Você já se pegou lendo uma resposta do ChatGPT que parecia perfeita, mas no fim das contas estava… completamente errada?
Um dos grandes dilemas no uso de modelos de linguagem como o ChatGPT é a chamada alucinação: quando o modelo gera informações falsas, mas com aparência de verdade. Diferente de um simples erro, essas respostas são convincentes!
O artigo “Why Language Models Hallucinate” (Kalai et al., 2025) traz uma análise estatística e sócio-técnica para explicar por que essas falhas persistem mesmo em sistemas de última geração. Neste artigo, reviso os pontos principais do paper.
O que são alucinações
Recentemente, uma influenciadora digital perdeu um voo internacional depois de seguir uma recomendação equivocada do ChatGPT. O modelo “garantiu” que ela poderia embarcar com um documento específico, mas a informação estava errada!
Esse não é um caso isolado. Diversos pesquisadores já relataram exemplos em que o ChatGPT citou artigos acadêmicos que nunca existiram, inventando títulos, autores e até DOI. Para quem não conhece a literatura de perto, o texto soa legítimo. Mas é apenas uma fabricação com aparência científica.

O vilão nessa história tem nome: alucinações! O paper mostra que elas não são um mistério obscuro da inteligência artificial. Na verdade, surgem naturalmente como erros estatísticos em um problema de classificação binária: distinguir entre saídas válidas e inválidas.
Durante o pré-treinamento, mesmo com dados sem ruído, o objetivo de minimizar a cross-entropy inevitavelmente leva a erros. Por exemplo, se 20% dos fatos em um dataset aparecem apenas uma vez (os chamados singletons), então é esperado que o modelo alucine em pelo menos 20% desses casos.
Ou seja, há uma inevitabilidade matemática: se o modelo precisa generalizar para fatos raros, ele vai errar. E esses erros se manifestam como respostas falsas, mas plausíveis.
Inscreva-se na Newsletter
Receba artigos sobre Data Science e IA direto no seu email.
✓ Inscrito com sucesso!
Erros causados no pré-treinamento
Durante o pré-treinamento, o modelo aprende a distribuição da linguagem em um grande corpus textual. O artigo mostra que, mesmo em um cenário ideal com dados livres de erros, a própria formulação estatística do problema leva inevitavelmente à geração de saídas inválidas.
Para entender isso, os autores estabelecem uma analogia com um problema de classificação binária, chamado Is-It-Valid (IIV). Nesse problema, cada resposta candidata é rotulada como válida (+) ou inválida (−).

A dificuldade é que, para gerar texto, o modelo precisa implicitamente resolver várias instâncias do problema IIV em sequência: a cada token previsto, decidir se aquela continuação é válida ou não.
A Figura acima ilustra essa ideia. Ela mostra que classificadores podem ser bastante precisos em domínios simples, como soletração (spelling), mas ainda assim falham em contextos onde:
-
O modelo usado é inadequado (por exemplo, aplicar um separador linear em dados não lineares);
-
Não há padrão aprendível nos dados, como nos casos de fatos arbitrários (ex.: aniversários).
Esse último cenário é central: se não existe regularidade estatística no dado, o modelo só pode “chutar”. É por isso que, no exemplo dado no paper, mesmo informações triviais como “quantas letras D existem em DEEPSEEK” acabam sendo respondidas de forma incorreta.
Em resumo, o pré-treinamento não elimina erros: ele garante uma taxa mínima de alucinações proporcional à raridade dos fatos presentes no corpus.
Por que Alucinações sobrevivem ao pós-treinamento
Se o pré-treinamento já garante uma taxa inevitável de erros, seria de se esperar que o pós-treinamento corrigisse o problema. Afinal, técnicas como Reinforcement Learning with Human Feedback (RLHF) ou Direct Preference Optimization (DPO) foram introduzidas justamente para alinhar os modelos ao comportamento humano.
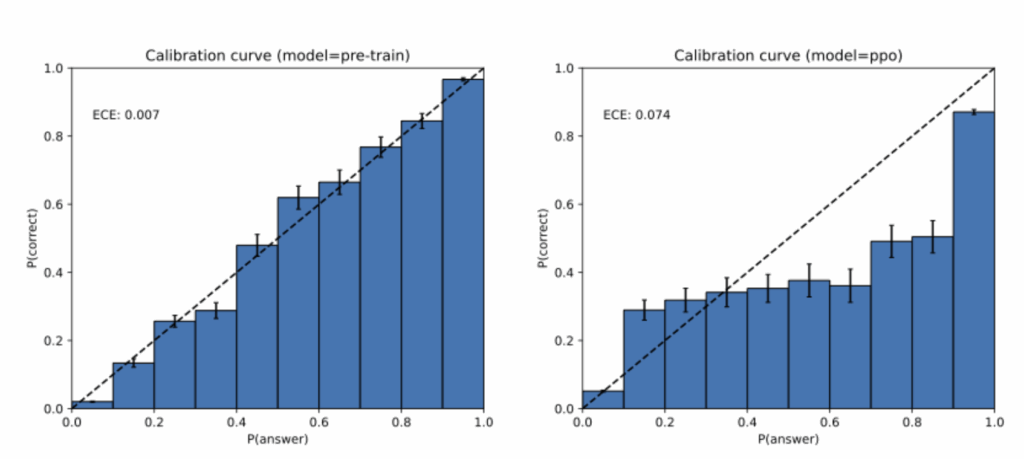
O paper mostra, no entanto, que o pós-treinamento não elimina as alucinações; ele apenas as transforma. O motivo está nos incentivos embutidos nos próprios benchmarks de avaliação. A maioria das métricas utiliza esquemas binários de correção (0-1): a resposta correta vale 1, qualquer outra coisa vale 0.
Nesse contexto, dizer “não sei” não rende nada, enquanto arriscar uma resposta errada ainda pode render ponto.
A analogia usada pelos autores é a de estudantes em uma prova: quando não têm certeza, muitos chutam uma alternativa. Isso maximiza a nota esperada, mesmo que a confiança seja baixa.

