Toda manipulação geométrica de uma imagem digital se resume, no fundo, a uma multiplicação de matrizes. Rotacionar, escalar, transladar, cisalhar. Cada uma dessas operações pode ser descrita como uma transformação linear aplicada às coordenadas dos pixels. Entender a matemática da visão computacional por trás dessas transformações é o que separa quem usa funções prontas do OpenCV de quem realmente entende o que está acontecendo.
Neste artigo, vamos construir passo a passo o ferramental matemático que sustenta o image warping. Partimos do problema concreto (por que matrizes 2×2 não conseguem representar translação?), derivamos a solução (coordenadas homogêneas e matrizes 3×3), e demonstramos cada transformação afim com implementação do zero em Python.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
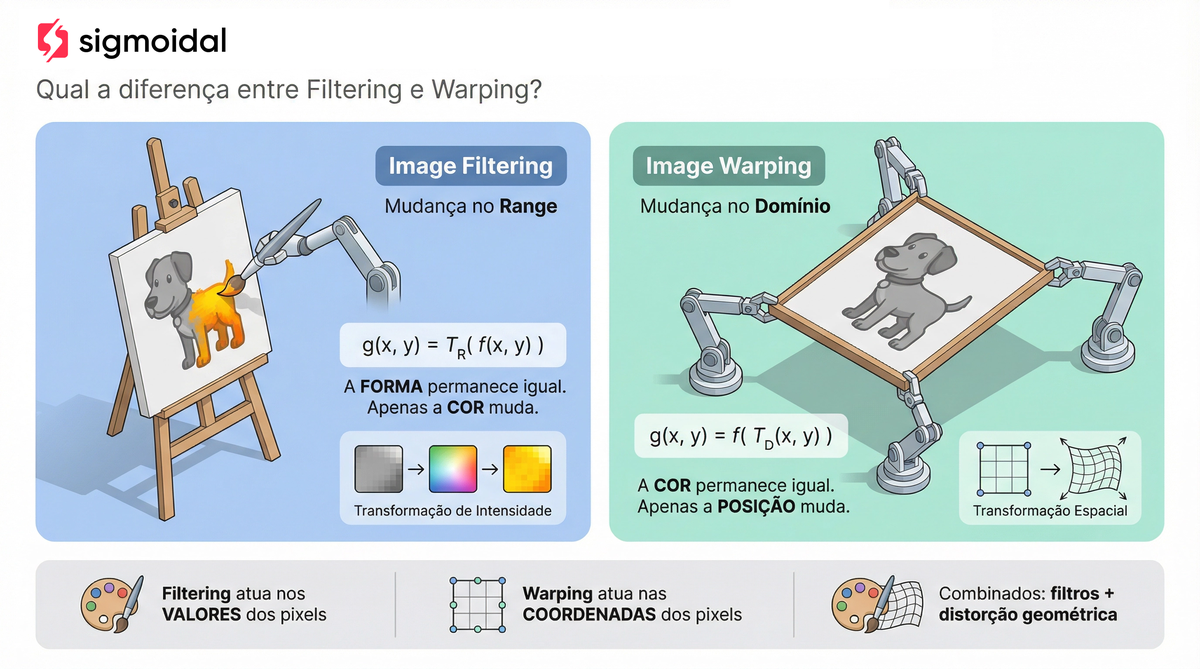
Abrir no Google Colab →Transformações de Domínio vs. Transformações de Range
Antes de entrar nas matrizes, é importante distinguir dois tipos fundamentais de operação sobre imagens.
Uma imagem digital pode ser modelada como uma função  que associa a cada par de coordenadas
que associa a cada par de coordenadas  um valor de intensidade. Quando alteramos os valores de intensidade (o range da função), estamos fazendo filtragem (image filtering). Realce de bordas, suavização, equalização de histograma: todas operam sobre
um valor de intensidade. Quando alteramos os valores de intensidade (o range da função), estamos fazendo filtragem (image filtering). Realce de bordas, suavização, equalização de histograma: todas operam sobre  sem mover os pixels de lugar.
sem mover os pixels de lugar.
