Você já tentou aprender PyTorch e ficou perdido entre tensores, autograd, DataLoaders e camadas convolucionais?
Neste tutorial de introdução ao PyTorch, vamos percorrer o caminho completo para treinar uma Rede Neural Convolucional do zero. Você vai entender cada peça do quebra-cabeça, desde a criação de tensores até a avaliação do modelo no conjunto de teste. Ao final, terá uma CNN treinada no CIFAR-10, capaz de classificar imagens em 10 categorias diferentes.
Se você quer entender a teoria por trás de tudo isso, com a fundamentação completa de Deep Learning e Visão Computacional, assista à aula gratuita de mais de 5 horas no YouTube. Aqui, vamos focar na parte prática.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →O Que São Tensores?
Tensores são a estrutura de dados fundamental do PyTorch. Pense neles como arrays do NumPy com dois superpoderes: rodam em GPU e suportam diferenciação automática. Se você já trabalhou com NumPy, vai se sentir em casa.
Existem várias formas de criar tensores. As mais comuns são a partir de listas Python, com valores aleatórios, ou preenchidos com zeros e uns.
import torch # A partir de uma lista t1 = torch.tensor([1, 2, 3, 4]) print(t1)
tensor([1, 2, 3, 4])
Você pode criar tensores preenchidos com zeros, uns ou valores aleatórios, exatamente como faria com np.zeros, np.ones e np.random.rand.
zeros = torch.zeros(3, 4) uns = torch.ones(3, 4) aleatorio = torch.rand(3, 4)
Todo tensor tem um shape (dimensões) e um dtype (tipo de dado). Podemos redimensionar com reshape ou view.
t = torch.rand(2, 3, 4)
print("Shape:", t.shape) # torch.Size([2, 3, 4])
print("Dtype:", t.dtype) # torch.float32
print("Dimensões:", t.ndim) # 3
print("Elementos:", t.numel()) # 24
A indexação funciona como no NumPy. Você acessa elementos, linhas, colunas e fatias da mesma forma.
t = torch.arange(12).reshape(3, 4) print(t[1, 2]) # elemento na posição [1, 2] print(t[0]) # primeira linha print(t[:, 1]) # segunda coluna print(t[0:2, 1:3]) # submatriz
PyTorch suporta todas as operações que você espera: soma, multiplicação elemento a elemento, potência e multiplicação matricial com o operador @.
a = torch.tensor([1.0, 2.0, 3.0])
b = torch.tensor([4.0, 5.0, 6.0])
print("Soma:", a + b)
print("Produto escalar:", torch.dot(a, b))
# Multiplicação matricial
A = torch.rand(2, 3)
B = torch.rand(3, 4)
C = A @ B # equivalente a torch.matmul(A, B)
Se houver uma GPU disponível, basta mover o tensor com .to(device). Lembre-se de que operações entre tensores exigem que ambos estejam no mesmo device.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
t_gpu = t.to(device)
O Que É Autograd?
O autograd é o motor de diferenciação automática do PyTorch. Ele rastreia todas as operações feitas em tensores com requires_grad=True e, ao chamar .backward(), calcula os gradientes automaticamente. É isso que torna possível treinar redes neurais.
x = torch.tensor(3.0, requires_grad=True)
y = x ** 2 + 2 * x + 1 # y = x² + 2x + 1
y.backward() # dy/dx = 2x + 2
print("dy/dx =", x.grad.item()) # 2*3 + 2 = 8
dy/dx = 8.0
O gradiente foi calculado automaticamente. Para $y = x^2 + 2x + 1$, a derivada é $\frac{dy}{dx} = 2x + 2$. Substituindo $x = 3$, temos $8$. Exatamente o que o PyTorch retornou.
Regressão Linear na Mão
Para consolidar o conceito, vamos treinar uma regressão linear do zero usando apenas tensores e autograd. Isso mostra exatamente o que acontece dentro de qualquer loop de treino: forward pass, cálculo da loss, backward e atualização dos pesos.
