Se alguém te perguntar qual é a matemática por trás do machine learning, você saberia explicar?
Essa é uma das perguntas mais comuns entre quem está começando na área de matemática para machine learning. E a resposta costuma gerar frustração: muitos cursos pulam direto para o código, e quando você finalmente precisa entender por que o modelo funciona, a base não está lá.
A boa notícia é que o núcleo matemático de machine learning não é tão inacessível quanto parece. Neste artigo, vou apresentar os fundamentos que conectam dados, modelos e aprendizado. Se você entender esses conceitos, vai conseguir ler papers, debugar modelos e ter conversas técnicas com muito mais confiança.
Inscreva-se na Newsletter
Receba artigos sobre Data Science e IA direto no seu email.
✓ Inscrito com sucesso!
O núcleo de machine learning
Todo modelo de machine learning se apoia em três pilares: dados, modelo e aprendizado. Antes de falar sobre gradientes e funções de custo, precisamos entender como a matemática representa cada um deles.
Dados como vetores e matrizes
Quando você trabalha com dados tabulares, cada instância (uma linha da tabela) pode ser representada como um vetor. Se eu tenho uma pessoa com idade 30, salário de 5.000 reais e 4 anos de experiência, isso é um vetor:
![\[\mathbf{x}_1 = \begin{bmatrix} 30 \\ 5000 \\ 4 \end{bmatrix}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-923c9631aa6e1e15450f190a105b5319_l3.png "Rendered by QuickLaTeX.com")
Cada elemento desse vetor é uma feature. Quando eu junto todas as instâncias do meu dataset, tenho uma matriz  , onde cada linha é uma instância e cada coluna é uma feature:
, onde cada linha é uma instância e cada coluna é uma feature:
![\[\mathbf{X} \in \mathbb{R}^{n \times d}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-efc688dfcb2dc88468f22c2bff35b505_l3.png "Rendered by QuickLaTeX.com")
Aqui,  é o número de instâncias e
é o número de instâncias e  é o número de features. Essa notação pode parecer intimidadora, mas ela só diz: “tenho uma tabela com linhas e colunas de números reais”. Pronto.
é o número de features. Essa notação pode parecer intimidadora, mas ela só diz: “tenho uma tabela com linhas e colunas de números reais”. Pronto.
Métodos supervisionados e labels
No aprendizado supervisionado, cada instância  tem um label
tem um label  associado. O dataset supervisionado é um conjunto de tuplas:
associado. O dataset supervisionado é um conjunto de tuplas:
![\[\{(\mathbf{x}_1, y_1), (\mathbf{x}_2, y_2), \ldots, (\mathbf{x}_n, y_n)\}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-9082d4d5a1b12c8f0c7fdfbe6559cb81_l3.png "Rendered by QuickLaTeX.com")
Se estou prevendo salários com base na idade e experiência, os salários são meus labels. O objetivo é aprender uma função  tal que:
tal que:
![\[y_i \approx f(\mathbf{x}_i)\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-39b0344bb143d7896c68af2ed3a097a1_l3.png "Rendered by QuickLaTeX.com")
Essa é a essência de todo modelo supervisionado. O resto é detalhe de implementação.
O modelo como função
A forma mais simples de representar um modelo é como uma função linear. Vamos começar pelo caso mais básico: uma única feature e um único output.
A equação da reta
Lembra da equação da reta do ensino médio?
![\[y = ax + b\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-37e728019cdc8738443481dfcb067b5c_l3.png "Rendered by QuickLaTeX.com")
Em machine learning, usamos a mesma ideia com notação diferente:
![\[\hat{y} = \theta_1 x + \theta_0\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-7ab07149906abcc5993ecbe8c9ea7a27_l3.png "Rendered by QuickLaTeX.com")
Aqui,  é a inclinação (o quanto
é a inclinação (o quanto  muda quando
muda quando  aumenta em uma unidade) e
aumenta em uma unidade) e  é o intercepto. O “chapéu” em
é o intercepto. O “chapéu” em  indica que é uma previsão, não o valor real.
indica que é uma previsão, não o valor real.