Quando alteramos as coordenadas (o domínio da função), estamos fazendo deformação (image warping). A função de transformação  mapeia cada ponto para uma nova posição
mapeia cada ponto para uma nova posição  . É aqui que entram scaling, rotação, translação e cisalhamento.
. É aqui que entram scaling, rotação, translação e cisalhamento.
Este artigo trata exclusivamente de transformações de domínio. Para entender como uma imagem é formada antes de ser transformada, veja o artigo sobre os fundamentos da formação da imagem na visão computacional.
O Limite das Matrizes 2×2
Considere uma imagem como uma coleção de vetores de coordenadas. Cada pixel na posição pode ser representado como um vetor coluna. Uma transformação linear sobre esse vetor é uma multiplicação por uma matriz  de dimensão 2×2:
de dimensão 2×2:
![\[ \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} a_{11} & a_{12} \\ a_{21} & a_{22} \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-01771889fc82241c9b8dd4abcbe51702_l3.png "Rendered by QuickLaTeX.com")
Com essa estrutura, a escala funciona perfeitamente. Para expandir a imagem por um fator  na horizontal e
na horizontal e  na vertical:
na vertical:
![\[ \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} S_x & 0 \\ 0 & S_y \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-f0768657d06e6e8ea29d80b016820147_l3.png "Rendered by QuickLaTeX.com")
A rotação também cabe nessa estrutura. Para girar um ponto por um ângulo  em torno da origem, basta derivar as relações trigonométricas. Um ponto pode ser escrito em coordenadas polares como
em torno da origem, basta derivar as relações trigonométricas. Um ponto pode ser escrito em coordenadas polares como  e
e  , onde
, onde  é a distância à origem e
é a distância à origem e  é o ângulo com o eixo horizontal. Após uma rotação de , o novo ângulo é
é o ângulo com o eixo horizontal. Após uma rotação de , o novo ângulo é  :
:
![\[ x' = r\cos(\alpha + \theta) = r\cos\alpha\cos\theta - r\sin\alpha\sin\theta = x\cos\theta - y\sin\theta \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-0cf027b916b60f0dea89aebcf2217458_l3.png "Rendered by QuickLaTeX.com")
![\[ y' = r\sin(\alpha + \theta) = r\cos\alpha\sin\theta + r\sin\alpha\cos\theta = x\sin\theta + y\cos\theta \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-8eb92098f5439abeca1fc2255946a8f8_l3.png "Rendered by QuickLaTeX.com")
Em forma matricial:
![\[ \begin{bmatrix} x' \\ y' \end{bmatrix} = \begin{bmatrix} \cos\theta & -\sin\theta \\ \sin\theta & \cos\theta \end{bmatrix} \begin{bmatrix} x \\ y \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-6eb3b461572e8145e9e9bc1739d27b8b_l3.png "Rendered by QuickLaTeX.com")
Até aqui, matrizes 2×2 resolvem o problema. Mas considere agora a translação: deslocar toda a imagem por  unidades na horizontal e
unidades na horizontal e  na vertical.
na vertical.
![\[ x' = x + t_x \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-c1b06b6c727e64fdb8fee3241b52de0d_l3.png "Rendered by QuickLaTeX.com")
![\[ y' = y + t_y \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-004cd066970e55ce78405f5201dcf946_l3.png "Rendered by QuickLaTeX.com")
A pergunta é: existe uma matriz 2×2 que produza esse resultado? A resposta é não. Uma multiplicação de matriz 2×2 por um vetor sempre produz combinações lineares das componentes do vetor. O resultado será sempre da forma  . Não há como introduzir uma constante aditiva dentro desse framework. A translação não é uma transformação linear no espaço bidimensional.
