Em novembro de 2025, a conferência NeurIPS concedeu o Test of Time Award a um paper de 2015 com mais de 56.000 citações. O prêmio reconhece trabalhos que resistiram à prova do tempo e moldaram o rumo da pesquisa em inteligência artificial. O paper em questão está na base de praticamente todo detector de objetos moderno.
Estamos falando do Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks, publicado por Shaoqing Ren, Kaiming He, Ross Girshick e Jian Sun, pesquisadores da Microsoft Research Asia em Pequim.
Neste artigo, vamos dissecar a contribuição técnica do Faster R-CNN: o problema que ele resolveu, como a Region Proposal Network funciona, os resultados experimentais que comprovaram o impacto e o legado que se estende até os detectores de 2026.
—
Pós-Graduação em Visão Computacional A primeira do Brasil com dupla certificação internacional. No dia 1 de abril, às 20h, faço a live de lançamento com todos os detalhes. Inscreva-se na live de lançamento.
—
O Que É Detecção de Objetos
Detecção de objetos (object detection) é a tarefa de localizar e classificar simultaneamente múltiplas instâncias de objetos em uma imagem. Diferente da classificação, que atribui um rótulo único à imagem inteira, a detecção exige prever coordenadas de bounding boxes e a classe de cada objeto encontrado. A base para tudo isso são as redes neurais convolucionais, que extraem features visuais hierárquicas da imagem.
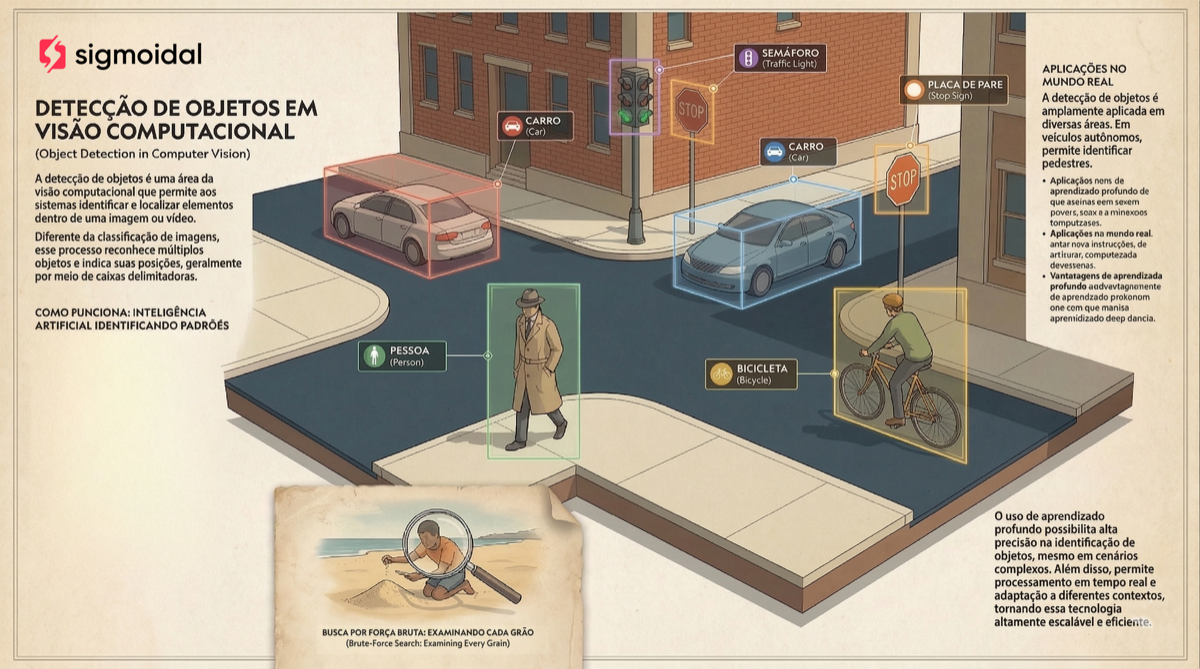
Detecção de objetos em uma cena urbana. A rede precisa dizer o que cada objeto é e onde ele está. Fonte: Sigmoidal
Essa é a tarefa que permite a um veículo autônomo distinguir pedestres de placas de trânsito, a uma câmera de segurança identificar intrusos, e a um sistema médico localizar lesões em exames de imagem.
