Neste tutorial, você vai aprender como implementar Redes Neurais Multicamadas utilizando Python e a biblioteca de Deep Learning Keras, uma das mais populares atualmente.
Keras é uma biblioteca de Redes Neurais, capaz de rodar com o TensorFlow (não apenas), e que foi desenvolvida pensando em possibilitar uma fácil e rápida prototipação.
Redes Neurais Multicamadas são aqueles nas quais os neurônios estão estruturados em duas ou mais camadas (layers) de processamento (já que no mínimo haverá 1 layer de entrada e 1 layer de saída).
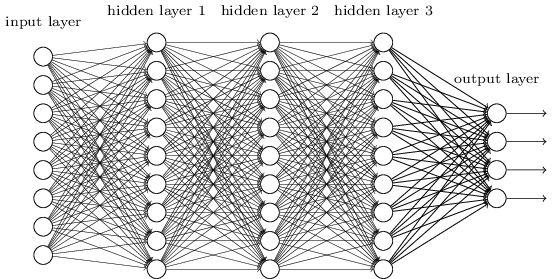
Implementar uma arquitetura completa de Redes Neurais from scratch é uma tarefa hercúlea, que exige um entendimento mais sólido de Programação, Álgebra Linear e Estatística – isso sem falar ainda que o desempenho computacional da sua própria implementação dificilmente baterá o desempenho de bibliotecas famosas na comunidade.
Para mostrar que com poucas linhas de código é possível implementar um Rede simples, vamos pegar o super-conhecido problema de classificação MNIST e ver o desempenho do nosso algoritmo quando submetido a esse dataset com 70.000 imagens!
Código do Artigo
Acesse o código-fonte deste artigo gratuitamente.
Informe seu email para acessar o código:
✓ Seu código está pronto!
Abrir no Google Colab →Arquitetura das Redes Neurais
As Redes Neurais são modeladas como um conjunto de neurônios conectados como um grafo acíclico. O que isso significa na prática? Isso significa que as saídas (outputs) de alguns neurônios serão as entradas (inputs) de outros neurônios.
As Redes Neurais mais comumente encontradas por aí são aquelas organizadas em camadas (layers) distintas, e cada camada contendo um conjunto de neurônios. Já o tipo de layer mais comumente encontrado é aquele do tipo fully-connected layer (camada totalmente conectada). Nesse, os neurônios entre dois layers adjacentes se conectam dois a dois.
Esse tipo de arquitetura também é conhecida como Rede Neural Feedforward,pois apenas é permitido a um neurônio do layer li se conectar a um neurônio do layer li+1 , como ilustrado na figura abaixo.
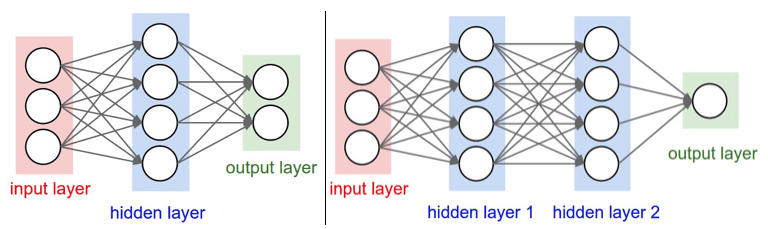
O objetivo deste post é realizar na prática uma implementação por meio da biblioteca Keras. Para um introdução mais completa e detalhada sobre o assunto, assim como os conceitos básicos sobre deep learning, recomendo a leitura deste artigo, no qual indico 3 ótimos cursos online.
O que é MNIST
MNIST é um conjunto de dados que contém milhares de imagens manuscritas dos dígitos de 0-9. O desafio nesse dataset é, dada uma imagem qualquer, aplicar o label correspondente (classificar corretamente a imagem). O MNIST é tão estudado e utilizado pela comunidade, que atua como benchmark para comparar diferentes algoritmos de reconhecimento de imagens.

O dataset completo é composto 70.000 imagens, cada uma de tamanho 28 X 28 pixels. A figura acima mostra alguns exemplares aleatórios do conjunto de dados, para cada um dos dígitos possíveis. Ressalta-se que as imagens já estão normalizadas e centralizadas.