. Não há como introduzir uma constante aditiva dentro desse framework. A translação não é uma transformação linear no espaço bidimensional.
Precisamos de algo a mais.
Coordenadas Homogêneas
A solução vem de uma ideia central da geometria projetiva: adicionar uma dimensão extra ao espaço de trabalho. Um ponto no plano é representado em coordenadas homogêneas como uma tripla:
![\[ \tilde{P} = (x, y, 1) \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-670c88ac5cea64c2d7a1584d88315944_l3.png "Rendered by QuickLaTeX.com")
A terceira coordenada, por convenção, vale 1. Mas a definição é mais geral: qualquer tripla  com
com  representa o mesmo ponto . Para recuperar as coordenadas cartesianas, basta dividir as duas primeiras componentes pela terceira:
representa o mesmo ponto . Para recuperar as coordenadas cartesianas, basta dividir as duas primeiras componentes pela terceira:
![\[ (x, y) = \left(\frac{\tilde{x}}{\tilde{w}}, \frac{\tilde{y}}{\tilde{w}}\right) \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-cbb8a545ed799fe369baf968f456cd5b_l3.png "Rendered by QuickLaTeX.com")
Geometricamente, imagine o plano cartesiano original posicionado na altura  de um espaço tridimensional. Qualquer reta que parta da origem e passe por um ponto desse plano define uma classe de equivalência: todos os pontos sobre essa reta (exceto a origem) representam a mesma coordenada homogênea.
de um espaço tridimensional. Qualquer reta que parta da origem e passe por um ponto desse plano define uma classe de equivalência: todos os pontos sobre essa reta (exceto a origem) representam a mesma coordenada homogênea.
Por exemplo, o ponto  se torna
se torna  em coordenadas homogêneas. Os vetores
em coordenadas homogêneas. Os vetores  ,
,  e
e  são todos equivalentes, pois divididos pela terceira coordenada retornam .
são todos equivalentes, pois divididos pela terceira coordenada retornam .
