Como sabemos, as redes neurais convolucionais (convolutional neural networks – CNN) possuem uma grande quantidade de parâmetros a serem otimizados.
Compostas por diversas camadas (layers), cada uma com diversos neurônios, as arquiteturas CNN passam por um processo de treinamento (com um dataset de treino) em uma etapa inicial.
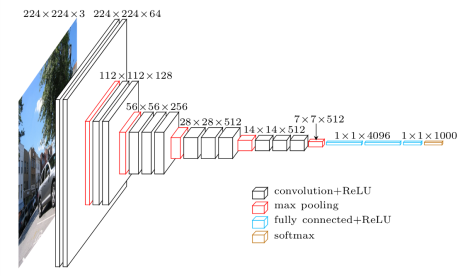
Esse processo de otimização permite, ao longo de várias iterações, encontrar os pesos ideais para cada um dos neurônios da CNN – quanto mais “ideal” os pesos forem, melhor será a acurácia do seu modelo na teoria.
Entretanto, para problemas do mundo real, normalmente não temos um dataset adequado para treinar a CNN. Pode ser que a quantidade de fotos que temos sobre um determinado objeto seja muito pequena para treinar os milhares (ou milhões) de parâmetros, ou que todas as fotos que temos foram batidas do mesmo ângulo.
Uma das consequências de trabalharmos com um dataset de treino desse tipo, é que a CNN não vai ter a generalidade necessária para trabalhar com o conjunto de dados de teste. O modelo vai sofrer do indesejado efeito de overfitting.
As consequências práticas serão que o modelo apresentará um desempenho excelente quando rodado com as imagens de treino, com acurácia altíssima, porem um mau desempenho quando rodamos o dataset de teste.
Data Augmentation é uma técnica para gerar novos exemplares de dados de treinamento a fim de aumentar a generalidade do modelo.
Para reduzir o overfitting existem muitos métodos, como técnicas de normalizações dos pesos, método do dropout (remover aleatoriamente algumas conexões entre neurônios de layers subjacentes), ou batch normalization, cada uma com suas vantagens e características.
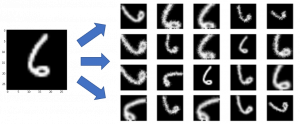
Neste artigo, quero apresentar o método conhecido como data augmentation, que pode ser implementado facilmente com a biblioteca keras – e que vai ajudar você a minimizar o problema nas suas CNN.
O que é data augmentation?
Basicamente, toda modificação feita em um algoritmo com a intenção de reduzir o erro de generalização (mas não o erro de treinamento) é uma técnica de regularização (Goodfellow et al). Bom, a técnica de data augmentation se encaixa exatamente nesse perfil.
Aplicando essa técnica, veremos a nossa precisão no treinamento piorar, porém a precisão sobre o dataset de teste vai melhorar: o modelo CNN se tornará mais genérico.
Como que é possível, usando uma imagem, gerar outras?
São muitas maneiras possíveis, mas os métodos mais comuns são aplicando combinações de operações sobre a imagem original, como:
- Translação;
- Rotação;
- Modificação a perspectiva;
- Achatamento e alongamento;
- Distorção de Lentes.
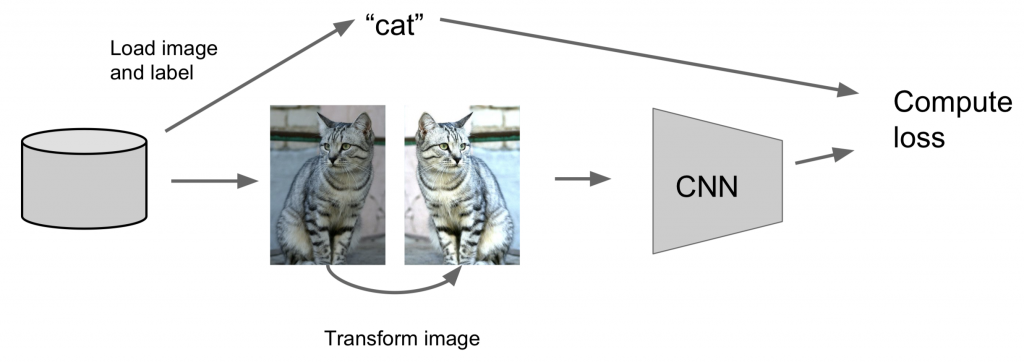
Mesmo para os casos em que seu dataset de treino é “ideal”, o uso de data augmentation pode elevar em alguns pontos percentuais a acurácia do modelo.
