Have you ever noticed the precision and rhythmic control in Tiger Woods’ swing in golf? Or the meticulous preparation of Roberto Carlos, adjusting the ball before firing a left-footed cannon in soccer?
Training for any sport requires discipline, dedication, and a lot of repetition. It’s not just about learning the rules or techniques, but refining skills to execute perfect movements.
My old coach at the Air Force Academy used to say, “only repetition, to exhaustion, leads to perfection”.
But to correct a wrong move, I first need to know where I’m going wrong. That’s where high-performance coaches come in, using videos to fine-tune their athletes’ performances.
Example of Pose Estimation during Theo’s training.Inspired by Theo’s judo training, and as a Computer Vision Engineer, I thought: why not create a visual application for high-performance athlete pose estimation?
Welcome to the world of human pose estimation! In this tutorial, you will get to know the MediaPipe library and learn how to detect body joints in images.
What is Pose Estimation?
Imagine teaching a computer to recognize (and understand) human poses, just as a human would. With Human Pose Estimation (HPE), we can achieve just that.
Leveraging the power of machine learning (ML) and computer vision, we can accurately estimate the positions of body joints, such as shoulders, elbows, wrists, hips, knees, and ankles.
In the sports realm, this technology is very relevant in overseeing and improving posture during physical activities, helping both in injury prevention and in enhancing athletic performance.
But that’s just one application possibility. Here are some others, directly sourced from Google Developers’ website.
Applications of Pose Estimation
In terms of physiotherapy, for example, accurate identification of movements and postures plays a crucial role, facilitating the monitoring of patients’ progress and providing instant feedback during the rehabilitation process.
In the entertainment sector, augmented and virtual reality applications benefit greatly from this technology, providing a more natural and intuitive user interaction. Just look at the hype created by the Pokemon Go game, or more recently, by Apple Vision Pro.

Pose estimation techniques also have promising applications in behavioral analysis, surveillance systems, gesture recognition, and human-computer interaction, creating a field of possibilities yet to be explored.
What is MediaPipe?
MediaPipe is an open-source platform maintained by Google, offering a comprehensive set of tools, APIs, and pre-trained models that make building applications for tasks like pose estimation, object detection, facial recognition, and more, easier than ever.
Being cross-platform, you can build pipelines on desktops, servers, iOS, Android, and embed them on devices like Raspberry Pi and Jetson Nano.
MediaPipe Framework
The MediaPipe Framework is a low-level component used for constructing efficient Machine Learning (ML) pipelines on devices. It has foundational concepts such as packages, graphs, and calculators that pass, direct, and process data respectively. Written in C++, Java, and Obj-C, the framework consists of the following APIs:
- Calculator API (C++)
- Graph construction API (Protobuf)
- Graph Execution API (C++, Java, Obj-C)
MediaPipe Solutions
MediaPipe Solutions, on the other hand, is a set of ready-made solutions, open-source code examples based on a TensorFlow model.
These solutions are perfect for developers who want to quickly add ML capabilities to their apps without having to build a pipeline from scratch. Ready-made solutions are available in C++, Python, Javascript, Android, iOS, and Coral. Check out the gallery below for the available solutions.









MediaPipe Practical Project
The MediaPipe Pose models can be divided into three main categories: skeleton-based, contour-based, and volume-based.