Para múltiplas features, a equação se generaliza:
![\[\hat{y} = \theta_0 + \theta_1 x_1 + \theta_2 x_2 + \ldots + \theta_d x_d\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-9b8722e539bf9013d647968e4e51f6c1_l3.png "Rendered by QuickLaTeX.com")
Ou, de forma mais compacta, usando notação vetorial:
![\[\hat{y} = \boldsymbol{\theta}^T \mathbf{x}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-a67aabe622e024e77d9db979dbd956e2_l3.png "Rendered by QuickLaTeX.com")
Onde  é o vetor de parâmetros que o modelo precisa aprender.
é o vetor de parâmetros que o modelo precisa aprender.
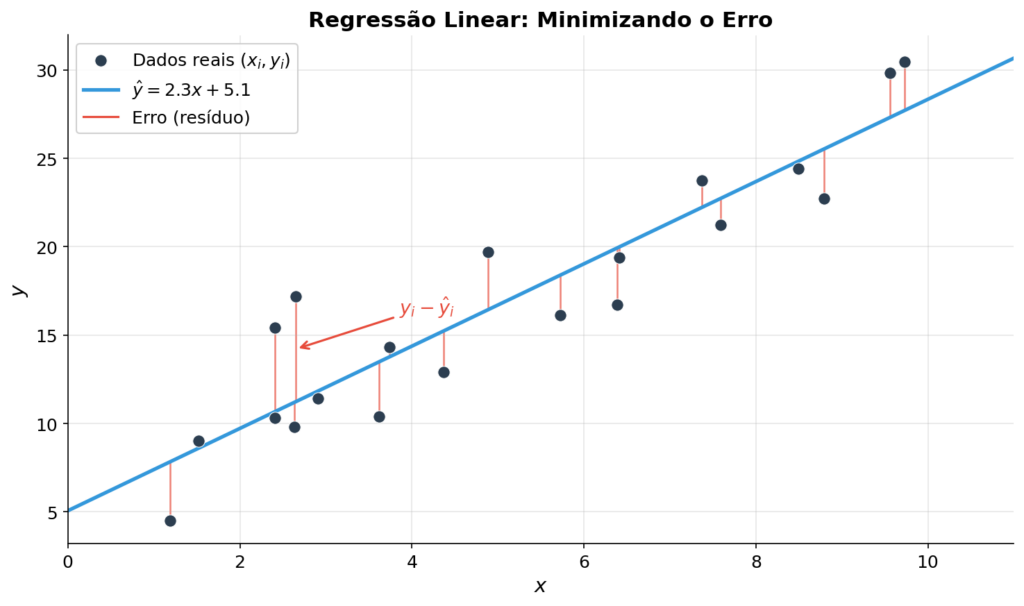
A função de custo: medindo o erro
Se o modelo faz previsões, precisamos de uma forma de medir o quão erradas essas previsões são. É aí que entra a função de custo (loss function).
Distância do ponto à reta
Uma abordagem intuitiva é calcular a distância entre cada ponto real e a reta prevista. Da geometria analítica, a distância de um ponto  a uma reta
a uma reta  é:
é:
![\[d = \frac{|ax_0 + by_0 + c|}{\sqrt{a^2 + b^2}}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-750e07e3ff52527afac7810333b5346e_l3.png "Rendered by QuickLaTeX.com")
Erro Quadrático Médio (MSE)
Na prática, a métrica mais usada para regressão é o Mean Squared Error (MSE):
![\[\text{MSE} = \frac{1}{n} \sum_{i=1}^{n} (y_i - \hat{y}_i)^2\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-ac5925b3c32fdf214f6a4efebeb72b98_l3.png "Rendered by QuickLaTeX.com")
Para cada instância, calculo a diferença entre o valor real e a previsão  , elevo ao quadrado (para eliminar valores negativos e penalizar erros grandes), e tiro a média.
, elevo ao quadrado (para eliminar valores negativos e penalizar erros grandes), e tiro a média.