Uma vez que as imagens estão em tons de cinza, ou seja, possuem apenas um canal, o valor relativo a cada pixel das imagens deve variar dentro do intervalo [0, 255].
Redes Neurais Multicamadas são aqueles nas quais os neurônios estão estruturados em duas ou mais camadas (layers) de processamento.
IAN GOODFELLOW
MNIST no Python
De tão utilizado, o conjunto de dados MNIST já está disponível dentro da biblioteca scikit-learn, e pode ser importado diretamente pelo Python com fetch_mldata("MNIST Original").
Para exemplificar como importar o MNIST completo e extrair algumas informações básicas, vamos rodar o código abaixo:
# importar as bibliotecas necessárias
from sklearn.datasets import fetch_mldata
import matplotlib.pyplot as plt
import numpy as np
# importar o conjunto de dados MNIST
dataset = fetch_mldata("MNIST Original")
(data, labels) = (dataset.data, dataset.target)
# Exibir algumas informações do dataset MNIST
print("[INFO] Número de imagens: {}".format(data.shape[0]))
print("[INFO] Pixels por imagem: {}".format(data.shape[1]))
# escolher um índice aleatório do dataset e exibir
# a imagem e label correspondente
np.random.seed(17)
randomIndex = np.random.randint(0, data.shape[0])
print("[INFO] Imagem aleatória do MNIST com label '{:.0f}':".format(labels[randomIndex]))
plt.imshow(data[randomIndex].reshape((28,28)), cmap="Greys")
plt.show()
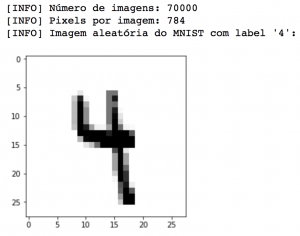
Acima, podemos ver que de fato o array contendo as imagens possui 70.000 linhas (uma linha para cada imagem) e 784 colunas (todos os pixels da imagem 28 X 28). Também podemos ver uma das imagens escolhidas aleatoriamente. No caso desse dígito, nosso algoritmo teria tido sucesso se conseguisse classificar corretamente o dígito como ‘4’.
Implementando nossa Rede Neural com Python + Keras
Feita uma breve introdução sobre Redes Neurais, vamos implementar uma Rede Neural Feedforward para o problema de classificação MNIST.
Crie um novo arquivo em sua IDE preferida, com o nome rede_neural_keras.py, e siga os passos do código abaixo.
# importar os pacotes necessários from sklearn.datasets import fetch_mldata from sklearn.model_selection import train_test_split from sklearn.metrics import classification_report from sklearn.preprocessing import LabelBinarizer from keras.models import Sequential from keras.layers.core import Dense from keras.optimizers import SGD import numpy as np import matplotlib.pyplot as plt
Acima, importamos todos pacotes necessários para criar uma Rede Neural simples, com a biblioteca Keras. Caso você tenha tido um erro ao tentar importar os pacotes, ou não tenha um ambiente virtual em Python dedicado para trabalhar com Deep Learning/Computer Vision, recomendo procurar um tutorial baseado no seu Sistema Operacional.
# importar o MNIST
print("[INFO] importando MNIST...")
dataset = fetch_mldata("MNIST Original")
# normalizar todos pixels, de forma que os valores estejam
# no intervalor [0, 1.0]
data = dataset.data.astype("float") / 255.0
labels = dataset.target
Após importar o conjunto de imagens, vou dividir entre conjunto de treino (75%) e conjunto de teste (25%), prática já bem conhecida no universo do Data Science. Mas atenção! O conjunto de treino e de teste DEVEM SER INDEPENDENTES, para evitar diversos problemas, entre eles o de overfitting.
Apesar de parecer complicado, isso pode ser feito com apenas uma linha de código, pois graças à biblioteca scikit-learn, isso pode ser feito facilmente com o método train_test_split.
Nesta etapa de preparação dos nossos dados, será preciso também converter os labels – que são representados por números inteiros – para o formato de vetor binário. Para exemplificar o que é um vetor binário, veja o exemplo abaixo, que indica o label ‘4’.
4 = [0,0,0,0,1,0,0,0,0,0]
Nesse vetor, o valor 1 é atribuído ao índice correspondente ao label e o valor 0 aos outros. Essa operação , conhecida como one-hot encoding também pode ser feita facilmente com a classe LabelBinarizer.