- Skeleton-based Model
- Contour-based Model
- Volume-based Model
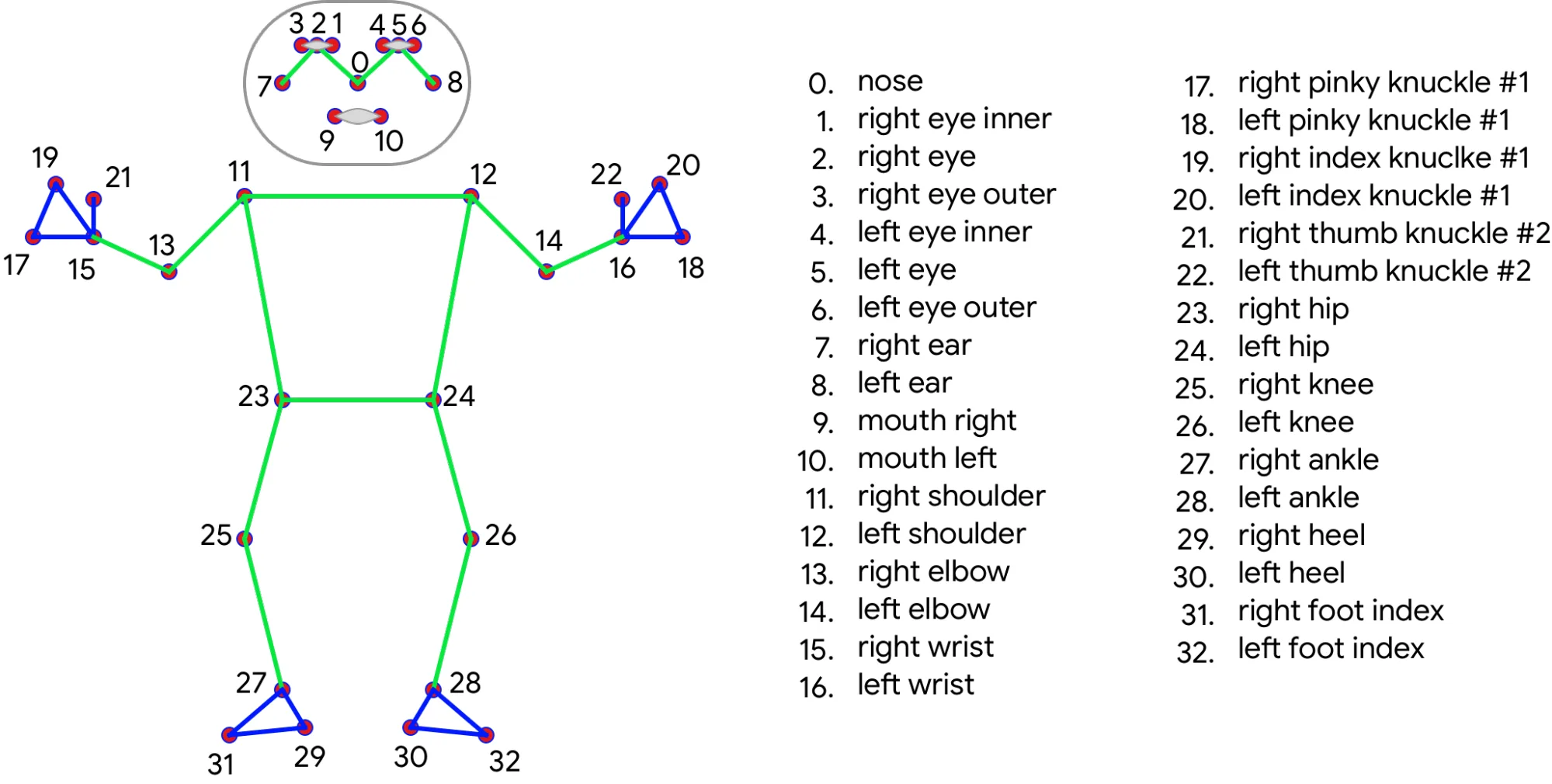
In our context, MediaPipe Pose adopts the skeleton-based approach, utilizing the topology of 33 markers, known as landmarks, derived from BlazePose.
It is also worth noting that, unlike models like YOLOv8 or YOLO-NAS which were structured for detecting multiple people, MediaPipe Pose is a framework aimed at pose estimation for a single person.
Prerequisites
Now, let’s learn in practice how to estimate poses in images using a ready-made MediaPipe model. All materials and code used in this tutorial can be downloaded for free.
The libraries that will be used are OpenCV and MediaPipe. Use the requirements.txt file (provided in the code folder) to proceed.
pip install -r requirements.txt
After executing the code block above, all the necessary dependencies for the project will be conveniently installed.
# required libraries import cv2 import mediapipe as mp import matplotlib.pyplot as plt
First, we import the required libraries. The cv2 library is used for image processing and manipulation, while mediapipe is the Python package that provides the MediaPipe framework for pose estimation. Additionally, we import matplotlib.pyplot to visualize the results later on.
