E se você pudesse transformar um conjunto de fotos comuns em uma cena 3D fotorrealista, navegável em tempo real, usando apenas Python e uma GPU? É exatamente o que o Gaussian Splatting faz, e neste artigo você vai entender cada detalhe de como essa técnica funciona.
Publicado em 2023 por Kerbl et al. (SIGGRAPH 2023), o paper “3D Gaussian Splatting for Real-Time Radiance Field Rendering” acumulou mais de 6.000 citações em menos de três anos. A razão é simples: pela primeira vez, temos uma representação 3D que combina qualidade fotorrealista com renderização acima de 100 FPS. Isso muda tudo para realidade virtual, digital twins, simulação de direção autônoma e cinema.
Neste guia, você vai aprender a teoria por trás do Gaussian Splatting, entender como cada componente funciona matematicamente, e implementar um pipeline prático com o LGM (Large Gaussian Model) que gera modelos 3D a partir de uma única foto, usando Python no Google Colab.
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Por Que Precisamos de Novas Representações 3D?
A reconstrução 3D a partir de imagens 2D é um dos problemas mais antigos da visão computacional. Técnicas clássicas como Structure from Motion (SfM) e nuvens de pontos já permitem extrair geometria 3D a partir de múltiplas fotos. Porém, o resultado costuma ser uma nuvem de pontos esparsa, sem cor realista e sem capacidade de renderizar novas vistas de forma convincente.
Em 2020, os Neural Radiance Fields (NeRFs) revolucionaram a área ao representar cenas 3D como redes neurais implícitas. A ideia é elegante: uma rede neural recebe a posição  e a direção de visão
e a direção de visão  como entrada e retorna a cor e a densidade naquele ponto do espaço. Para renderizar uma imagem, você dispara raios pela cena e consulta a rede neural centenas de vezes ao longo de cada raio.
como entrada e retorna a cor e a densidade naquele ponto do espaço. Para renderizar uma imagem, você dispara raios pela cena e consulta a rede neural centenas de vezes ao longo de cada raio.
O problema? Renderizar um único frame com NeRF leva cerca de 1 segundo. Isso o torna inviável para aplicações interativas como realidade virtual, jogos ou navegação em tempo real.
O Gaussian Splatting resolve esse gargalo com uma mudança de paradigma: em vez de uma representação neural implícita (onde a cena vive “dentro” de uma rede neural), ele usa uma representação explícita baseada em milhões de gaussianas 3D posicionadas no espaço. O resultado é uma renderização até 1000 vezes mais rápida que o NeRF, sem perda significativa de qualidade.
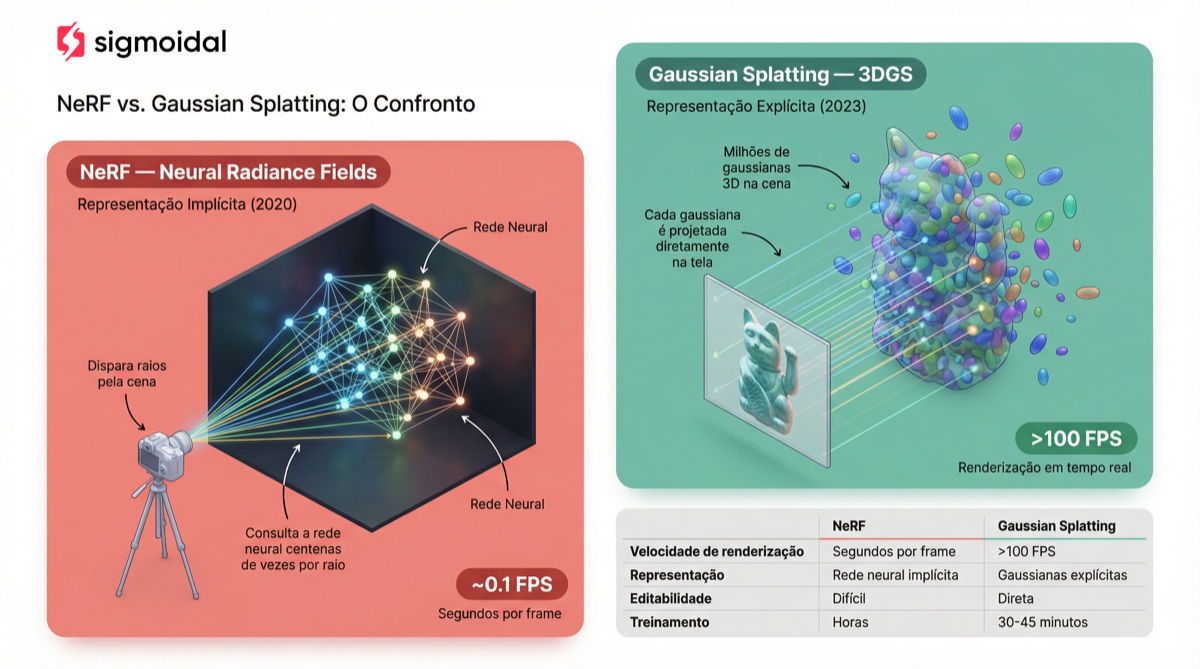
O Que São Gaussianas 3D?