Antes de 2014, a abordagem dominante era a busca exaustiva por sliding window. O algoritmo percorria a imagem com janelas de diferentes tamanhos e proporções, passando cada recorte por um classificador. Uma única imagem podia gerar mais de 100.000 candidatos, tornando o processo computacionalmente proibitivo.

A analogia com a busca na praia: a sliding window peneira cada grão de areia, enquanto a RPN aprende onde procurar. Fonte: Sigmoidal
De R-CNN a Fast R-CNN: A Evolução e o Gargalo
Em 2014, Ross Girshick publicou o R-CNN, introduzindo redes neurais convolucionais na detecção de objetos. A arquitetura usava o algoritmo Selective Search para gerar cerca de 2.000 propostas de regiões e então classificava cada uma com uma CNN. A precisão melhorou drasticamente em relação aos métodos anteriores, mas o custo era alto: 47 segundos por imagem.
Em 2015, o mesmo Girshick publicou o Fast R-CNN. A mudança fundamental foi processar a imagem inteira uma única vez com o backbone convolucional e extrair features de cada região diretamente do mapa de features compartilhado, via RoI pooling. O tempo caiu para cerca de 2 segundos por imagem.
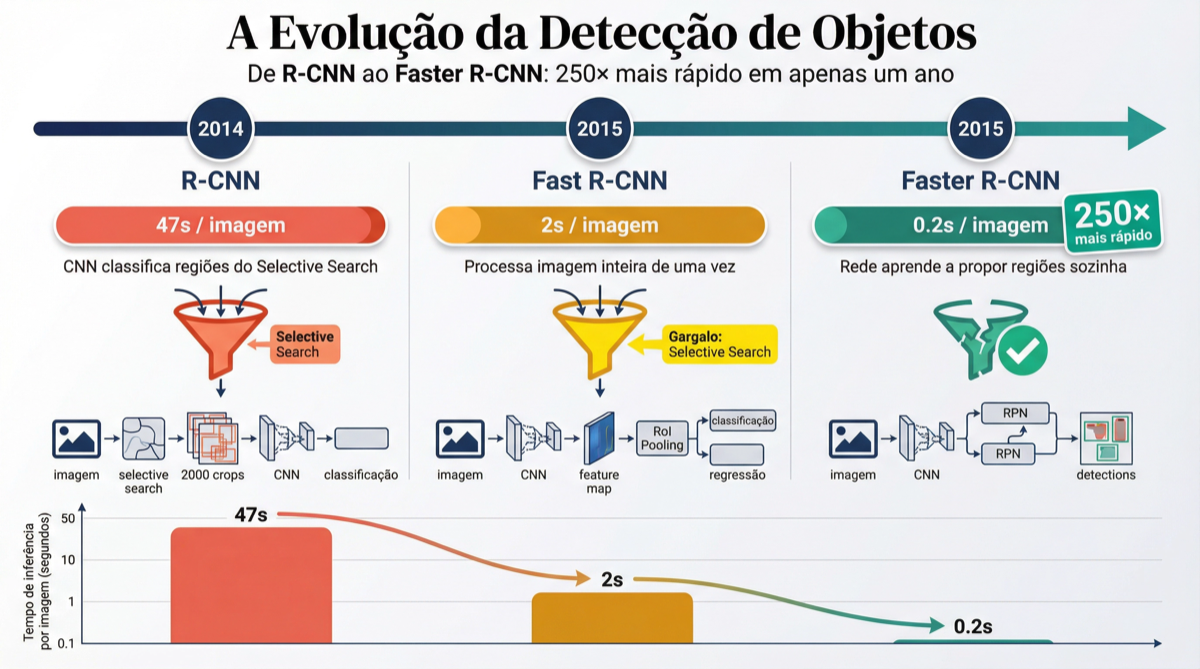
A evolução da família R-CNN: de 47s/imagem (R-CNN) para 0.2s/imagem (Faster R-CNN) em apenas um ano. Fonte: Sigmoidal
Mas o gargalo persistia. O Selective Search rodava fora da rede neural, na CPU, e dominava o tempo total de processamento. Em um pipeline com VGG-16, os dados da Table 5 do paper original revelam o problema:
| Etapa | Selective Search | RPN |
|---|---|---|
| Convolução | 146 ms | 141 ms |
| Proposição de regiões | 1.510 ms | 10 ms |
| Classificação por região | 174 ms | 47 ms |
| Total | 1.830 ms | 198 ms |
O Selective Search consumia 83% do tempo total. A rede de detecção era rápida; o gargalo era a etapa de proposição de regiões.