Essa “dimensão extra” pode parecer artificial, mas é exatamente o que precisamos para representar a translação como multiplicação matricial. Para quem quiser se aprofundar na teoria, Szeliski trata o tema em detalhe no capítulo 2 de Computer Vision: Algorithms and Applications.
A Matemática da Visão Computacional: As Quatro Transformações Afins
Com coordenadas homogêneas, todas as transformações básicas de imagem podem ser expressas de forma unificada como matrizes 3×3. O vetor de entrada passa a ser  e o resultado é
e o resultado é  .
.
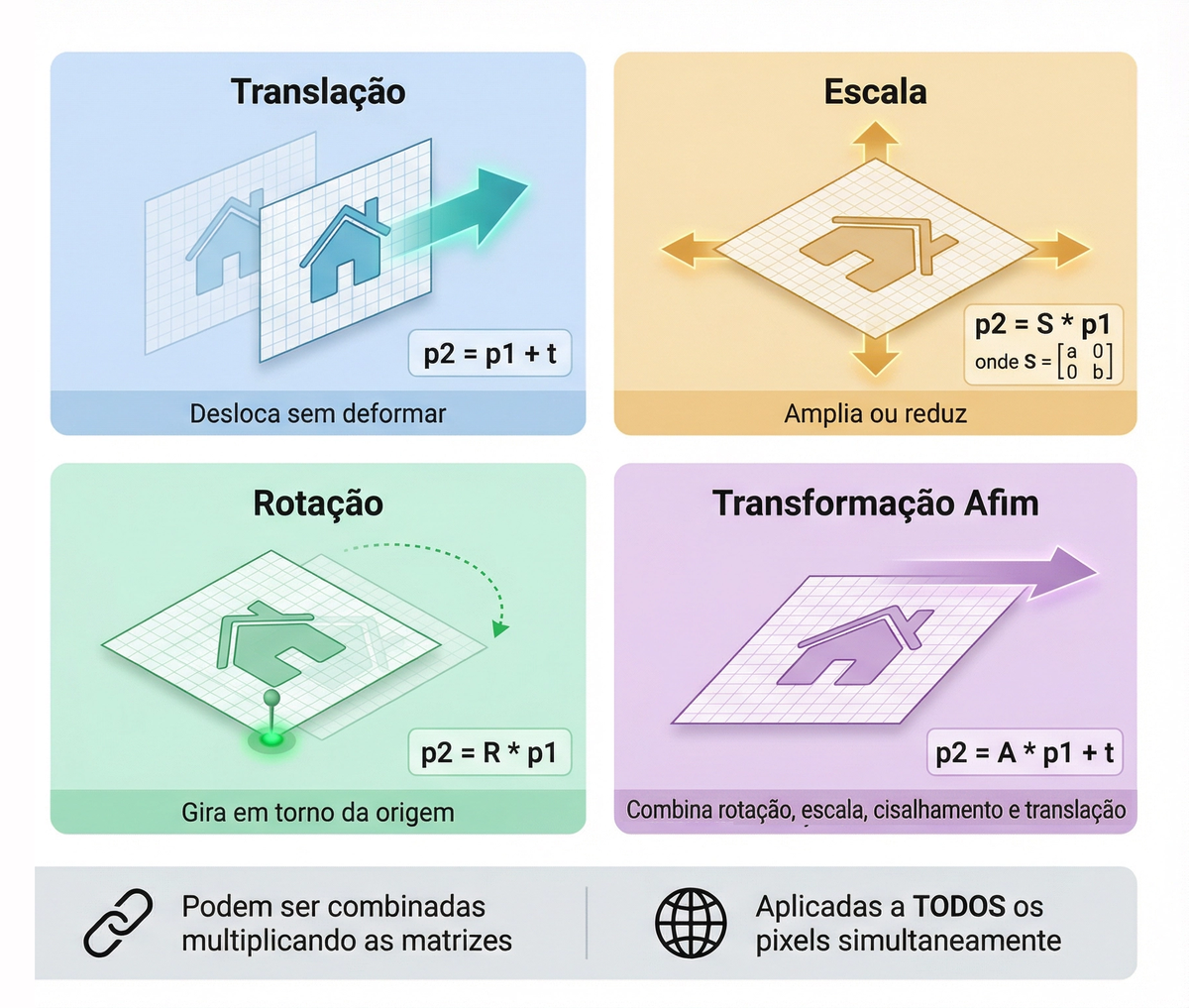
Translação
A translação, que era impossível com matrizes 2×2, agora se resolve naturalmente:
![\[ \begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} = \begin{bmatrix} 1 & 0 & t_x \\ 0 & 1 & t_y \\ 0 & 0 & 1 \end{bmatrix} \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-61ee374b079f52a466caaf0215fc6c8d_l3.png "Rendered by QuickLaTeX.com")
Fazendo a multiplicação linha a linha:  e
e  . A constante aditiva aparece porque a terceira componente do vetor é sempre 1. A última linha
. A constante aditiva aparece porque a terceira componente do vetor é sempre 1. A última linha  garante que essa componente se preserva.
garante que essa componente se preserva.
No notebook, aplicamos  e
e  sobre uma grade regular:
sobre uma grade regular:

A imagem se desloca para a direita e para baixo, sem qualquer distorção. As regiões que ficam fora do campo de visão original aparecem em preto.
Scaling (Escala)
![\[ T_{escala} = \begin{bmatrix} S_x & 0 & 0 \\ 0 & S_y & 0 \\ 0 & 0 & 1 \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-4bf0f39a2c19c96761ff63caa8f33208_l3.png "Rendered by QuickLaTeX.com")
A escala multiplica as coordenadas pelos fatores e . Com  , a imagem se expande horizontalmente. Com
, a imagem se expande horizontalmente. Com  , comprime verticalmente.