Pense em nuvenzinhas semitransparentes flutuando no espaço. Cada uma tem uma posição, um tamanho, uma orientação, uma cor e um nível de transparência. Se você empilhar milhões dessas nuvenzinhas com os parâmetros certos, elas se sobrepõem e formam uma cena 3D fotorrealista. Essa é a intuição por trás do Gaussian Splatting.
Formalmente, cada gaussiana 3D é definida pela função:
![\[G(\mathbf{x}) = e^{-\frac{1}{2}(\mathbf{x} - \boldsymbol{\mu})^T \boldsymbol{\Sigma}^{-1} (\mathbf{x} - \boldsymbol{\mu})}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-1629550e79e5d59b1afe75aaa5d69b39_l3.png "Rendered by QuickLaTeX.com")
Onde  é o centro (posição) da gaussiana e
é o centro (posição) da gaussiana e  é a matriz de covariância
é a matriz de covariância  que define sua forma e orientação no espaço.
que define sua forma e orientação no espaço.
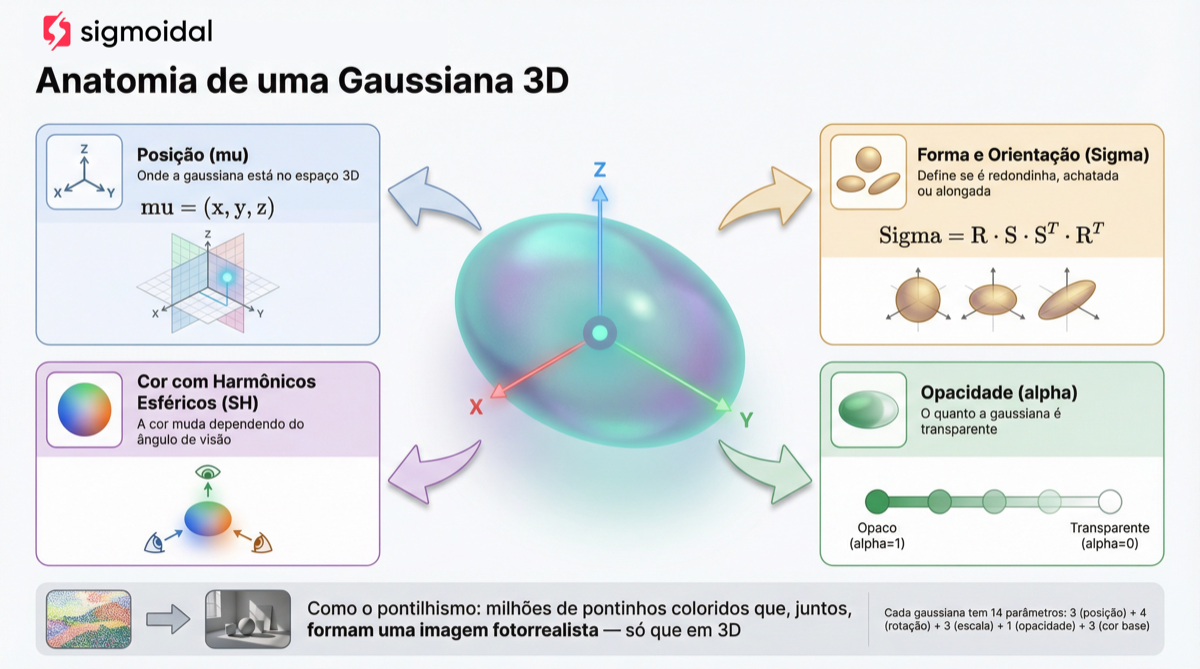
Os 14 Parâmetros de Cada Gaussiana
Na versão com harmônicos esféricos de grau 0 (que é a usada pelo LGM), cada gaussiana carrega 14 parâmetros fundamentais:
| Parâmetro | Quantidade | Descrição |
|---|---|---|
| Posição |
3 | Centro da gaussiana no espaço 3D |
Escala  |
3 | Tamanho ao longo de cada eixo |
Rotação  |
4 | Quaternion que define a orientação |
Cor (SH)  |
3 | Coeficientes de harmônicos esféricos (RGB) |
Opacidade  |
1 | Nível de transparência (0 = invisível, 1 = opaco) |
A matriz de covariância não é armazenada diretamente. Ela é reconstruída a partir da escala  e da rotação
e da rotação  :
:
![\[\boldsymbol{\Sigma} = R \cdot S \cdot S^T \cdot R^T\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-e8a9ac5351c2618817f62d00fea32b7a_l3.png "Rendered by QuickLaTeX.com")
Onde  é a matriz de rotação (derivada do quaternion) e
é a matriz de rotação (derivada do quaternion) e  é a matriz diagonal de escala. Essa decomposição garante que seja sempre semidefinida positiva, condição necessária para que a gaussiana represente uma distribuição válida.