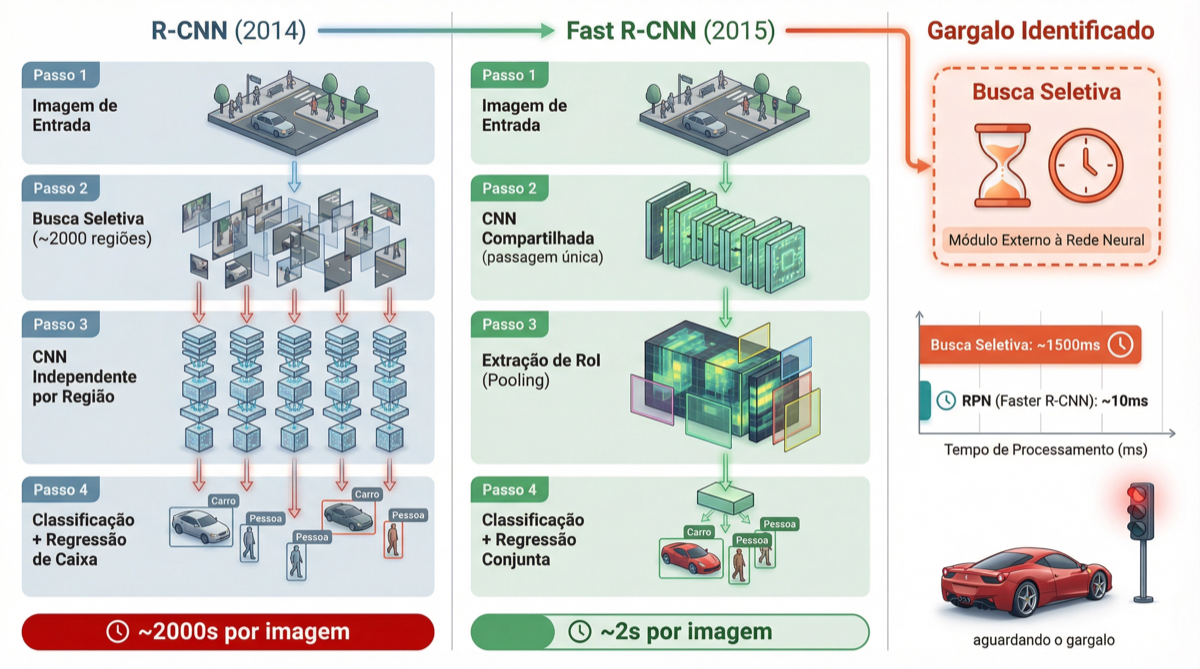
Comparação dos pipelines R-CNN e Fast R-CNN. O gargalo do Selective Search (~1.500 ms) ficava fora da rede neural. Fonte: Sigmoidal
A Solução: Region Proposal Network
A pergunta que Ren, He, Girshick e Sun fizeram foi direta: se a rede neural já processa a imagem inteira para classificar objetos, por que ela não pode aprender, ao mesmo tempo, a propor as regiões de interesse?