O objetivo do modelo é encontrar os parâmetros que minimizam essa função de custo:
![\[\boldsymbol{\theta}^* = \arg\min_{\boldsymbol{\theta}} \frac{1}{n} \sum_{i=1}^{n} (y_i - \boldsymbol{\theta}^T \mathbf{x}_i)^2\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-220ef4ce623a763c01a5bb37d38154de_l3.png "Rendered by QuickLaTeX.com")
Aprendizado: como o modelo encontra os parâmetros
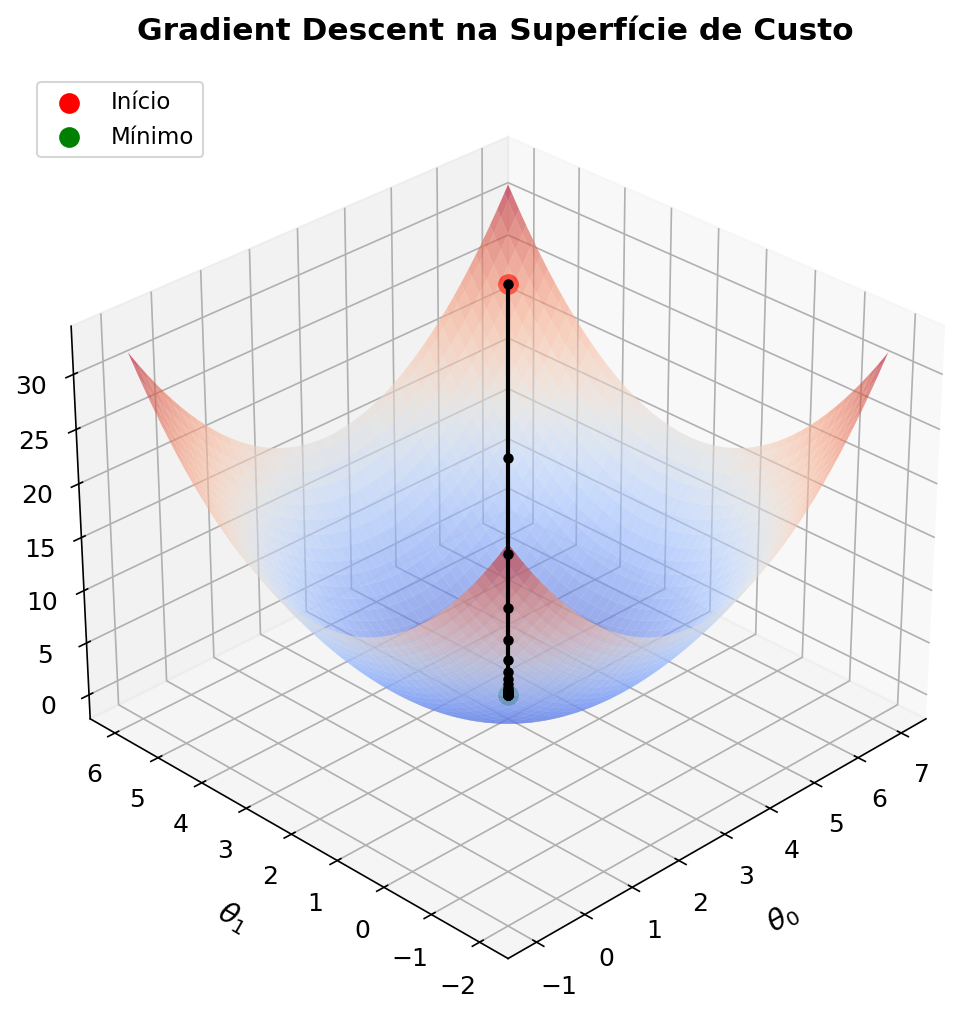
Chegamos ao ponto central. Aprender, em machine learning, significa encontrar os parâmetros que resultam no menor erro possível.
Para uma regressão linear simples com um ou dois parâmetros, a função de custo forma uma parábola ou uma superfície em forma de “tigela”. O ponto mais baixo dessa superfície é onde o erro é mínimo, e é exatamente o que queremos encontrar.
Por que precisamos de derivadas?
Em casos simples, poderíamos resolver analiticamente (igualando a derivada a zero). Mas quando o modelo tem milhares ou milhões de parâmetros, resolver de forma fechada se torna computacionalmente inviável. É como tentar encontrar o ponto mais baixo de um terreno montanhoso sem GPS.
É por isso que usamos algoritmos iterativos como o gradient descent. E é por isso que derivadas são tão importantes.
A derivada como mapa de direção
A derivada de uma função em um ponto indica a inclinação naquele ponto. Se a inclinação é positiva, a função está subindo. Se é negativa, está descendo.
Pense assim: você está vendado em uma montanha e quer chegar ao vale mais baixo. A derivada é como um sensor que te diz se o chão está inclinado para a esquerda ou para a direita. Seguindo sempre a direção de descida, eventualmente você chega ao fundo.