é a matriz diagonal de escala. Essa decomposição garante que seja sempre semidefinida positiva, condição necessária para que a gaussiana represente uma distribuição válida.
A cor usa harmônicos esféricos (spherical harmonics), uma técnica que permite representar variações de cor dependentes do ângulo de visão. Na versão simplificada (grau 0), cada gaussiana armazena apenas 3 coeficientes (um por canal RGB), convertidos para cor final pela fórmula:
![\[\text{cor} = 0.5 + C_0 \cdot c_i\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-7ddbd012c0e4395477f219db2803d403_l3.png "Rendered by QuickLaTeX.com")
Onde  é o coeficiente base dos harmônicos esféricos. Versões com harmônicos de grau mais alto capturam reflexos especulares e variações complexas de iluminação.
é o coeficiente base dos harmônicos esféricos. Versões com harmônicos de grau mais alto capturam reflexos especulares e variações complexas de iluminação.
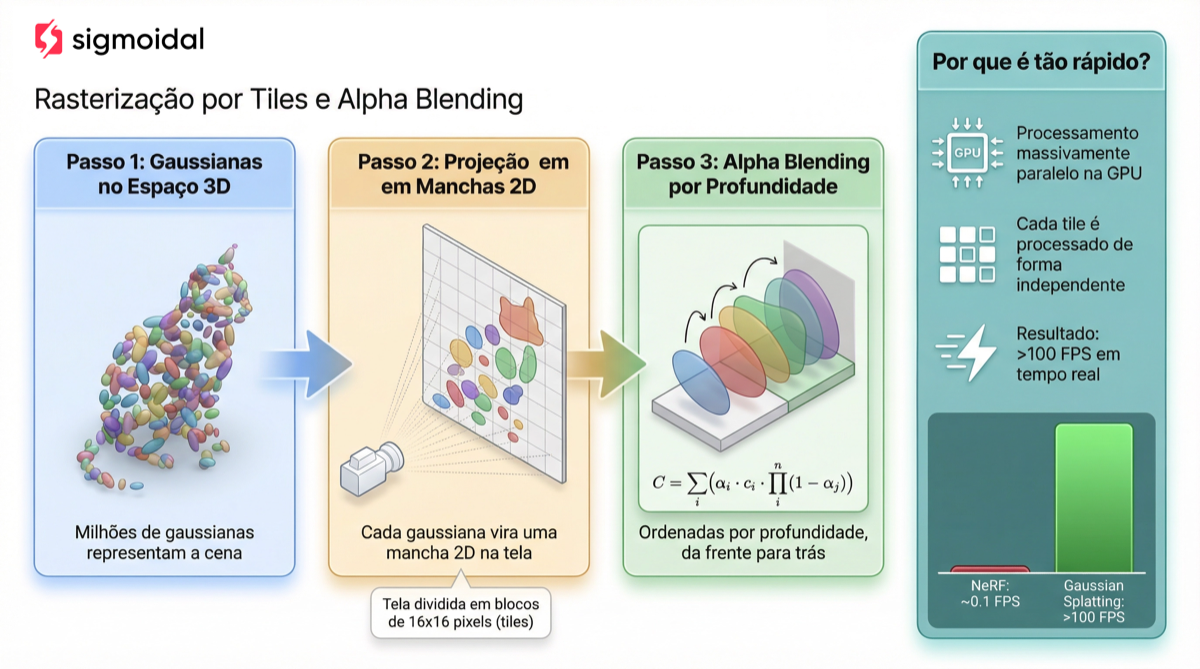
Como Funciona a Renderização no Gaussian Splatting?
A grande inovação do Gaussian Splatting está no processo de renderização. Enquanto o NeRF precisa consultar uma rede neural centenas de vezes por pixel (ray marching), o Gaussian Splatting usa rasterização, uma abordagem fundamentalmente diferente e muito mais eficiente.