A resposta foi a Region Proposal Network (RPN), uma sub-rede convolucional que compartilha o backbone de features com o detector e aprende a propor regiões end-to-end, eliminando qualquer módulo externo.
Arquitetura da RPN
A RPN opera sobre o mapa de features do último layer convolucional compartilhado. Uma janela deslizante de 3×3 percorre esse mapa, e em cada posição espacial gera duas saídas:
- Objectness scores: probabilidade de a região conter um objeto vs. background (classificação binária)
- Regressão de bounding box: quatro coordenadas refinadas
 relativas a cada âncora
relativas a cada âncora
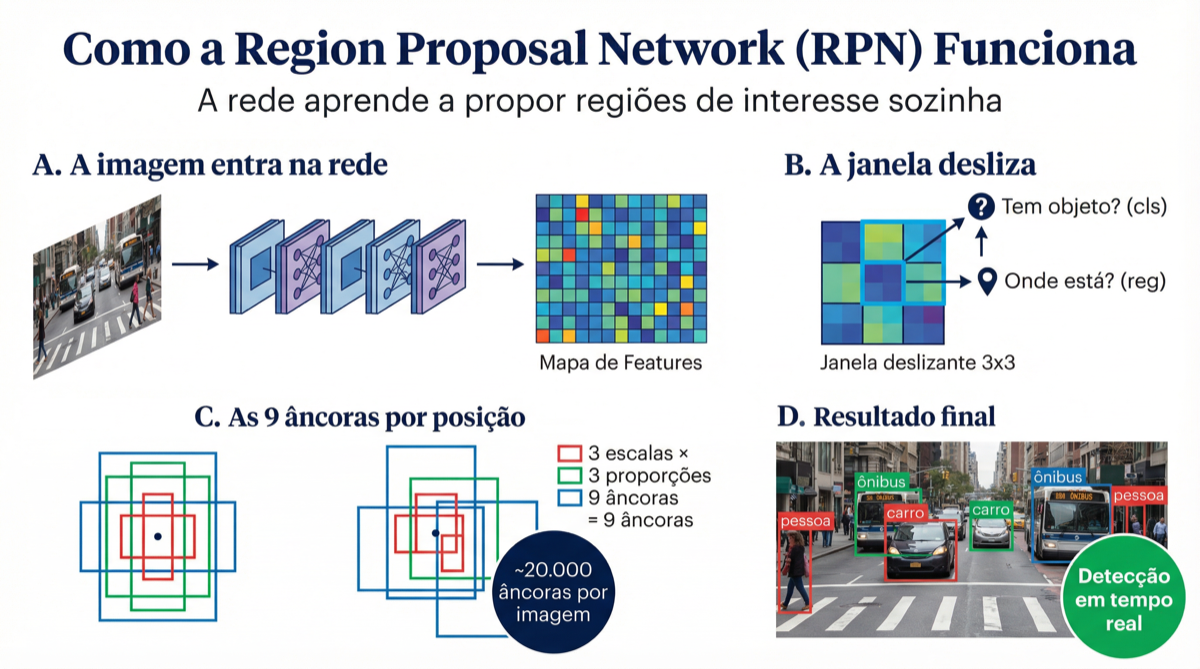
A RPN em quatro passos: (A) a imagem é processada pelo backbone, (B) uma janela 3×3 desliza sobre o mapa de features, (C) 9 âncoras por posição testam diferentes escalas e proporções, (D) resultado final com detecções. Fonte: Sigmoidal
O Conceito de Âncoras
Para capturar objetos de diferentes escalas e proporções sem redimensionar a imagem, o paper introduziu âncoras (anchor boxes). Em cada posição da janela deslizante, a RPN testa  formatos pré-definidos: 3 escalas (128, 256, 512 pixels) combinadas com 3 proporções (1:1, 1:2, 2:1).
formatos pré-definidos: 3 escalas (128, 256, 512 pixels) combinadas com 3 proporções (1:1, 1:2, 2:1).