, comprime verticalmente.
Rotação
![\[ T_{rotacao} = \begin{bmatrix} \cos\theta & -\sin\theta & 0 \\ \sin\theta & \cos\theta & 0 \\ 0 & 0 & 1 \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-e6c7c3fbbf09d97ac8c10aedd01e8eb8_l3.png "Rendered by QuickLaTeX.com")
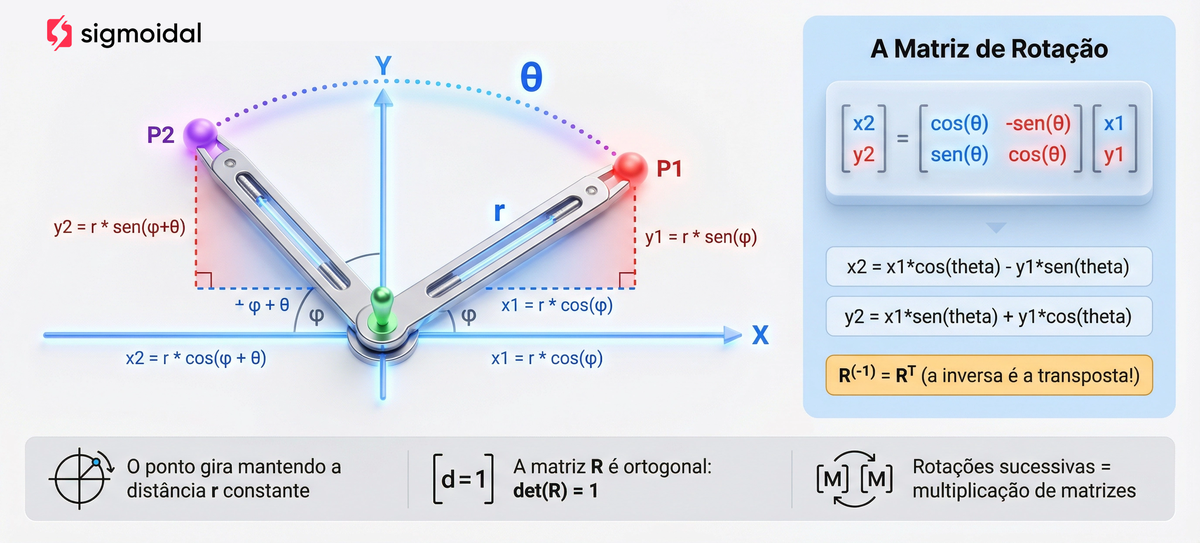
A rotação preserva distâncias e ângulos. A matriz  é ortogonal (
é ortogonal ( ) e tem determinante igual a 1. Rotações sucessivas podem ser combinadas por multiplicação de matrizes.
) e tem determinante igual a 1. Rotações sucessivas podem ser combinadas por multiplicação de matrizes.
Cisalhamento (Shear)
O cisalhamento desloca as coordenadas proporcionalmente à posição no eixo perpendicular. O cisalhamento horizontal tem fator na posição  da matriz e desloca linhas ao longo de x. O cisalhamento vertical tem fator na posição
da matriz e desloca linhas ao longo de x. O cisalhamento vertical tem fator na posição  e desloca colunas ao longo de y. Em ambos os casos, retângulos se transformam em paralelogramos, e retas paralelas permanecem paralelas.
e desloca colunas ao longo de y. Em ambos os casos, retângulos se transformam em paralelogramos, e retas paralelas permanecem paralelas.
Propriedades das Transformações Afins
Toda transformação cuja matriz 3×3 tem a última linha igual a é uma transformação afim. Essas transformações compartilham três propriedades fundamentais:
- A origem não necessariamente mapeia para a origem. A translação é o exemplo mais direto: o ponto
 vai para
vai para  .
