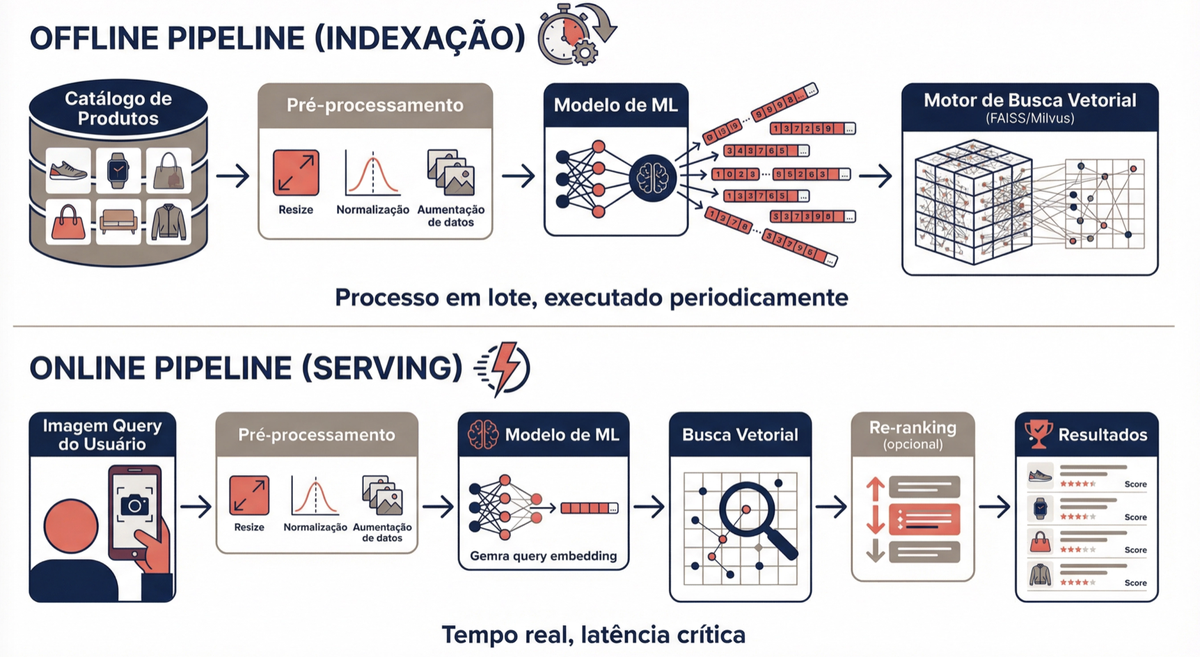
Um detalhe sutil mas crítico: o pré-processamento na inferência precisa ser idêntico ao do treinamento. Se o modelo foi treinado com imagens 224×224 normalizadas por Z-score, a imagem de busca precisa passar pela mesma transformação. Qualquer inconsistência degrada os resultados silenciosamente — esse é um dos bugs mais comuns e mais difíceis de diagnosticar em sistemas de visual search.
Sistemas como o do Pinterest seguem exatamente essa arquitetura de dois pipelines, processando bilhões de imagens com latência de milissegundos.
E Depois do Deploy?
Colocar o modelo em produção não é o fim. É preciso monitorar continuamente.
As métricas offline (Recall@K, Precision@K, NDCG) validam o modelo em datasets de teste. Mas as métricas que realmente importam são as online: CTR (taxa de cliques), tempo de engajamento e conversão. A/B tests comparam versões do modelo com tráfego real.
O sistema também precisa detectar data drift. Em visual search, drift se manifesta de formas específicas: a distribuição de categorias das queries muda com sazonalidade (imagine uma Copa do Mundo, onde todos buscam camisetas de seleções), ou novos tipos de produto aparecem no catálogo sem representação nos dados de treinamento. Para detectar isso, além de monitorar métricas de negócio, vale acompanhar a distribuição dos embeddings de query ao longo do tempo — um shift nessa distribuição é um sinal precoce de que o modelo pode estar perdendo performance antes que o CTR caia visivelmente. Dashboards com alertas automáticos e gatilhos de retreinamento mantêm o sistema saudável.
Takeaways
- Visual search = embeddings + retrieval + ranking. Transforme imagens em vetores, busque os mais próximos com ANN e refine com um re-ranker (modelo de Learning to Rank).
- Comece com um modelo simples (ResNet-50) e escale para ViT, CLIP ou DINOv2 conforme necessário. O que importa na prática são os trade-offs, não a sofisticação.
- A estratégia de seleção de negativos no treinamento frequentemente importa mais que a escolha da loss function. Hard negatives são o que fazem o modelo aprender diferenças sutis.
- Escala exige quantização. Com 50M de imagens, Product Quantization reduz o índice vetorial de centenas de GB para algo viável em memória.
- Dois pipelines distintos: offline para indexar o catálogo, online para servir buscas em tempo real. O pré-processamento precisa ser idêntico em ambos, e o runtime de inferência (Triton, ONNX Runtime) é crucial para cumprir a latência.
- Produção não é “fire and forget”. Monitore métricas online (CTR, engajamento), acompanhe a distribuição dos embeddings de query para detectar drift precocemente, e defina gatilhos automáticos de retreinamento.



