Passo 1: Projeção 2D (Splatting)
Cada gaussiana 3D é projetada no plano da câmera, gerando uma “mancha” 2D (splat). A projeção transforma a gaussiana 3D em uma gaussiana 2D no espaço da tela:
![\[\boldsymbol{\Sigma}' = J \cdot W \cdot \boldsymbol{\Sigma} \cdot W^T \cdot J^T\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-8032d4d94349782e884ad2b35f0b0264_l3.png "Rendered by QuickLaTeX.com")
Onde  é a matriz de transformação da câmera (world-to-camera) e
é a matriz de transformação da câmera (world-to-camera) e  é o jacobiano da projeção perspectiva. O resultado
é o jacobiano da projeção perspectiva. O resultado  é a covariância 2D que define o formato da mancha na tela.
é a covariância 2D que define o formato da mancha na tela.
Passo 2: Tile-Based Rendering
A imagem é dividida em blocos (tiles) de  pixels. Cada tile mantém uma lista das gaussianas que o afetam, ordenadas por profundidade (distância da câmera). Essa organização em tiles é o que permite a paralelização massiva na GPU: cada tile é processado independentemente por um thread block do CUDA.
pixels. Cada tile mantém uma lista das gaussianas que o afetam, ordenadas por profundidade (distância da câmera). Essa organização em tiles é o que permite a paralelização massiva na GPU: cada tile é processado independentemente por um thread block do CUDA.
Passo 3: Alpha Blending por Profundidade
Para cada pixel dentro de um tile, as gaussianas são compostas da frente para o fundo usando alpha blending:
![\[C = \sum_{i=1}^{N} c_i \cdot \alpha_i \cdot T_i, \quad T_i = \prod_{j=1}^{i-1}(1 - \alpha_j)\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-4084887b4bcb8aee38d6e19c9d9e2ff6_l3.png "Rendered by QuickLaTeX.com")
Onde  é a cor da gaussiana
é a cor da gaussiana  ,
,  é sua opacidade efetiva (que depende da opacidade original e da distância ao centro da mancha), e
é sua opacidade efetiva (que depende da opacidade original e da distância ao centro da mancha), e  é a transmitância acumulada. Quando a transmitância cai abaixo de um limiar (tipicamente 0.0001), o pixel para de acumular, economizando cálculos.
é a transmitância acumulada. Quando a transmitância cai abaixo de um limiar (tipicamente 0.0001), o pixel para de acumular, economizando cálculos.
Essa combinação de rasterização por tiles, ordenação por profundidade e composição paralela na GPU é o que entrega mais de 100 FPS em resolução Full HD.
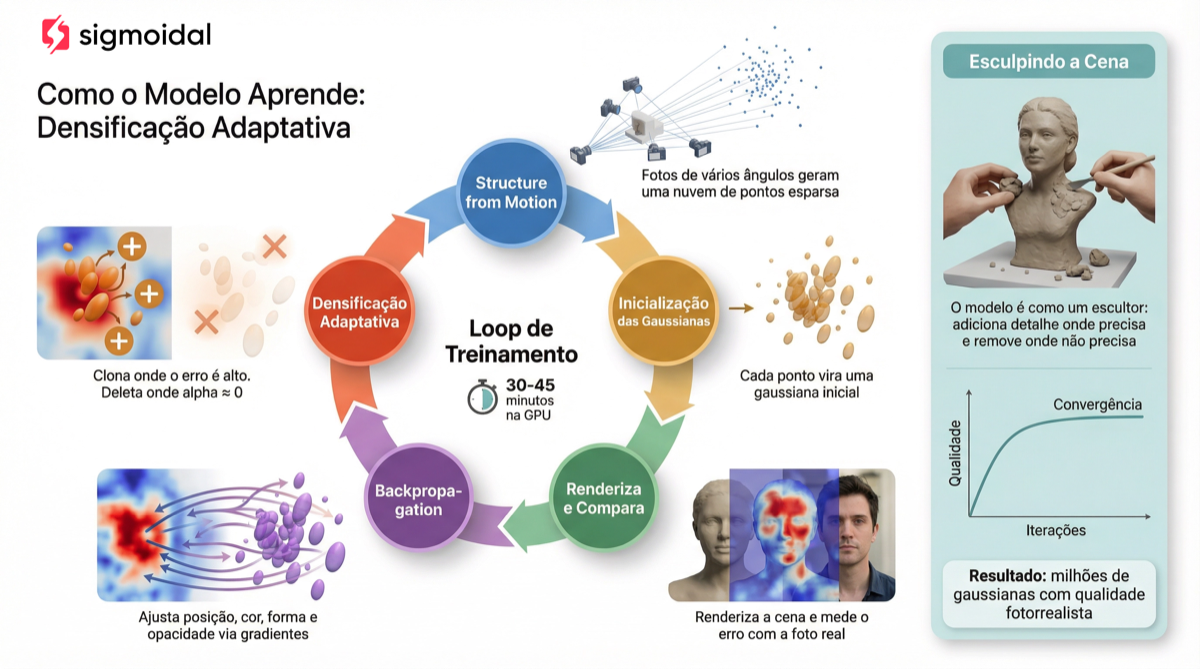
Como o Modelo Aprende? Treinamento e Densificação Adaptativa
O treinamento do Gaussian Splatting parte de uma nuvem de pontos esparsa, tipicamente gerada por Structure from Motion (SfM) com ferramentas como o COLMAP. Cada ponto se torna uma gaussiana inicial, e o modelo otimiza iterativamente os 14 parâmetros de cada uma para minimizar a diferença entre as imagens renderizadas e as fotos reais.