Começamos gerando dados sintéticos que seguem a relação $y = 3x + 1$ com um pouco de ruído.
torch.manual_seed(42) X = torch.rand(100, 1) * 10 y_true = 3 * X + 1 + torch.randn(100, 1) * 0.5
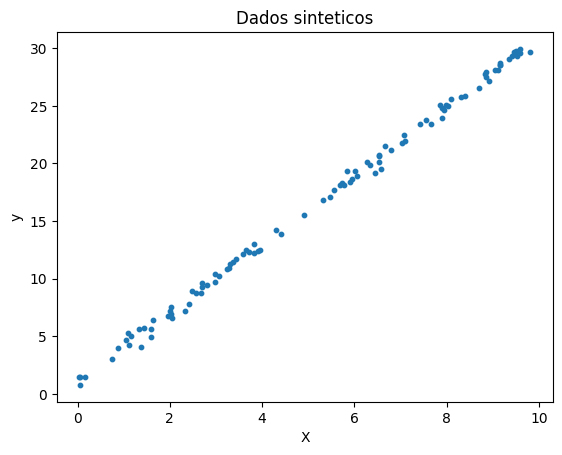
Agora, o loop de treino. Inicializamos os parâmetros $w$ e $b$ com zero e iteramos 100 vezes, atualizando os pesos na direção oposta ao gradiente.
w = torch.tensor(0.0, requires_grad=True)
b = torch.tensor(0.0, requires_grad=True)
lr = 0.01
for epoch in range(100):
y_pred = w * X + b # Forward
loss = ((y_pred - y_true) ** 2).mean() # MSE Loss
loss.backward() # Backward
with torch.no_grad(): # Atualização
w -= lr * w.grad
b -= lr * b.grad
w.grad.zero_()
b.grad.zero_()
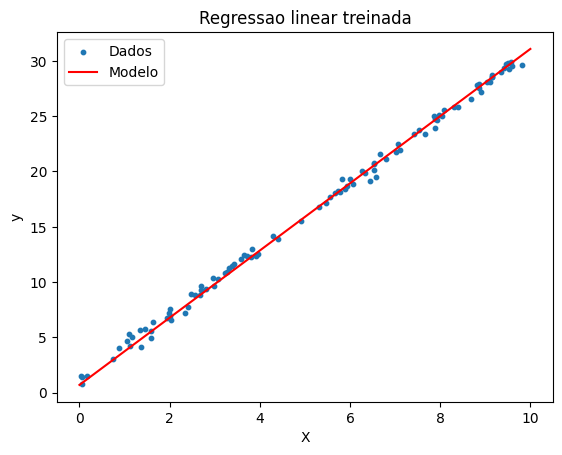
w final: 3.0374 (esperado: 3.0) b final: 0.7055 (esperado: 1.0)
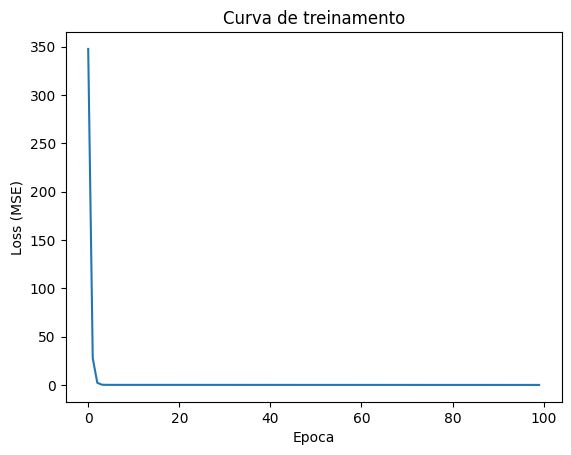
A loss caiu rapidamente e os parâmetros convergiram para valores próximos dos reais. Observe que o padrão forward, loss, backward, update, zero_grad é o mesmo que usaremos para treinar a CNN. A diferença é que, em vez de uma reta, teremos milhares de parâmetros.
Como Carregar Dados com DataLoader?
Para treinar redes neurais, precisamos carregar dados de forma eficiente. O PyTorch oferece o torchvision com datasets prontos e o DataLoader para iterar sobre os dados em batches.
Vamos usar o CIFAR-10, que contém 60.000 imagens coloridas de 32×32 pixels divididas em 10 classes: avião, automóvel, pássaro, gato, cervo, cachorro, sapo, cavalo, navio e caminhão.
import torchvision
import torchvision.transforms as transforms
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))
])
train_dataset = torchvision.datasets.CIFAR10(
root="./data", train=True, download=True, transform=transform
)
test_dataset = torchvision.datasets.CIFAR10(
root="./data", train=False, download=True, transform=transform
)
Treino: 50000 imagens Teste: 10000 imagens Classes: ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck']
O DataLoader organiza os dados em batches e permite embaralhar. Cada iteração retorna um lote de imagens e seus labels.
from torch.utils.data import DataLoader train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True) test_loader = DataLoader(test_dataset, batch_size=64, shuffle=False)
Ao inspecionar um batch, vemos que as imagens têm shape [64, 3, 32, 32], ou seja, 64 imagens com 3 canais (RGB) de 32×32 pixels.