Em uma imagem de 1000×600 pixels processada por uma rede com stride de 16, o mapa de features tem aproximadamente 60×40 posições, gerando cerca de 20.000 âncoras no total. Cada âncora recebe um rótulo positivo (IoU > 0.7 com algum ground truth) ou negativo (IoU < 0.3), e a rede é treinada para classificar e refinar essas âncoras simultaneamente.
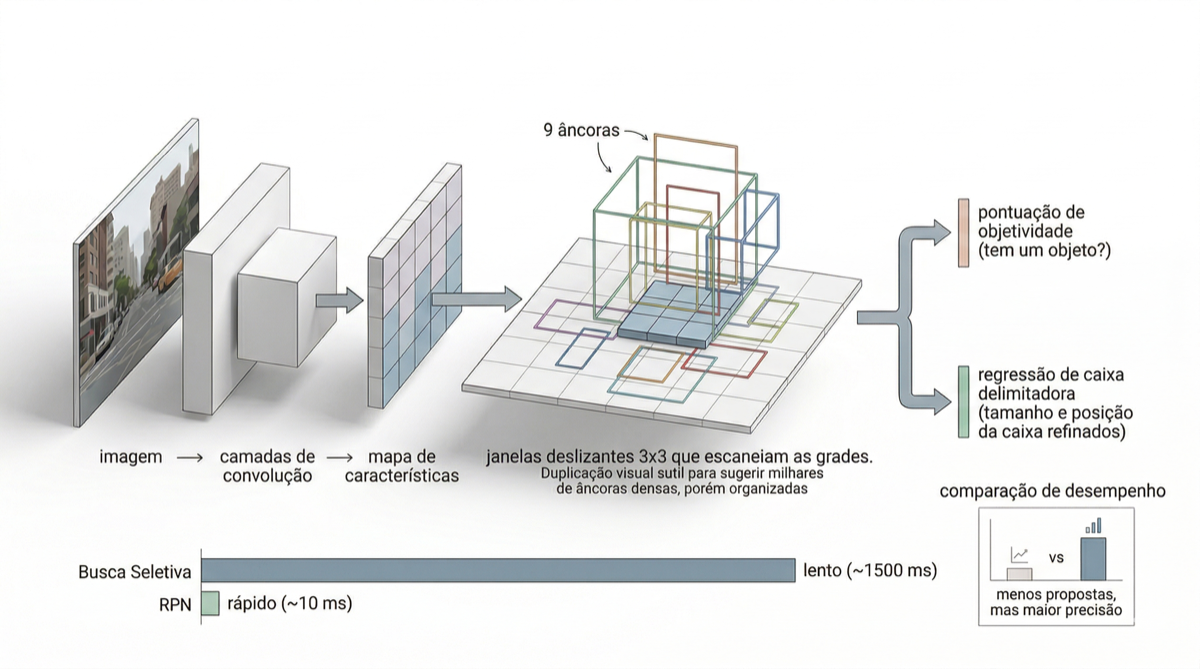
A RPN reutiliza o mapa de features do backbone convolucional. O custo adicional de gerar propostas é marginal: apenas 10 ms. Fonte: Sigmoidal
A contribuição central é o compartilhamento de features. As representações que a rede já extraiu para a classificação são reutilizadas pela RPN para a proposição, tornando o custo adicional marginal.
Treinamento Alternado
O paper propõe um esquema de treinamento alternado em 4 etapas (4-step alternating training):
- Treinar a RPN isoladamente, inicializada com backbone pré-treinado no ImageNet
- Treinar o detector Fast R-CNN usando as propostas da RPN do passo 1
- Congelar as camadas convolucionais compartilhadas e re-treinar apenas os layers específicos da RPN
- Re-treinar os layers específicos do detector, mantendo o backbone fixo
Esse processo garante que RPN e detector compartilhem as mesmas features convolucionais, formando uma rede unificada.