Now that we have imported the required libraries, we can move on to the next steps in our pose estimation pipeline. Python solutions are very straightforward. For the Pose Estimation task, we will follow these steps:
- Detect and draw pose landmarks
- Draw landmark connections
- Get the coordinate pixel of the landmark
Step 1: Detect and draw pose landmarks
In this step, we will identify the key body points, or landmarks, and draw them on our images and videos for a more intuitive visualization.
# Loading the image using OpenCV.
img = cv2.imread("roberto-carlos-the-best-in-the-world.jpg")
# Getting the image's width and height.
img_width = img.shape[1]
img_height = img.shape[0]
# Creating a figure and a set of axes.
fig, ax = plt.subplots(figsize=(10, 10))
ax.axis('off')
ax.imshow(img[...,::-1])
plt.show()
First, the code loads an image using OpenCV’s imread function. The image file, named “roberto-carlos-the-best-in-the-world.jpg” which is located in the file folder, is read and stored in the img variable.
Next, the code retrieves the image’s width and height using the shape attribute of the img array. The width is assigned to the img_width variable and the height to the img_height variable.
After that, a figure and a set of axes are created using plt.subplots. The figsize parameter sets the figure size to 10×10 inches. The line ax.axis('off') removes axis labels and ticks from the graph. Finally, the image is displayed on the axes using ax.imshow, and plt.show() is called to render the graph.
# Initializing the Pose and Drawing modules of MediaPipe. mp_pose = mp.solutions.pose mp_drawing = mp.solutions.drawing_utils
The code initializes two modules from the MediaPipe framework: mp_pose and mp_drawing.
The mp_pose module provides functionality for pose estimation. It contains pretrained models and algorithms that can detect and track human body poses in images or videos. This module is crucial for performing pose estimation tasks using MediaPipe.
The mp_drawing module, on the other hand, provides utilities for drawing the detected poses on images or videos. It offers functions to overlay pose landmarks and connections on visual media, making it easier to view and interpret the pose estimation results.
with mp_pose.Pose(static_image_mode=True) as pose:
"""
This function utilizes the MediaPipe library to detect and draw 'landmarks'
(reference points) on an image. 'Landmarks' are points of interest
that represent various body parts detected in the image.
Args:
static_image_mode: a boolean to inform if the image is static (True) or sequential (False).
"""
# Make a copy of the original image.
annotated_img = img.copy()
# Processes the image.
results = pose.process(img)
# Set the circle radius for drawing the 'landmarks'.
# The radius is scaled as a percentage of the image's height.
circle_radius = int(.007 * img_height)
# Specifies the drawing style for the 'landmarks'.
point_spec = mp_drawing.DrawingSpec(color=(220, 100, 0), thickness=-1, circle_radius=circle_radius)
# Draws the 'landmarks' on the image.
mp_drawing.draw_landmarks(annotated_img,
landmark_list=results.pose_landmarks,
landmark_drawing_spec=point_spec)
Let’s break down this code block and understand how it functions.
The code block begins with a with statement that initializes the mp_pose.Pose class from MediaPipe. This class is responsible for detecting and drawing landmarks (key points) on an image. The static_image_mode argument is set to True to indicate that the image being processed is static.
Next, a copy of the original image is made using img.copy(). This ensures that the original image remains unmodified during the annotation process.
The pose.process() function is then called to process the image and obtain the pose estimation results. The results contain the detected pose landmarks.
The code sets the circle’s radius used to draw the landmarks based on a percentage of the image’s height. This ensures the circle size is proportionate to the image size.
A point_spec object is created using mp_drawing.DrawingSpec to specify the drawing style of the landmarks. It defines the color, thickness, and circle’s radius of the drawn landmarks.
Lastly, mp_drawing.draw_landmarks() is invoked to draw the landmarks on annotated_img using the specified style and the landmarks obtained from the results.
This code block showcases how to use MediaPipe to detect and draw landmarks on an image. It provides a visual representation of the detected pose, enabling us to analyze and interpret the pose estimation results.