Como Construir uma CNN com PyTorch?
Uma Rede Neural Convolucional extrai features espaciais da imagem através de filtros (convoluções), reduz progressivamente a resolução com pooling e passa por camadas fully connected para classificação.
Versão mínima
Vamos começar com a CNN mais simples possível: uma camada convolucional, um pooling e uma camada fully connected.
import torch.nn as nn
class CNNSimples(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1)
self.pool = nn.MaxPool2d(2, 2)
self.fc1 = nn.Linear(16 * 16 * 16, 10)
def forward(self, x):
x = self.pool(torch.relu(self.conv1(x)))
x = x.view(x.size(0), -1)
x = self.fc1(x)
return x
Vale a pena acompanhar como o tensor muda de shape conforme passa pelas camadas. Esse entendimento é fundamental para construir arquiteturas mais complexas.
Entrada: [4, 3, 32, 32] Após Conv2d(3, 16, 3, padding=1): [4, 16, 32, 32] Após ReLU + MaxPool2d(2): [4, 16, 16, 16] Após flatten: [4, 4096] Após Linear: [4, 10]
A imagem entra com 3 canais e 32×32. A convolução gera 16 feature maps mantendo a resolução (graças ao padding=1). O pooling reduz pela metade. O flatten transforma em vetor. A camada linear classifica em 10 classes.
Versão melhorada
Para obter resultados melhores, vamos adicionar mais camadas convolucionais, BatchNorm para estabilizar o treino e Dropout para regularização.
class CNNMelhorada(nn.Module):
def __init__(self):
super().__init__()
# Bloco 1
self.conv1 = nn.Conv2d(3, 32, kernel_size=3, padding=1)
self.bn1 = nn.BatchNorm2d(32)
self.conv2 = nn.Conv2d(32, 32, kernel_size=3, padding=1)
self.bn2 = nn.BatchNorm2d(32)
self.pool1 = nn.MaxPool2d(2, 2)
self.drop1 = nn.Dropout(0.25)
# Bloco 2
self.conv3 = nn.Conv2d(32, 64, kernel_size=3, padding=1)
self.bn3 = nn.BatchNorm2d(64)
self.conv4 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn4 = nn.BatchNorm2d(64)
self.pool2 = nn.MaxPool2d(2, 2)
self.drop2 = nn.Dropout(0.25)
# Classificador
self.fc1 = nn.Linear(64 * 8 * 8, 128)
self.drop3 = nn.Dropout(0.5)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = torch.relu(self.bn1(self.conv1(x)))
x = torch.relu(self.bn2(self.conv2(x)))
x = self.drop1(self.pool1(x))
x = torch.relu(self.bn3(self.conv3(x)))
x = torch.relu(self.bn4(self.conv4(x)))
x = self.drop2(self.pool2(x))
x = x.view(x.size(0), -1)
x = torch.relu(self.fc1(x))
x = self.drop3(x)
x = self.fc2(x)
return x
A arquitetura segue um padrão clássico: dois blocos convolucionais (cada um com duas convoluções, BatchNorm, ReLU, pooling e dropout), seguidos de um classificador com camada oculta. São 591.658 parâmetros treináveis.
Como Treinar a CNN?
O loop de treino segue o mesmo padrão da regressão linear, só que agora com um modelo mais complexo, CrossEntropyLoss como função de perda e o otimizador Adam.