Vamos ver agora como gerar novas imagens a partir de um input usando o Keras, de maneira totalmente descomplicada e direta.
Data augmentation usando Python + Keras
A biblioteca keras possui uma classe que facilita muito o nosso trabalho na hora de gerar novas imagens para alimentar o modelo.
Vamos supor que eu quisesse treinar uma CNN para classificar aviões militares, dentre elas o T-27 Tucano – aeronave que tive o privilégio de voar e dar instrução na Academia da Força Aérea (AFA) por 4 anos.

Para melhorar a quantidade de T-27 do nosso conjunto de treino e para generalizar mais o modelo de classificação, vamos gerar 10 novas imagens. O código para fazer isso é bem direto:
# importar os pacotes necessários
import numpy as np
from keras.preprocessing.image import load_img
from keras.preprocessing.image import img_to_array
from keras.preprocessing.image import ImageDataGenerator
# definir caminhos da imagem original e diretório do output
IMAGE_PATH = "./t27_tucano.jpg"
OUTPUT_PATH = "output/"
# carregar a imagem original e converter em array
image = load_img(IMAGE_PATH)
image = img_to_array(image)
# adicionar uma dimensão extra no array
image = np.expand_dims(image, axis=0)
# criar um gerador (generator) com as imagens do data augmentation
imgAug = ImageDataGenerator(rotation_range=45, width_shift_range=0.1,
height_shift_range=0.1, zoom_range=0.25,
fill_mode='nearest', horizontal_flip=True)
imgGen = imgAug.flow(image, save_to_dir=OUTPUT_PATH,
save_format='jpg', save_prefix='t27_')
# gerar 10 imagens por data augmentation
counter = 0
for (i, newImage) in enumerate(imgGen):
counter += 1
# ao gerar 10 imagens, parar o loop
if counter == 10:
break
As Linhas 9 e 10 especificam o caminho do arquivo de entrada (imagem do T-27) e o diretório onde as 10 imagens geradas devem ser salvas.
Após carregar a imagem e transformá-la em um array, é acrescentada uma nova dimensão a este array (Linha 17). Esse procedimento para muita coisa relacionada a CNN. Se a dimensão extra não for incluída, o código vai dar ValueError na execução.
Na Linha 20, é criado um objeto ImageDataGenerator, onde especificamos os valores máximos para o range (em graus) no qual a imagem pode rotacionar, os deslocamentos laterais e verticais (porcentagem em relação à imagem toda), quantidade de zoom e se a imagem pode ser espelhada em relação ao eixo y (horizontal flip).
Na sequência (Linha 24), é criado um generator com os argumentos relacionados à imagem de origem, diretório de output, formato do arquivo e prefixo (nome) das imagens a serem geradas.
O próximo passo para gerar 10 novas imagens é chamar a variável imgGen por 10 vezes, dentro do loop. Como a variável aponta para o generator imgAug.flow, a cada nova chamada um novo arquivo é criado.
Agora é só executar o código e ir conferir o diretório de saída:
carlos$ python data_augmentation.py Using TensorFlow backend. carlos$ ls -A1 output/ t27__0_1061.jpg t27__0_1208.jpg t27__0_386.jpg t27__0_446.jpg t27__0_5674.jpg t27__0_6440.jpg t27__0_891.jpg t27__0_8986.jpg t27__0_9269.jpg t27__0_9351.jpg
Simples, direto, eficiente. Veja as imagens:

Resumo
Definitivamente, overfitting é um problema que você vai ter com seus modelos, principalmente se estiver usando conjuntos de dados pequenos ou que não são estatisticamente representativos.
Uma rede treinada com um dataset inadequado não vai ter a capacidade de ser generalista. Ao contrário, ela vai se sair muito bem com as imagens de treinamento, porém pouco eficiente quando você rodar seu conjunto de teste,
Ao rotacionar, inverter, girar e dar zoom nas imagens de treino, você vai conseguir reduzir o problema do overfitting, pois os pesos dos neurônios estarão mais adaptados a realidade.
Mesmo que o train dataset seja grande, ainda sim a data augmentation pode contribuir para melhorar a eficiência do modelo CNN. Ou seja, sua utilização deve ser sempre considerada dentre todas as outras técnicas de regularização 🙂



