Resultados Experimentais
Os números da Table 5 do paper são contundentes. Com VGG-16, o sistema completo processa uma imagem em 198 ms (5 FPS), contra 1.830 ms do pipeline com Selective Search. Com a rede ZF (ZFNet), mais leve, atinge 59 ms por imagem (17 FPS), quase tempo real em 2015 com uma única GPU K40.
Mas a velocidade não é o resultado mais significativo. No benchmark PASCAL VOC 2007, o Selective Search precisava de 2.000 propostas para atingir 58,7% de mAP. O Faster R-CNN com RPN usava apenas 300 propostas e alcançou 59,9% de mAP. Melhor precisão com 6,7 vezes menos propostas. Isso demonstra que propostas aprendidas pela rede são qualitativamente superiores a propostas geradas por heurísticas de baixo nível.
Na competição ILSVRC 2015, o Faster R-CNN serviu como base do sistema que conquistou o primeiro lugar em quatro categorias: detecção e localização no ImageNet, detecção e segmentação no COCO.
Por Que Isso Mudou Tudo
O Faster R-CNN não foi apenas um detector mais rápido. Ele consolidou o paradigma de que a rede neural pode aprender a executar todo o pipeline de detecção, incluindo decidir onde olhar na imagem. Essa noção de proposição aprendida end-to-end abriu o caminho que a visão computacional moderna segue.
O paper descreve a RPN como um mecanismo de atenção: a sub-rede que indica ao detector onde focar. Isso em 2015, dois anos antes do *Attention is All You Need*, o paper que formalizou o mecanismo de atenção no Transformer.
O legado inclui:
- Mask R-CNN (2017): estende o Faster R-CNN com uma branch de segmentação de instâncias. Melhor paper do ICCV 2017.
- Feature Pyramid Networks (2017): detecção multi-escala construída sobre a arquitetura do Faster R-CNN.
- Detectores 3D: PointPillars e VoxelNet aplicam a mesma lógica de proposição aprendida para nuvens de pontos LiDAR em veículos autônomos.
- SAM (Segment Anything) (2023): modelo de segmentação universal da Meta, co-autorado por Ross Girshick.
Se você quiser acompanhar conteúdos como esse em vídeo, se inscreva no canal do YouTube onde eu explico a história completa desse paper com infográficos e mais detalhes.
Os Quatro Autores
Em 2015, os quatro autores trabalhavam juntos na Microsoft Research Asia, em Pequim. Uma década depois, seus caminhos ilustram a magnitude do impacto.
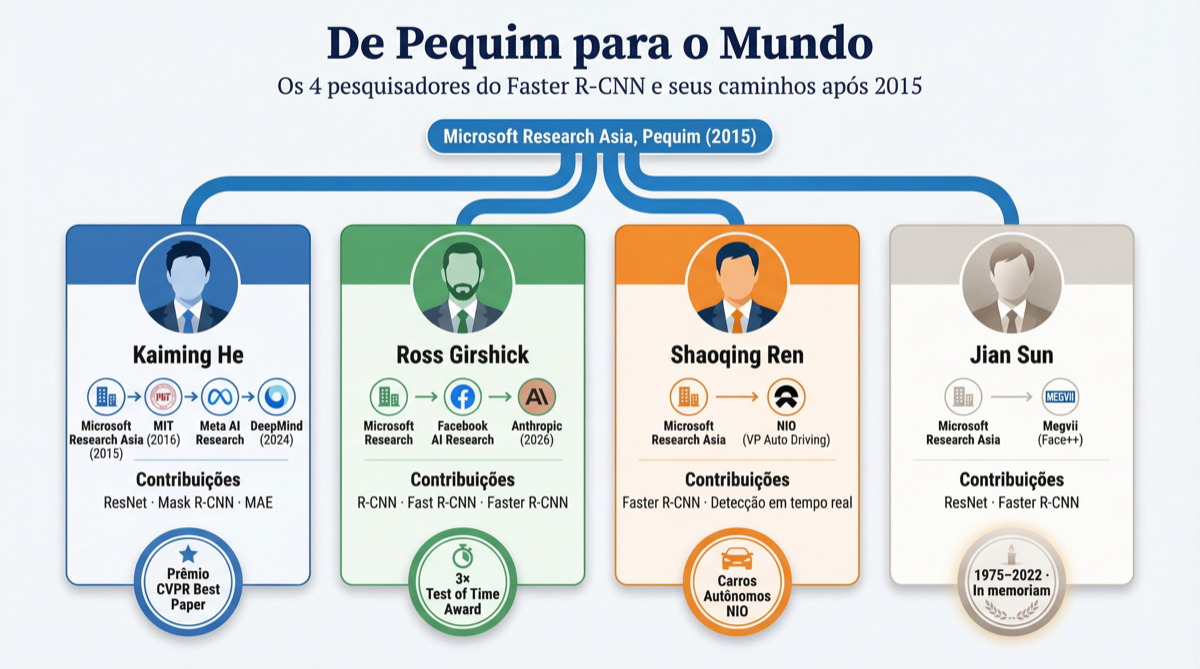
De Pequim para o mundo: os quatro autores seguiram caminhos que moldaram a visão computacional moderna. Fonte: Sigmoidal