Função de Perda
A perda combina duas métricas: o erro L1 (diferença absoluta pixel a pixel) e o D-SSIM (structural similarity):
![\[\mathcal{L} = (1 - \lambda) \cdot \mathcal{L}_1 + \lambda \cdot \mathcal{L}_{\text{D-SSIM}}\]](https://sigmoidal.ai/wp-content/ql-cache/quicklatex.com-ea1b0dd85b204778e46b2bd9187081d7_l3.png "Rendered by QuickLaTeX.com")
Com  no paper original. O D-SSIM captura diferenças estruturais que o L1 sozinho não percebe, como bordas e texturas.
no paper original. O D-SSIM captura diferenças estruturais que o L1 sozinho não percebe, como bordas e texturas.
Densificação Adaptativa
A parte mais engenhosa do treinamento é a densificação adaptativa. O modelo monitora o gradiente da posição de cada gaussiana. Gaussianas com gradientes altos (acima de um limiar  ) indicam regiões que precisam de mais detalhe. O modelo responde de duas formas:
) indicam regiões que precisam de mais detalhe. O modelo responde de duas formas:
- Clonagem (clone): se a gaussiana é pequena mas está em região de erro alto, ela é duplicada e deslocada na direção do gradiente.
- Divisão (split): se a gaussiana é grande demais, ela é dividida em duas menores, cobrindo a mesma região com mais precisão.
Periodicamente, gaussianas com opacidade muito baixa (quase invisíveis) são removidas (pruning), mantendo o modelo eficiente. Também é aplicado um reset de opacidade a cada 3000 iterações para evitar acumulação de gaussianas redundantes.
O treinamento completo leva entre 30 e 45 minutos em uma GPU moderna, convergindo tipicamente em 30.000 iterações. O resultado final para uma cena típica do dataset Mip-NeRF 360 contém entre 1 e 5 milhões de gaussianas.
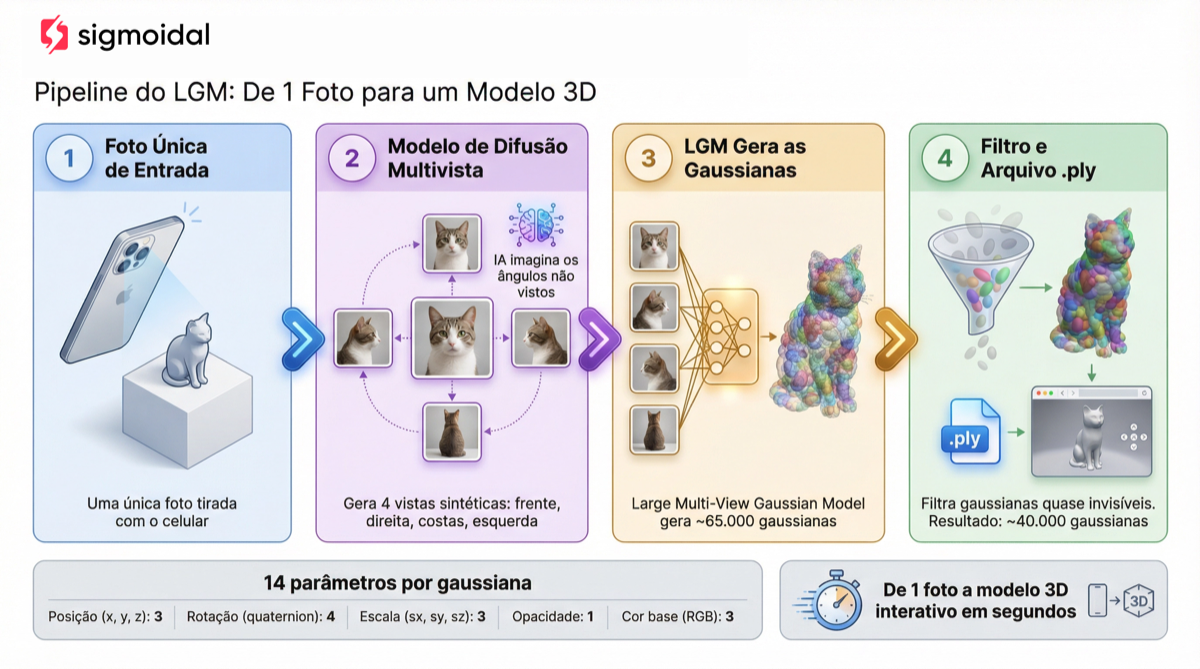
LGM: De Uma Foto para Modelo 3D em Segundos
O pipeline clássico de Gaussian Splatting exige dezenas ou centenas de fotos de uma cena. Mas e se você tiver apenas uma única imagem?