Para uma função  , a derivada é:
, a derivada é:
![\[f'(x) = \lim_{h \to 0} \frac{f(x + h) - f(x)}{h}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-0e9816b8102b692136874649342ccefb_l3.png "Rendered by QuickLaTeX.com")
Para funções com múltiplas variáveis, calculamos derivadas parciais em relação a cada parâmetro, formando o vetor gradiente:
![\[\nabla f(\boldsymbol{\theta}) = \begin{bmatrix} \frac{\partial f}{\partial \theta_0} \\ \frac{\partial f}{\partial \theta_1} \\ \vdots \\ \frac{\partial f}{\partial \theta_d} \end{bmatrix}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-287defc70f302a884cafa79a2b1747ae_l3.png "Rendered by QuickLaTeX.com")
O gradiente aponta na direção de maior crescimento da função. Para minimizar, andamos na direção oposta.
Gradient Descent
O algoritmo de gradient descent é elegantemente simples:
- Comece com parâmetros aleatórios
- Calcule o gradiente da função de custo em relação a
- Atualize os parâmetros na direção oposta ao gradiente
- Repita até convergir
A regra de atualização é:
![\[\boldsymbol{\theta} \leftarrow \boldsymbol{\theta} - \alpha \nabla J(\boldsymbol{\theta})\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-924e0b8fbd3c3a2538a28aa45bb0ed77_l3.png "Rendered by QuickLaTeX.com")
Onde  é a taxa de aprendizado (learning rate), que controla o tamanho do passo a cada iteração. Se for muito grande, o modelo pode “pular” o mínimo. Se for muito pequeno, a convergência será lenta demais.
é a taxa de aprendizado (learning rate), que controla o tamanho do passo a cada iteração. Se for muito grande, o modelo pode “pular” o mínimo. Se for muito pequeno, a convergência será lenta demais.
Para a regressão linear com MSE, as derivadas parciais são:
![\[\frac{\partial J}{\partial \theta_j} = \frac{2}{n} \sum_{i=1}^{n} (\hat{y}_i - y_i) \cdot x_{ij}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-99e748455be53ddba75fd9dacb5439fc_l3.png "Rendered by QuickLaTeX.com")
A cada iteração, cada parâmetro  é ajustado proporcionalmente ao erro e ao valor da feature correspondente.
é ajustado proporcionalmente ao erro e ao valor da feature correspondente.
O mapa completo: da função ao modelo de ML
Vamos conectar tudo. Quando você executa model.fit(X, y) em uma biblioteca como scikit-learn ou PyTorch, o que está acontecendo por baixo é:
- Os dados são organizados como matrizes (
 ,
,  )
) - O modelo é definido como uma função parametrizada (
 )
) - Uma função de custo mede o erro (
 )
) - Um algoritmo de otimização (como gradient descent) encontra os parâmetros
 que minimizam o custo
que minimizam o custo - As derivadas fornecem o mapa de direção para a otimização
É por isso que escolhemos funções diferenciáveis: porque precisamos calcular gradientes. É por isso que a álgebra linear importa: porque dados e parâmetros são vetores e matrizes. E é por isso que cálculo importa: porque otimização depende de derivadas.
O que estudar
Se você quer construir uma base sólida, recomendo focar em três áreas:
- Funções e geometria analítica: equação da reta, distância entre ponto e reta, funções quadráticas. A coleção do Gelson Iezzi é uma referência excelente para revisão.
- Álgebra linear: vetores, matrizes, multiplicação de matrizes, transposição, rank. Essencial para entender como dados são representados e manipulados.
- Cálculo: derivadas, derivadas parciais, regra da cadeia, gradientes. Fundamental para entender otimização e backpropagation.
Para quem quer ir direto ao ponto, o livro Mathematics for Machine Learning (Deisenroth, Faisal & Ong) conecta esses três pilares diretamente com aplicações em ML. Está disponível gratuitamente online.
Takeaways
- Dados são matrizes: cada instância é um vetor de features, o dataset completo é .
- Modelos são funções parametrizadas: o objetivo é encontrar que minimiza o erro.
- Aprender = otimizar: o gradient descent usa derivadas para navegar a superfície do erro e encontrar o mínimo.
- Três pilares: álgebra linear (dados), funções (modelos) e cálculo (aprendizado) formam o núcleo matemático de machine learning.
- Não precisa ser especialista: entender os conceitos e o intuition já te coloca muito à frente de quem apenas copia código.