# dividir o dataset entre train (75%) e test (25%) (trainX, testX, trainY, testY) = train_test_split(data, dataset.target) # converter labels de inteiros para vetores lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.transform(testY)
Pronto! Com o dataset importado e processado da maneira correta, a gente pode finalmente definir a arquitetura da nossa Rede Neural com o Keras.
De maneira totalmente arbitrária, defini que a Rede Neural terá 4 layers:
- O nosso primeiro layer (l0) receberá como input os valores relativos a cada pixel das imagens. Ou seja, como cada imagem possui tamanho igual a 28 X 28 pixels, l0 terá 784 neurônios.
- Os hidden layers l1 e l2 terão arbitrariamente 128 e 64 neurônios.
- Por fim, a última camada, l3, terá a quantidade de neurônios correspondente à quantidade de classes que o nosso problema de classificação possui: 10 (lembrando, são 10 dígitos possíveis).
# definir a arquitetura da Rede Neural usando Keras # 784 (input) => 128 (hidden) => 64 (hidden) => 10 (output) model = Sequential() model.add(Dense(128, input_shape=(784,), activation="sigmoid")) model.add(Dense(64, activation="sigmoid")) model.add(Dense(10, activation="softmax"))
Dentro do conceito de arquitetura feedforward, a nossa Rede Neural é instanciada pela classe Sequential, o que quer dizer que cada camada será “empilhada” sobre outra, com o output de uma sendo o input da próxima. No nosso exemplo, todos layers são do tipo fully-connected layer.
Os hidden layers serão ativados pela função sigmoid, que recebe os valores reais dos neurônios como input e os joga dentro do range [0, 1]. Já para a última camada, como essa tem que refletir as probabilidades para cada uma das classes possíveis, será utilizada a função softmax.
Para treinar nosso modelo, vou usar o algoritmo mais importante para as Redes Neurais: Stochastic Gradient Descent (SGD). Quero fazer um post dedicado sobre o SGD no futuro (matemática + código), tamanha sua importância! Mas por enquanto, vamos usar o algoritmo já pronto de nossas bibliotecas.
A learning rate do SGD será igual a 0.01, e a loss function será acategorical_crossentropy, uma vez que o número de classes do output é maior que dois.
# treinar o modelo usando SGD (Stochastic Gradient Descent)
print("[INFO] treinando a rede neural...")
model.compile(optimizer=SGD(0.01), loss="categorical_crossentropy",
metrics=["accuracy"])
H = model.fit(trainX, trainY, batch_size=128, epochs=10, verbose=2,
validation_data=(testX, testY))
A força da Deep Learning vem basicamente de um único algoritmo muito importante: Stochastic Gradient Descent (SGD)
Chamando a model.fit, tem início então o treinamento da rede neural. Após um tempo que varia de acordo com sua máquina, os pesos de cada nó são otimizados, e a rede pode ser considerada como treinada.
Para avaliar o desempenho do algoritmo, chamamos o método model.predict para gerar previsões em cima do dataset de teste. O desafio do modelo é fazer a previsão para as 17.500 imagens que compõe o conjunto de teste, atribuindo um label de 0-9 para cada uma delas:
# avaliar a Rede Neural
print("[INFO] avaliando a rede neural...")
predictions = model.predict(testX, batch_size=128)
print(classification_report(testY.argmax(axis=1), predictions.argmax(axis=1)))
Por fim, após o relatório de desempenho obtido, vamos querer plotar a accuracy e loss ao longo das iterações. Analisar visualmente permite que identifiquemos facilmente situações de overfitting, por exemplo:
# plotar loss e accuracy para os datasets 'train' e 'test'
plt.style.use("ggplot")
plt.figure()
plt.plot(np.arange(0,100), H.history["loss"], label="train_loss")
plt.plot(np.arange(0,100), H.history["val_loss"], label="val_loss")
plt.plot(np.arange(0,100), H.history["acc"], label="train_acc")
plt.plot(np.arange(0,100), H.history["val_acc"], label="val_acc")
plt.title("Training Loss and Accuracy")
plt.xlabel("Epoch #")
plt.ylabel("Loss/Accuracy")
plt.legend()
plt.show()
Executando a Rede Neural
Com o código pronto, é só executar o comando abaixo para ver nossa Rede Neural construída em cima da biblioteca Keras em pleno funcionamento:
carlos$ python neural_network_keras.py
Como resultado, o classification_report mostra que ao final das 100 epochs, a rede conseguiu atingir uma acurácia de 92%, o que é um bom resultado para este tipo de arquitetura. Apenas como curiosidade, as Redes Neurais Convolucionais têm o potencial de atingir até 99% de acurácia (!):
Obviamente há muitas melhorias que podem ser feitas para melhorar o desempenho da nossa rede, mas já dá para ver que mesmo uma arquitetura simples apresenta um ótimo desempenho.