O Large Gaussian Model (LGM), proposto por Tang et al. (2024), resolve isso combinando dois componentes:
- Multi-View Diffusion: um modelo de difusão que, a partir de uma única foto, “imagina” como o objeto seria visto de quatro ângulos diferentes (frente, direita, costas, esquerda).
- Large Gaussian Model: uma rede neural que recebe essas 4 vistas e prediz diretamente os parâmetros de aproximadamente 65.000 gaussianas 3D.
O resultado é um pipeline que converte uma foto em modelo 3D interativo em menos de 10 segundos, sem precisar de SfM, COLMAP ou múltiplas fotos.
Implementação Prática com Python
Vamos implementar o pipeline completo do LGM usando Python no Google Colab. O notebook completo está disponível no topo deste artigo. Aqui, vou detalhar cada etapa.
Configuração do Ambiente
Primeiro, instalamos as dependências e compilamos o rasterizador de gaussianas:
!pip install diffusers accelerate transformers xformers kiui plyfile !pip install git+https://github.com/ashawkey/diff-gaussian-rasterization
A compilação do diff-gaussian-rasterization demora alguns minutos. Esse pacote é o motor de renderização que projeta as gaussianas 3D na tela usando CUDA.
Verificação da GPU
import torch
if torch.cuda.is_available():
gpu = torch.cuda.get_device_name(0)
mem = torch.cuda.get_device_properties(0).total_memory / 1e9
print(f"GPU: {gpu} ({mem:.1f} GB)")
else:
print("CUDA não disponível")
O pipeline roda em GPUs com pelo menos 8 GB de VRAM. No Colab gratuito, a Tesla T4 (15.6 GB) funciona perfeitamente.
Carregando os Modelos
O LGM usa dois modelos da Hugging Face: o pipeline de difusão multi-vista e o modelo de gaussianas.
from diffusers import DiffusionPipeline
# Modelo de difusão multi-vista
image_pipeline = DiffusionPipeline.from_pretrained(
"dylanebert/multi-view-diffusion",
custom_pipeline="dylanebert/multi-view-diffusion",
torch_dtype=torch.float16,
).to("cuda")
# Modelo LGM (Large Gaussian Model)
splat_pipeline = DiffusionPipeline.from_pretrained(
"dylanebert/LGM",
custom_pipeline="dylanebert/LGM",
torch_dtype=torch.float16,
).to("cuda")
Etapa 1: Gerando Vistas Múltiplas
Carregamos uma imagem de entrada e geramos 4 vistas com o modelo de difusão:
import numpy as np
import requests
from PIL import Image
from io import BytesIO
# Carregar imagem de exemplo
image_url = "https://huggingface.co/datasets/dylanebert/3d-arena/resolve/main/inputs/images/a_cat_statue.jpg"
response = requests.get(image_url)
image = Image.open(BytesIO(response.content))
# Converter para array normalizado
input_image = np.array(image, dtype=np.float32) / 255.0
# Gerar vistas a partir da imagem
multi_view_images = image_pipeline(
"", input_image,
guidance_scale=5,
num_inference_steps=30,
elevation=0
)
print(f"Vistas geradas: {len(multi_view_images)} imagens")
print(f"Resolução: {multi_view_images[0].shape}")
O modelo retorna 5 imagens: a imagem de entrada reconstruída mais 4 vistas novas (frente, direita, costas, esquerda). O guidance_scale=5 controla a fidelidade ao prompt (valores maiores produzem resultados mais conservadores), e num_inference_steps=30 define o número de passos de denoising.