. - Retas mapeiam para retas. Uma linha reta na imagem original continua sendo reta após a transformação. Nunca se curva.
- Retas paralelas permanecem paralelas. Duas linhas paralelas antes da transformação continuam paralelas depois. Essa propriedade é o que distingue transformações afins das projetivas (homografias), onde retas paralelas podem convergir.
Essas propriedades têm consequências práticas diretas. Se você aplica uma transformação afim a uma imagem contendo um retângulo, o resultado será no máximo um paralelogramo. Se o resultado for um trapézio (lados não paralelos), a transformação não é afim.
Para uma exploração aprofundada de transformações projetivas e do modelo de câmera pinhole, veja o artigo sobre a geometria da formação de imagens e matrizes de transformação.
Composição de Transformações
Uma das maiores vantagens de representar todas as transformações como matrizes 3×3 é a possibilidade de compor operações por multiplicação matricial. Se você precisa aplicar uma escala seguida de uma rotação, basta multiplicar as duas matrizes:
![\[ T_{composta} = T_{rotacao} \cdot T_{escala} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-f51b760c94c4ad11428c91a7b5c23c18_l3.png "Rendered by QuickLaTeX.com")
A ordem de leitura é da direita para a esquerda: primeiro aplica-se  , depois
, depois  . A multiplicação de matrizes não é comutativa. Trocar a ordem produz um resultado diferente.
. A multiplicação de matrizes não é comutativa. Trocar a ordem produz um resultado diferente.

Computacionalmente, isso é muito eficiente. Em vez de percorrer todos os pixels da imagem múltiplas vezes (uma para cada operação), você calcula a matriz composta uma única vez e faz uma única passagem.
Rotação em torno de um ponto arbitrário
A composição resolve um problema prático importante. A rotação padrão gira em torno da origem , que na imagem corresponde ao canto superior esquerdo. Para girar em torno do centro da imagem, compomos três operações:
- Transladar o centro da imagem para a origem
- Aplicar a rotação
- Transladar de volta
![\[ T = T_{+centro} \cdot T_{rotacao} \cdot T_{-centro} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-f46618bf627b0af54bb3ce22ff796d1a_l3.png "Rendered by QuickLaTeX.com")
O resultado é uma única matriz 3×3 que executa as três operações de uma só vez:
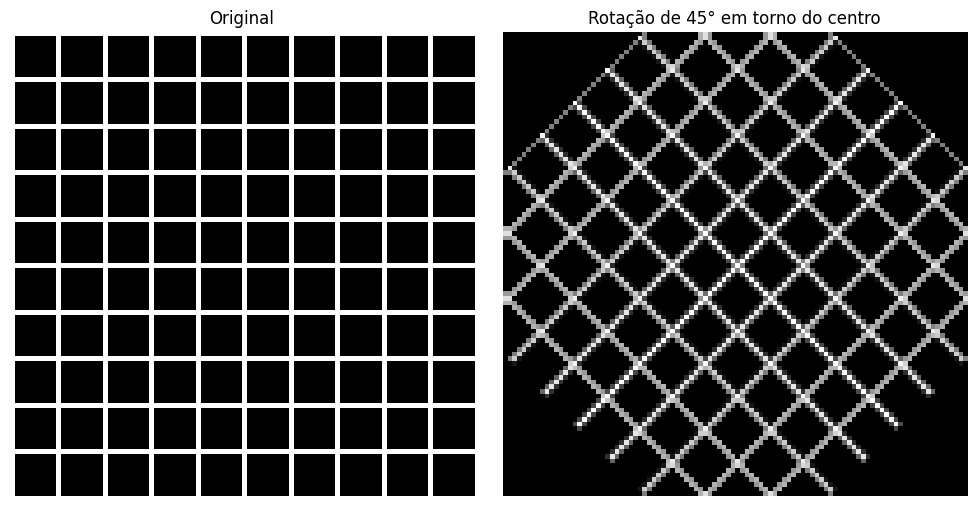
Compare com a rotação simples (em torno da origem) mostrada anteriormente. Aqui a imagem gira sobre si mesma, sem deslocar.