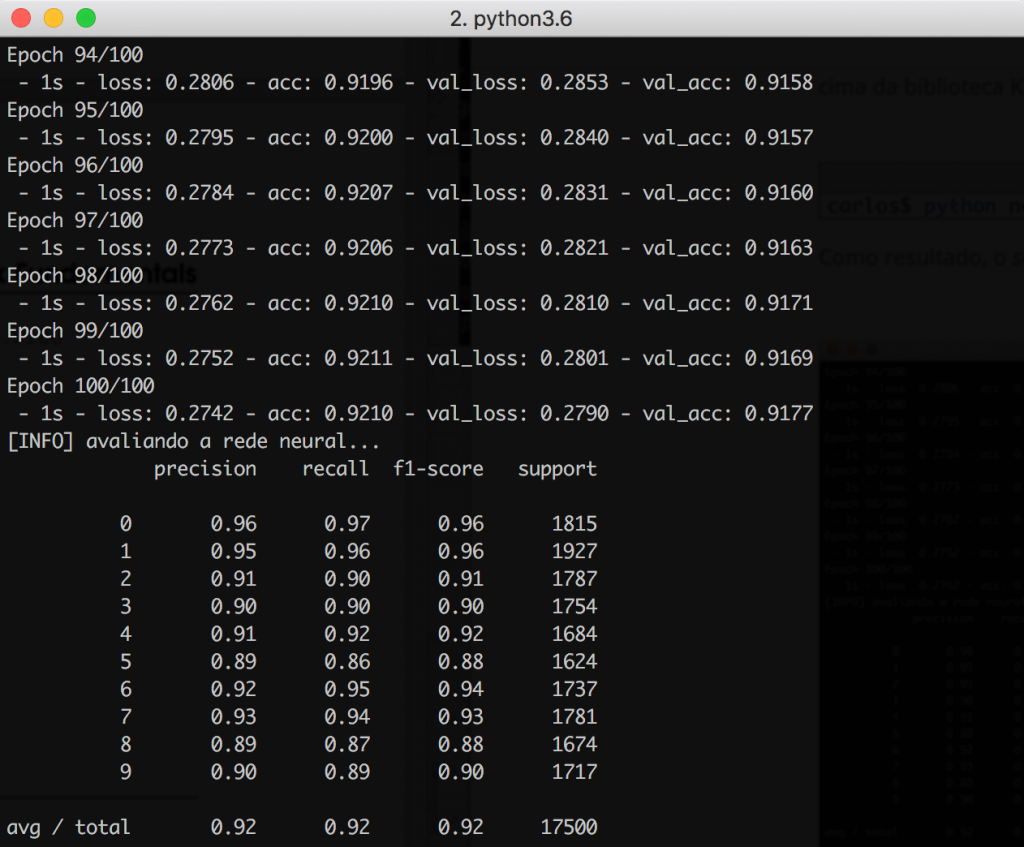
Olhando o gráfico abaixo, note como as curvas referentes aos datasets de treino e validação praticamente estão sobrepostas. Isso é um ótimo indicativo de que não houve problemas de overfitting durante a fase de treinamento.