Visualizando as Vistas
import matplotlib.pyplot as plt
fig, axes = plt.subplots(1, 4, figsize=(16, 4))
labels = ['Frente', 'Direita', 'Costas', 'Esquerda']
for ax, img, label in zip(axes, multi_view_images, labels):
ax.imshow(img)
ax.set_title(label, fontsize=14)
ax.axis('off')
plt.suptitle('Vistas geradas pelo modelo de difusão', fontsize=16)
plt.tight_layout()
plt.show()
As vistas geradas não são perfeitas. Detalhes finos podem ser inconsistentes entre ângulos. Mas para a reconstrução 3D via LGM, essa precisão é suficiente para produzir um modelo convincente.
Etapa 2: Gerando o Modelo 3D
Com as 4 vistas em mãos, o LGM prediz diretamente os parâmetros das gaussianas:
# Gerar gaussianas 3D
splat = splat_pipeline(multi_view_images)
print(f"Shape: {splat.shape}")
print(f"Gaussianas: {splat.shape[1]:,}")
print(f"Parametros por gaussiana: {splat.shape[2]}")
O output tem shape (1, 65536, 14): 65.536 gaussianas, cada uma com 14 parâmetros (posição, escala, rotação, cor, opacidade).
Salvando como PLY
O formato PLY (Polygon File Format) é o padrão para salvar modelos Gaussian Splatting:
splat_pipeline.save_ply(splat, "cat_statue.ply")
import os
size_mb = os.path.getsize("cat_statue.ply") / (1024 * 1024)
print(f"Arquivo: cat_statue.ply ({size_mb:.1f} MB)")
O arquivo resultante tem cerca de 2.2 MB, com aproximadamente 40.000 gaussianas. A redução de 65.536 para 40.000 acontece porque gaussianas com opacidade muito baixa (praticamente invisíveis) são descartadas no processo de salvamento.
Inspecionando o Modelo
from plyfile import PlyData
plydata = PlyData.read("cat_statue.ply")
vertex = plydata['vertex']
print(f"Gaussianas salvas: {len(vertex):,}")
print(f"Propriedades: {[p.name for p in vertex.properties]}")
As propriedades confirmam os 14 parâmetros: x, y, z (posição), f_dc_0, f_dc_1, f_dc_2 (cor via harmônicos esféricos), opacity, scale_0, scale_1, scale_2, rot_0, rot_1, rot_2, rot_3.
Visualização 3D Interativa
Para visualizar o modelo, extraímos as posições e cores das gaussianas e criamos um scatter plot 3D:
import plotly.graph_objects as go
# Extrair coordenadas
x = vertex['x']
y = vertex['y']
z = vertex['z']
# Converter harmônicos esféricos para RGB
C0 = 0.28209479177387814
r = np.clip(0.5 + C0 * vertex['f_dc_0'], 0, 1)
g = np.clip(0.5 + C0 * vertex['f_dc_1'], 0, 1)
b = np.clip(0.5 + C0 * vertex['f_dc_2'], 0, 1)
colors = [f'rgb({int(ri*255)},{int(gi*255)},{int(bi*255)})'
for ri, gi, bi in zip(r, g, b)]
fig = go.Figure(data=[go.Scatter3d(
x=x, y=y, z=z,
mode='markers',
marker=dict(size=1.5, color=colors, opacity=0.6)
)])
fig.update_layout(
scene=dict(
aspectmode='data',
bgcolor='black'
),
paper_bgcolor='black',
width=800, height=600,
title="Modelo 3D gerado a partir de uma única foto"
)
fig.show()
O Plotly mostra apenas os centros das gaussianas como pontos. Para uma visualização completa com as elipsoides renderizadas, você pode baixar o arquivo PLY e abrir em viewers dedicados como o antimatter15 splat viewer ou o SuperSplat.
Limitações e Direções Futuras
Gaussian Splatting é uma técnica poderosa, mas apresenta limitações que você deve conhecer:
- Consumo de memória: cenas complexas podem exigir milhões de gaussianas, consumindo vários GB de VRAM. Técnicas de compressão, como as discutidas em compressão de modelos, estão sendo adaptadas para mitigar esse problema.
- Superfícies finas e transparentes: vidros, fumaça e cabelos são difíceis de representar com gaussianas opacas. Trabalhos como Gaussian Opacity Fields (2024) endereçam esse desafio.
- Geometria: as gaussianas capturam aparência muito bem, mas a geometria subjacente pode ser ruidosa. Extrair uma malha poligonal limpa a partir de gaussianas ainda é uma área ativa de pesquisa.