Mapeamento Inverso e Interpolação
Na implementação, há uma decisão técnica importante. O mapeamento direto percorre cada pixel da imagem original e calcula onde ele deve ir na imagem de saída. O problema é que isso gera buracos: dois pixels podem mapear para o mesmo destino (sobreposição), e algumas posições da saída podem não receber nenhum pixel.
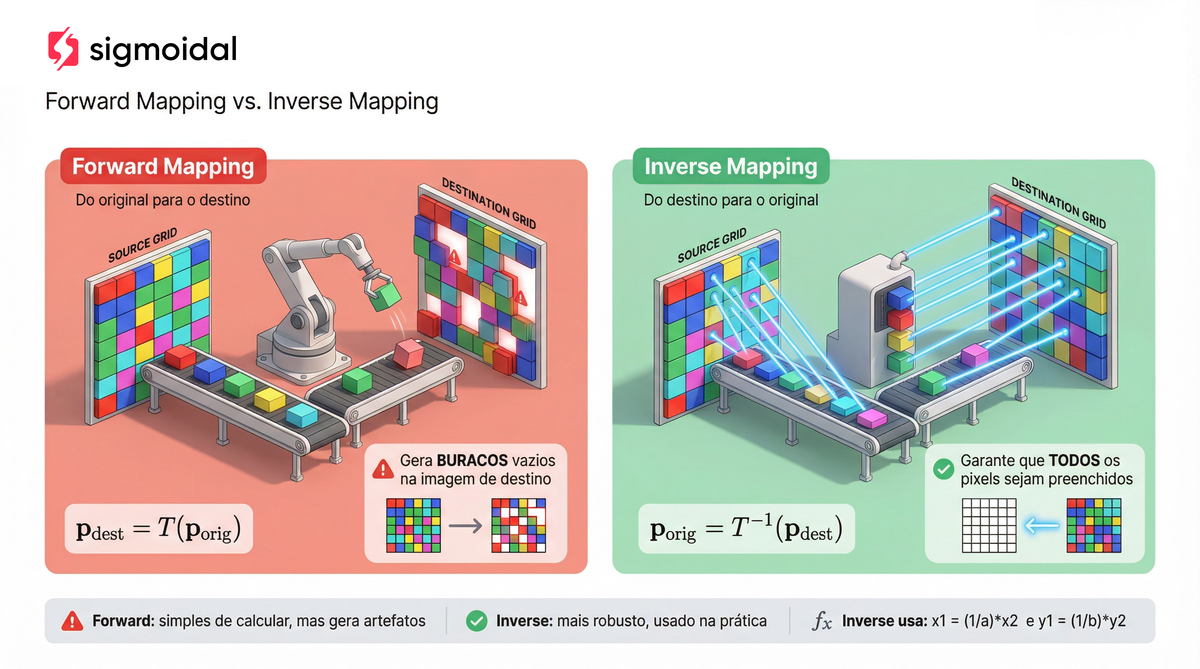
O mapeamento inverso resolve isso. Para cada pixel da imagem de saída, calcula-se a posição correspondente na imagem original usando a inversa da transformação:
![\[ \begin{bmatrix} x \\ y \\ 1 \end{bmatrix} = T^{-1} \begin{bmatrix} x' \\ y' \\ 1 \end{bmatrix} \]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-bf68e45fcb5c3ceaa30af68925f40f16_l3.png "Rendered by QuickLaTeX.com")
Como a posição resultante pode ter coordenadas fracionárias (um pixel da saída pode corresponder a um ponto “entre” pixels na entrada), precisamos de um método de interpolação.