Step 2: Draw landmarks connection
In addition to detecting individual landmarks, MediaPipe also allows drawing connections between them, enhancing the understanding of the overall posture.
# Make a copy of the original image. annotated_img = img.copy() # Specifies the drawing style for landmark connections. line_spec = mp_drawing.DrawingSpec(color=(0, 255, 0), thickness=2) # Draws both the landmark points and connections. mp_drawing.draw_landmarks( annotated_img, landmark_list=results.pose_landmarks, connections=mp_pose.POSE_CONNECTIONS, landmark_drawing_spec=point_spec, connection_drawing_spec=line_spec ) First, a copy of the original image is created. Then, the style for drawing connections between landmarks is specified using themp_drawing.DrawingSpecclass, with the color green and a thickness of 2. Afterwards, the functionmp_drawing.draw_landmarksis called to draw both the landmark points and the connections on the annotated image. It receives the annotated image, the pose landmark list from the results object, the predefined connections ofmp_pose.POSE_CONNECTIONS, and the drawing specifications for the landmarks and connections.
Step 3: Get the pixel coordinate of the landmark
Now we can extract the pixel coordinates corresponding to each landmark, allowing for more detailed analysis. These pixel coordinates, when used in conjunction with the connections between landmarks, can be extremely helpful in understanding the position and orientation of various body parts in an image. Moreover, these coordinates can be used to calculate more complex metrics such as the ratio between different body parts, which can be helpful in many applications, such as biomechanical analysis, virtual avatar creation, animation, and more.
# Select the coordinates of the points of interest.
l_knee_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_KNEE].x * img_width)
l_knee_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_KNEE].y * img_height)
l_ankle_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_ANKLE].x * img_width)
l_ankle_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_ANKLE].y * img_height)
l_heel_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_HEEL].x * img_width)
l_heel_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_HEEL].y * img_height)
l_foot_index_x = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_FOOT_INDEX].x * img_width)
l_foot_index_y = int(results.pose_landmarks.landmark[mp_pose.PoseLandmark.LEFT_FOOT_INDEX].y * img_height)
# Print the coordinates on the screen.
print('Left knee coordinates: (', l_knee_x,',',l_knee_y,')' )
print('Left ankle coordinates: (', l_ankle_x,',',l_ankle_y,')' )
print('Left heel coordinates: (', l_heel_x,',',l_heel_y,')' )
print('Left foot index coordinates: (', l_foot_index_x,',',l_foot_index_y,')' )
The above code block highlights the extraction and printing of specific landmark coordinates from the pose estimation results.
Firstly, the code calculates the x and y coordinates of four points of interest (left knee, left ankle, left heel, and left foot index). It should be noted that each landmark has a specific number according to the BlazePose model.
Left knee coordinates: ( 554 , 747 ) Left ankle coordinates: ( 661 , 980 ) Left heel coordinates: ( 671 , 1011 ) Left foot index coordinates: ( 657 , 1054 )
Next, we multiply the normalized positions of the landmarks by the width and height of the image. These coordinates are then printed on the screen using print statements.
# Displaying a graph with the selected points. fig, ax = plt.subplots() ax.imshow(img[:, :, ::-1]) ax.plot([l_knee_x, l_ankle_x, l_heel_x, l_foot_index_x], [l_knee_y, l_ankle_y, l_heel_y, l_foot_index_y], 'ro') plt.show()
Lastly, the four points of interest are plotted on the graph as red points using ax.plot and the graph is displayed using plt.show().
Conclusion
In this tutorial, we explored the concept of pose estimation with MediaPipe. We learned about MediaPipe, a powerful framework for building multimodal perceptual pipelines, and how it can be used for human pose estimation.
We covered the basic concepts of pose estimation in images and discussed how to interpret the output. Specifically, we saw that:
- MediaPipe is a versatile framework for building perceptual pipelines.
- Pose estimation allows us to track and analyze a person’s pose in an image or video.
- MediaPipe’s pose estimation models provide coordinates for various body parts, enabling applications in fields like fitness tracking, augmented reality, and more.
In a future tutorial, I’ll teach you how to apply these concepts to videos to calculate trajectories and angles among certain body parts.