A evolução tem sido acelerada. Desde o paper original em 2023, já surgiram extensões para vídeo 4D (4D Gaussian Splatting), geração a partir de texto, animação de avatares e integração com pipelines de SLAM para mapeamento em tempo real.
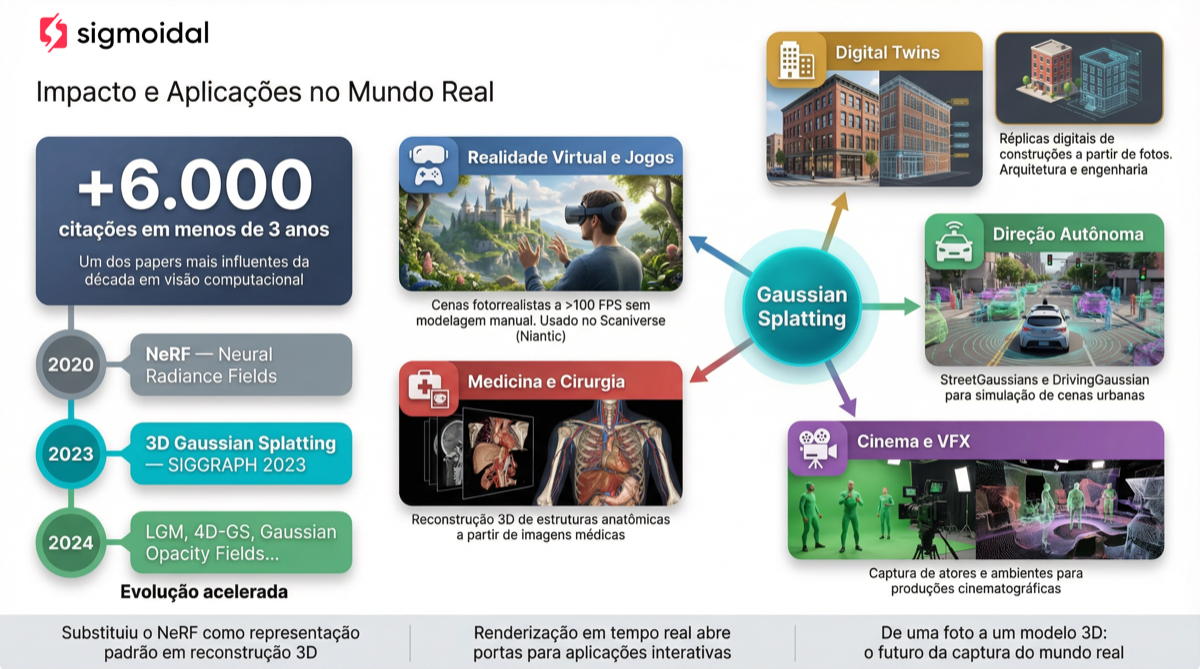
Aplicações no Mundo Real
O impacto do Gaussian Splatting vai muito além da pesquisa acadêmica:
Realidade Virtual e Jogos: capturar ambientes reais e renderizar a mais de 100 FPS abre caminho para experiências VR fotorrealistas baseadas em dados reais, sem modelagem manual.
Digital Twins: representar construções, fábricas e cidades em 3D a partir de fotos de drones. Combinado com técnicas de estimativa de profundidade, isso permite inspeções e monitoramento remotos.
Direção Autônoma: empresas como Wayve e NVIDIA estão usando Gaussian Splatting para gerar simulações realistas de cenários de trânsito, acelerando o treinamento de sistemas de condução autônoma.
Medicina e Cinema: desde planejamento cirúrgico com visualização 3D de exames até efeitos visuais de cinema, a capacidade de reconstruir cenas fotorrealistas a partir de fotos tem aplicações em praticamente qualquer domínio visual.
Takeaways
- Gaussian Splatting é uma revolução na reconstrução 3D porque substitui a representação neural implícita (NeRF) por milhões de gaussianas 3D explícitas, alcançando renderização acima de 100 FPS com qualidade fotorrealista.
- Cada gaussiana carrega 14 parâmetros (posição, escala, rotação, cor via harmônicos esféricos e opacidade), e o treinamento usa densificação adaptativa para adicionar ou remover gaussianas conforme necessário.
- O LGM democratiza o acesso ao permitir gerar modelos 3D a partir de uma única foto em segundos, sem necessidade de múltiplas imagens ou ferramentas complexas como COLMAP. Com o notebook deste artigo, você pode gerar seus próprios modelos 3D diretamente no Google Colab.