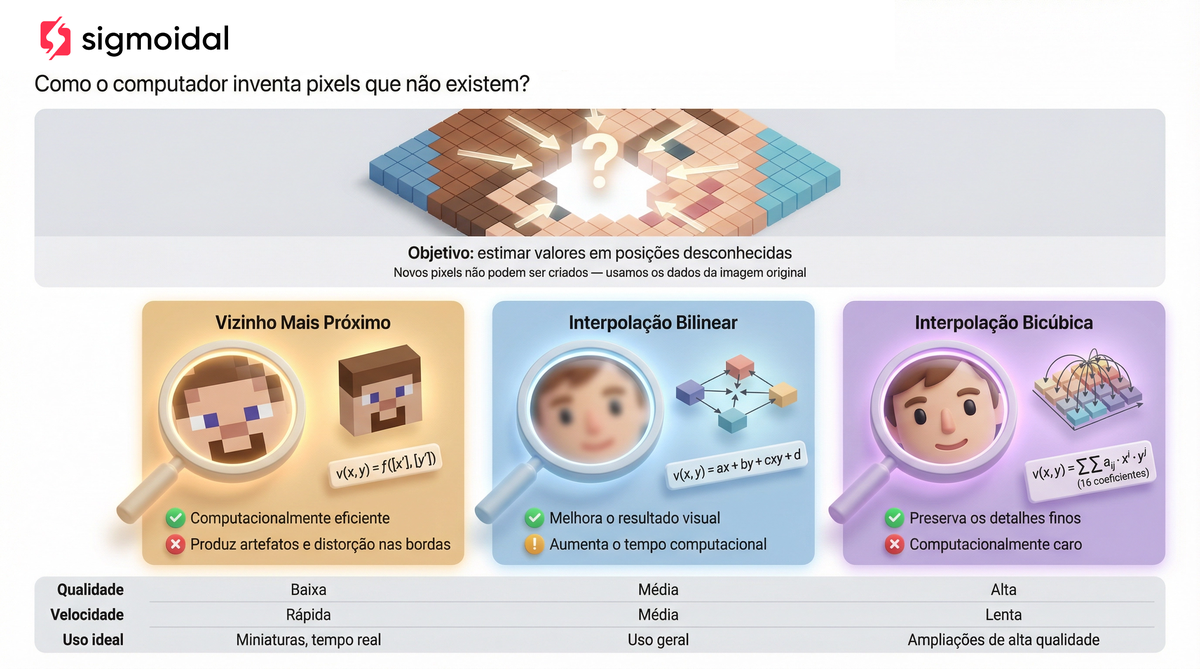
A interpolação por vizinho mais próximo arredonda para o pixel inteiro mais perto. É rápida, mas produz bordas serrilhadas. A interpolação bilinear pondera os quatro vizinhos mais próximos usando as distâncias fracionárias como pesos, produzindo transições mais suaves. A interpolação bicúbica pondera uma vizinhança de 4×4 pixels e preserva melhor os detalhes finos, ao custo de maior processamento.
Essas mesmas transformações matriciais são a base da calibração de câmeras com OpenCV e Python, onde os parâmetros intrínsecos e extrínsecos da câmera são representados como matrizes que convertem coordenadas do mundo real para coordenadas de pixel.
Takeaways
- Matrizes 2×2 representam scaling e rotação, mas não translação. A translação exige somar uma constante, o que foge do escopo da multiplicação matricial em duas dimensões.
- Coordenadas homogêneas resolvem essa limitação. Ao adicionar uma terceira coordenada (sempre igual a 1), a translação se torna uma multiplicação por uma matriz 3×3.
- Toda transformação afim tem última linha . Isso garante que retas mapeiam para retas e paralelas permanecem paralelas.
- Composição de transformações é multiplicação de matrizes. Isso permite combinar múltiplas operações em uma única matriz, com uma única passagem pelos pixels.
- Mapeamento inverso evita buracos na imagem de saída. Combinado com interpolação bilinear, produz resultados suaves sem artefatos de aliasing.