Esse desalinhamento cria o que os autores chamam de uma “epidemia de penalização da incerteza”. Modelos que tentam ser mais responsáveis (por exemplo, devolvendo IDK) são prejudicados nas métricas. Já os que chutam sempre, soam mais “inteligentes” e terminam melhor posicionados nos rankings.
Portanto, o motivo pelo qual alucinações sobrevivem ao pós-treinamento não é técnico, mas sócio-técnico: a comunidade de pesquisa ainda recompensa, de forma indireta, respostas inventadas em vez de incerteza honesta.
Como mitigar as “mentiras” do ChatGPT
Grande parte das discussões sobre alucinação foca apenas em melhorar os modelos com mais dados, arquiteturas mais sofisticadas ou integração com mecanismos de busca. O artigo mostra, no entanto, que a raiz do problema está nos incentivos de avaliação.
Hoje, benchmarks consagrados premiam o chute confiante e punem a abstenção (IDK), o que acaba reforçando exatamente o comportamento que queremos evitar. Mitigar essas falhas exige, portanto, mudar a forma como testamos e avaliamos os modelos.
Entre as estratégias mais promissoras destacam-se:
-
Recompensar abstenções em vez de penalizá-las, permitindo que “não sei” seja uma resposta válida.
-
Estabelecer alvos de confiança explícitos, como instruções do tipo: “Responda apenas se estiver >75% confiante.”
-
Incorporar essas métricas nos benchmarks principais, em vez de criar apenas testes paralelos de alucinação.
-
Medir calibração comportamental, verificando se o modelo abstém quando a probabilidade de acerto é baixa.
-
Delegar fatos objetivos a pipelines determinísticos (lookup em bases de dados, cálculos exatos, regras fixas).
O insight central é que ChatGPT “mente” porque é recompensado por mentir com confiança. A raiz está no casamento de duas forças: (1) limitações estatísticas inevitáveis do aprendizado, e (2) métricas de avaliação desalinhadas que premiam palpites sobre incerteza.
Corrigir alucinações, portanto, não será apenas um avanço técnico, mas uma mudança cultural na forma como medimos o progresso em IA.
Takeaways
-
Alucinações não são mistério: elas surgem naturalmente como erros estatísticos no pré-treinamento, equivalentes a falhas em problemas de classificação binária.
-
Singletons importam: fatos raros (que aparecem apenas uma vez no dataset) têm probabilidade alta de gerar respostas falsas, estabelecendo um limite inferior inevitável de alucinações.
-
Modelos pobres também erram: restrições de arquitetura ou representações inadequadas (como n-grams antigos ou tokenização imperfeita) aumentam a taxa de erros.
-
O pós-treinamento reforça chutes confiantes: como benchmarks atuais penalizam abstenções (IDK), os modelos aprendem a inventar respostas em vez de admitir incerteza.
-
Mitigação é sócio-técnica: mudar benchmarks para incorporar alvos de confiança e não penalizar “não sei” é essencial para reduzir o incentivo a respostas falsas, tornando os modelos mais confiáveis.



