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = CNNMelhorada().to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
for epoch in range(10):
model.train()
running_loss = 0.0
for images, labels in train_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images) # Forward
loss = criterion(outputs, labels)
optimizer.zero_grad() # Zerar gradientes
loss.backward() # Backward
optimizer.step() # Atualizar pesos
running_loss += loss.item()
avg_loss = running_loss / len(train_loader)
print(f"Época {epoch+1}/10 - Loss: {avg_loss:.4f}")
Época 1/10 - Loss: 1.6498 Época 2/10 - Loss: 1.3698 Época 3/10 - Loss: 1.2456 Época 4/10 - Loss: 1.1759 Época 5/10 - Loss: 1.1233 Época 6/10 - Loss: 1.0854 Época 7/10 - Loss: 1.0506 Época 8/10 - Loss: 1.0261 Época 9/10 - Loss: 0.9991 Época 10/10 - Loss: 0.9746
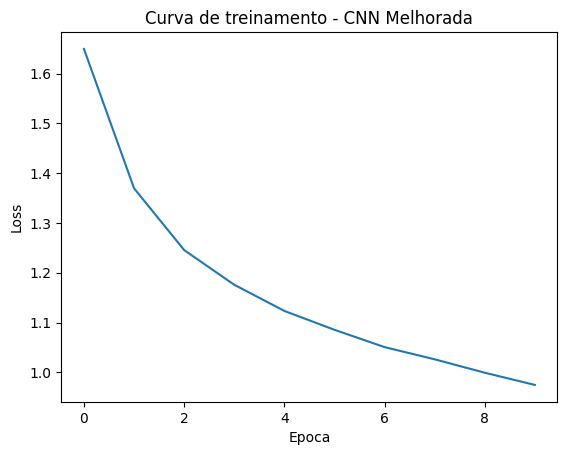
A loss caiu de forma consistente ao longo das 10 épocas, indicando que o modelo está aprendendo.
Avaliação no Conjunto de Teste
Treinar é uma coisa. O que realmente importa é o desempenho em dados que o modelo nunca viu. Para avaliar, colocamos o modelo em modo de avaliação com model.eval() e desativamos o cálculo de gradientes com torch.no_grad().
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
accuracy = 100 * correct / total
print(f"Acurácia no teste: {accuracy:.2f}%")
Acurácia no teste: 74.13%
Com apenas 10 épocas e sem nenhum data augmentation, já atingimos 74% de acurácia. Para o CIFAR-10, que tem imagens pequenas (32×32) e bastante variação dentro de cada classe, esse é um resultado sólido para uma primeira CNN.

Na visualização acima, as predições corretas aparecem em verde e as erradas em vermelho. O modelo acerta com confiança em classes como automobile, ship e truck, mas confunde mais em cat e dog, o que faz sentido dada a similaridade visual entre esses animais. Se quiser entender exatamente o que a rede está “olhando” para tomar essas decisões, veja o artigo sobre Grad-CAM.
Acurácia por classe
Ao quebrar a acurácia por classe, fica claro onde o modelo se destaca e onde tem dificuldade.
airplane: 81.7%
automobile: 88.1%
bird: 65.1%
cat: 52.7%
deer: 60.8%
dog: 54.7%
frog: 86.8%
horse: 74.6%
ship: 87.5%
truck: 89.3%
Truck (89.3%) e automobile (88.1%) são as classes mais fáceis, provavelmente por terem formas geométricas distintas. Cat (52.7%) e dog (54.7%) são as mais difíceis. Melhorar esses números é possível com *data augmentation*, arquiteturas mais profundas ou transfer learning.
Quer Ir Além? Conheça o Bootcamp de Deep Learning e Visão Computacional
Este tutorial que você acabou de ler é o conteúdo prático da primeira aula do Bootcamp de Deep Learning e Visão Computacional.

Mas se você quer ir além dos fundamentos e aprender a construir projetos reais de ponta a ponta, o Bootcamp cobre desde os conceitos que você viu aqui até arquiteturas avançadas e um projeto final completo. É o caminho mais direto para quem quer dominar Deep Learning aplicado a imagens na prática.
Takeaways
- Tensores são a base de tudo no PyTorch. Funcionam como arrays NumPy, mas com suporte a GPU e diferenciação automática.
- Autograd calcula gradientes automaticamente com
.backward(). O padrão forward, loss, backward, update, zero_grad é o mesmo para qualquer modelo. - DataLoader organiza dados em batches para treino eficiente. O
torchvisionoferece datasets prontos como o CIFAR-10. - CNNs extraem features espaciais com convoluções e pooling antes de classificar. Adicionar BatchNorm e Dropout melhora significativamente o resultado.
- 74% de acurácia com 10 épocas e sem data augmentation é um ponto de partida sólido. Para ir além, explore transfer learning com PyTorch.