Kaiming He é considerado um dos pesquisadores mais influentes da visão computacional contemporânea. Co-criador da ResNet, a arquitetura de rede residual mais citada da história da ciência da computação, He passou pelo Facebook AI Research e hoje é professor associado no MIT e cientista part-time no Google DeepMind.
Ross Girshick é o criador de toda a família R-CNN. R-CNN (2014), Fast R-CNN (2015), Faster R-CNN (2015) e Mask R-CNN (2017). Recebeu prêmios de impacto duradouro nas três maiores conferências da área: CVPR, ICCV e NeurIPS. Após passagens pelo Facebook AI Research e pelo Allen Institute, co-fundou a startup Vercept, adquirida pela Anthropic em 2026.
Shaoqing Ren, primeiro autor do paper e responsável pela implementação da RPN, co-fundou a Momenta, startup de direção autônoma na China. Hoje é Vice-Presidente de direção autônoma na NIO, uma das maiores fabricantes de veículos elétricos da China. O pesquisador que inventou a RPN aplica essa tecnologia para fazer carros dirigirem sozinhos. Foi ele quem subiu ao palco do NeurIPS 2025 para receber o Test of Time Award em nome do grupo.
Jian Sun, o pesquisador mais sênior do grupo, foi cientista-chefe da Megvii, empresa por trás do Face++, um dos maiores sistemas de reconhecimento facial do mundo. Criou o ShuffleNet para inferência em dispositivos móveis e liderou o desenvolvimento da plataforma Brain++. Jian Sun faleceu em junho de 2022, aos 45 anos.
Takeaways
- A RPN unificou proposição e detecção em uma única rede neural, eliminando a dependência do Selective Search e reduzindo o tempo de proposição de 1.510 ms para 10 ms.
- O conceito de âncoras permitiu capturar objetos em múltiplas escalas e proporções sem redimensionar a imagem, gerando ~20.000 candidatos avaliados simultaneamente pela rede.
- Menos propostas, mais precisão: 300 propostas da RPN superaram 2.000 do Selective Search no PASCAL VOC 2007 (59,9% vs. 58,7% mAP), demonstrando a superioridade de propostas aprendidas sobre heurísticas.
- O paradigma de aprendizado end-to-end inaugurado pelo Faster R-CNN influenciou toda a geração seguinte de detectores, de Mask R-CNN e FPN até SAM e os modelos YOLO atuais.
- 56.000 citações e um Test of Time Award confirmam que a intuição central do paper, de que a rede pode aprender a decidir onde olhar, é uma das ideias mais consequentes da visão computacional.