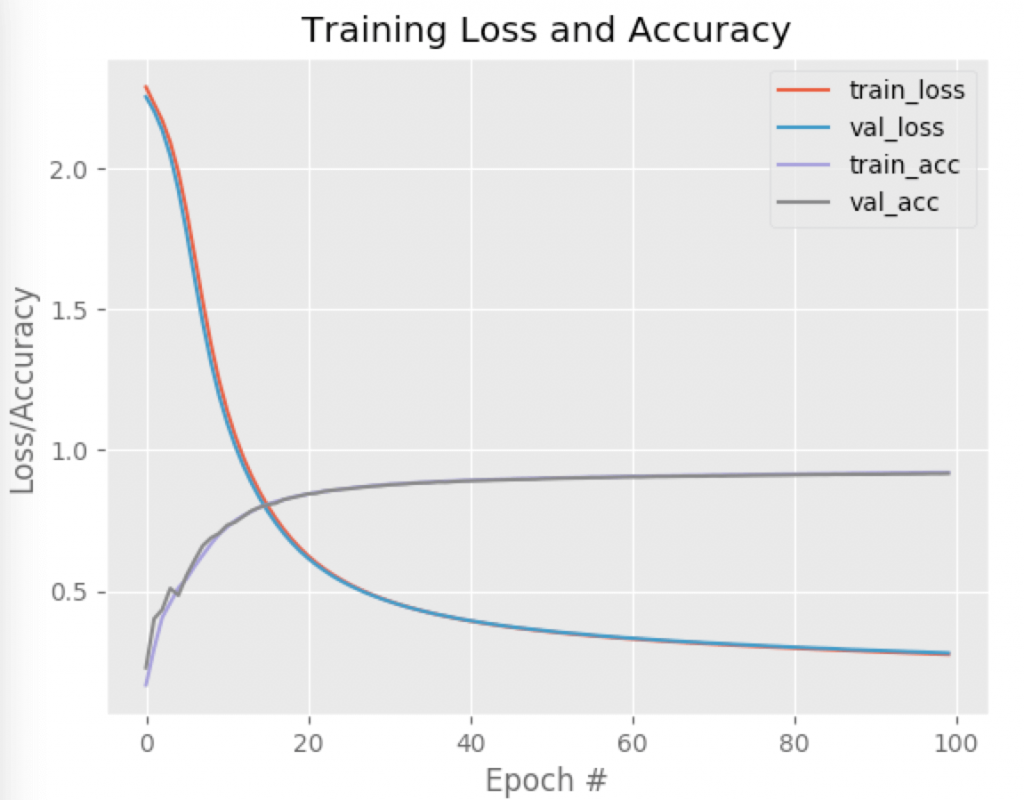
Resumo
Bem, chegando ao final do post, foram apresentados os conceitos básicos sobre Redes Neurais, assim como o conjunto de dados MNIST, muito utilizado para fazer benchmark entre algoritmos.
Ao testar o desempenho de uma rede neural com 4 layers (input+2 hidden layers + output), conseguimos obter 92% de precisão nas previsões realizadas.
A implementação foi feita em cima do Keras, para mostrar que com usando poucas linhas de código é possível construir ótimos modelos de classificação.
Por fim, gostaria de dizer que pretendo produzir artigos não com foco apenas na escrita de código/implementação pura, mas também entrar mais a fundo nos conceitos teóricos e matemáticos por trás de algoritmos e métodos de Machine Learning.
Acredito fortemente que a gente só evolui quando bota a mão na massa e vai a fundo atrás de algo mais. É isso que estou fazendo para mim, e espero poder compartilhar esses aprendizados aqui no blog.




















Muito bom, parabéns. Gosto pastante dessa metodologia do python de ferramentas intuitivas, Porém quando se fala em redes neural tem muito conteúdo, mais eles sempre param aqui. Seria de estema importância um artigo que desmistifica-se isso, como importar uma rede e usar em uma aplicação na pratica. Acampanho seu trabalho, tem me agudado muito, Obrigado.
Muito obrigado pelo comentário! Normalmente abordo esses assuntos mais aprofundados em aulas públicas no YouTube (em lives) ou dentro da Escola de Data Science (https://escola.sigmoidal.ai). Um forte abraço!
Excelente artigo, professor!
Muito obrigado!
Muito obrigado pelo comentário!
Ótimo conteúdo. Queria informar que com a atualização da biblioteca scikit-learn o import fetch_mldata se tornou import fetch_openml, com isso a linha com o comando dataset = fetch_mldata(“MNIST Original”), agora é dataset = fetch_openml(“mnist_784”) e por fim as chaves de H.history.keys() são accuracy e val_accuracy.